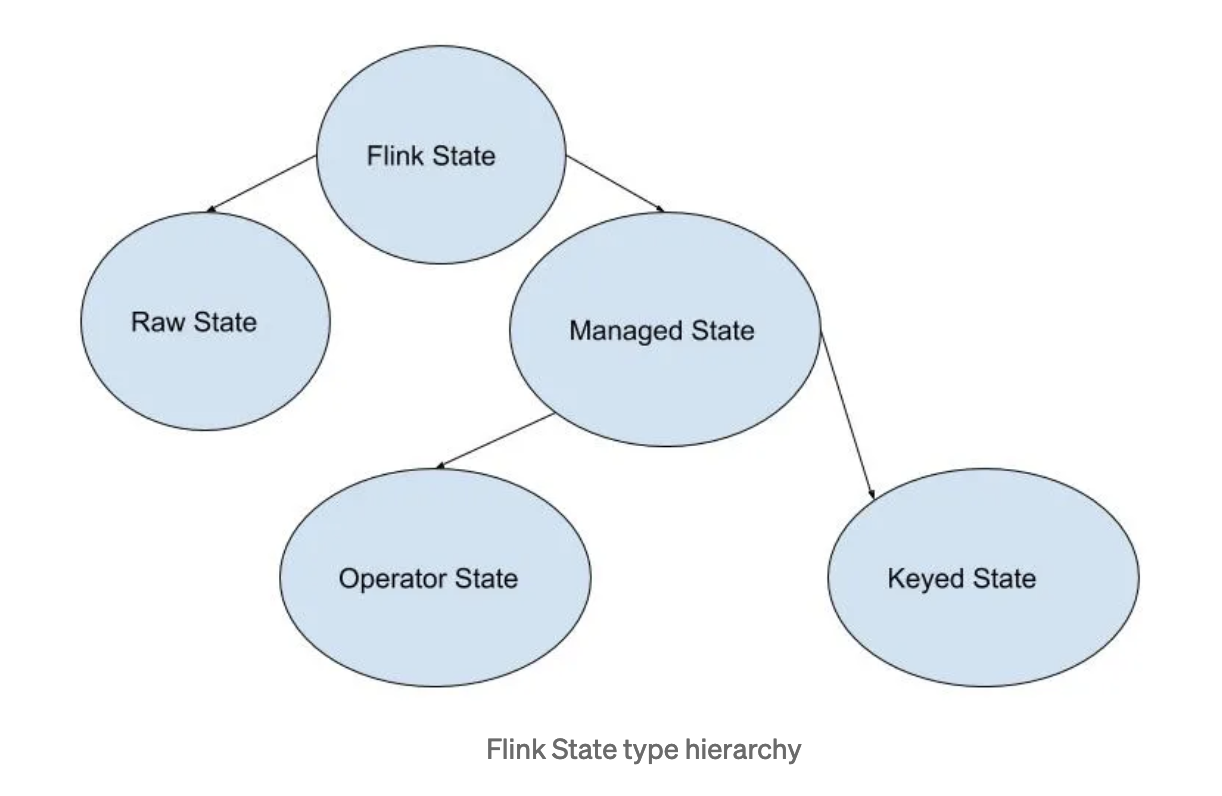
Flink有两种基本类型的状态:托管状态(Managed State)和原生状态(Raw State)。两者的区别:Managed State是由Flink管理的,Flink帮忙存储、恢复和优化,Raw State是开发者自己管理的,需要自己序列化。
| |Managed State|Raw State
Raw State
|状态管理方式| Flink Runtime托管, 自动存储, 自动恢复, 自动伸缩| 用户自己管理
|状态数据结构| Flink提供多种常用数据结构, 例如:ListState, MapState等| 字节数组: byte[]
|使用场景| 绝大数Flink算子| 所有算子
ListState使用案例:使用flink实现一个topN的程序
Managed State又有两种类型:Keyed State和Operator State。
在Flink 中,Keyed State 是绑定到数据流中的特定键(Key)的。 这意味着Flink 维护了数据流中每一个key 的状态。 当处理一个新的元素时,Flink 会将状态的键设置为该元素的键,然后调用对应的处理函数。 Keyed State 的一个典型应用场景是计算每个键的滚动聚合。参考:Flink系列 13. 介绍Flink中的Operator State 和 Keyed State
Operator State可以被所有的operators使用。它通常适用于source,例如FlinkKafkaConsumer。每个operator状态都绑定到一个并行operator实例。Kafka consumer的每个并行实例都维护着一个topic分区和offset的映射,作为它的operator状态。官方文档:https://nightlies.apache.org/flink/flink-docs-release-1.17/docs/dev/datastream/fault-tolerance/state/#operator-state
| |Operator State|Keyed State
Keyed State
|适用算子类型| 可用于所有算子: 常用于source, 例如 FlinkKafkaConsumer|只适用于KeyedStream上的算子
只适用于KeyedStream上的算子
|状态分配|一个算子的子任务对应一个状态|一个Key对应一个State: 一个算子会处理多个Key, 则访问相应的多个State
一个算子的子任务对应一个状态
|创建和访问方式|实现CheckpointedFunction或ListCheckpointed(已经过时)接口|重写RichFunction, 通过里面的RuntimeContext访问
实现CheckpointedFunction或ListCheckpointed(已经过时)接口
|横向扩展|并发改变时有多重重写分配方式可选: 均匀分配和合并后每个得到全量|并发改变, State随着Key在实例间迁移
|支持的数据结构|ListState和BroadCastState |ValueState, ListState,MapState ReduceState, AggregatingState
参考:Apache Flink State Types 和 【Flink】Flink 状态管理
