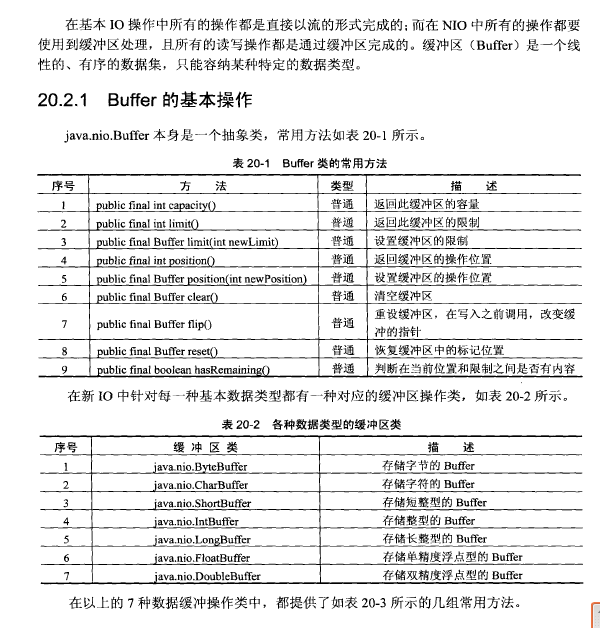
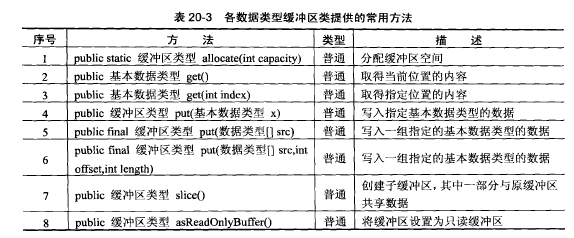
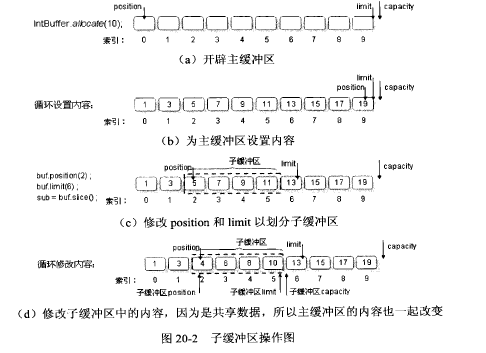
在广告系统当中,ID是标识用户比较重要的手段,
1.安卓端#
AdID:又称为Google advertising ID,海外安卓平台常用的设备标识符,每一台 Android设备都会被分配一个唯一的标识符,海外安卓平台的广告投放归因也主要依赖AdID。在国内,因google play在大陆地区无法使用,故google推动的adid也无法使用。且在android12开始,所有在设备设置中选择退出个性化广告的用户,其广告 ID 会变为一串零 (0),这将会影响android广告的归因。参考:移动广告流量中那些ID的坑 和 Google 宣布移除限制广告跟踪用户的安卓广告 ID
IMEI(International Mobile EquipmentIdentity,移动设备国际识别码,又称为国际移动设备标识),即手机的卡槽号ID,可见这种ID是用户无法关闭或重置的,严格意义上来说在个人信息隐私保护方面存在不合规的高风险,所以采集时要经过用户的授权同意,存储使用时也一定要进行加密处理(MD5摘要加密),匿名化处理。也正是IMEI对个人信息隐私保护方面存在不合规性的高风险,所以从Android Q 开始,IMEI等ID的获取将受到非常大的安全限制,需用户每次授权。故国产手机纷纷开始推广OAID体系。参考:穿山甲——如何获取设备ID
OAID:OAID全称是Open Anonymous Device Identifier,中文名是匿名设备标识符。 OAID是一种非永久性设备标识符,最长64位,在系统首次启动的时候生成。 因此OAID可在保护用户个人数据隐私安全的前提下,用于向用户提供个性化广告,用户统计,同时三方监测平台也可以向广告主提供转化归因分析。支持OAID的条件:1)安卓设备系统版本10及以上; 2)设备品牌:HUAWEI/OPPO/VIVO/XIAOMI
ANID:ANDROID_ID android设备的唯一识别码,在设备首次启动时,系统会随机生成一个64位的数字,并把这个数字以16进制字符串的形式保存下来,这个16进制的字符串就是ANDROID_ID,当设备被wipe后该值会被重置。
2.IOS端#
IDFA:IOS系统下的广告流量主ID相对于Android的情况要好很多了,基本统一使用IDFA(Identifier For Advertising)