tonglin0325的个人主页
MySQL学习笔记——undo log和redo log
MySQL的架构可以分成连接层,Server层和存储引擎层。
undo log 和 redo log 是 MySQL InnoDB 存储引擎管理的数据日志类型,它们主要用于支持事务的 ACID 特性,即原子性、一致性、隔离性和持久性。
1.Undo Log(回滚日志)
undo log 用于支持事务的原子性(Atomicity)和隔离性(Isolation)。它在事务发生更改之前记录数据的原始状态,以便在事务回滚时能够将数据恢复到其原始状态。
undo log工作原理:
- 当一个事务对数据库中的数据进行修改(如
INSERT、UPDATE或DELETE操作)时,InnoDB 会先将原始数据的副本写入undo log。 - 如果事务需要回滚(无论是由于用户请求还是由于系统错误),InnoDB 使用
undo log将更改撤销,使数据恢复到事务开始之前的状态。 undo log也用于实现 一致性非锁定读(Consistent Non-Locking Reads),一致性非锁定读 是 MVCC 的核心特性之一。这意味着在事务的隔离级别为 REPEATABLE READ 或 READ COMMITTED 时,可以提供一致的读取视图。它允许事务在读取数据时不加锁,从而避免阻塞其他事务。这种机制依赖于undo log和ReadView,确保在高并发的情况下提供一致的读取视图。
undo log存储位置:
undo log存储在专用的 回滚段(rollback segment) 中,通常位于与数据文件相同的表空间内。
undo log主要用于事务回滚和MVCC(多并发版本控制)。
MVCC工作原理:
- 可重复读(REPEATABLE READ)隔离级别:事务在开始时创建一个
ReadView,并在整个事务期间使用这个ReadView,确保即使有其他事务提交了更改,当前事务的查询结果也保持一致。这样就保证了事务内的多次读取是可重复的。 - 读已提交(READ COMMITTED)隔离级别下:
ReadView是在每次执行查询时生成的,因此一个事务内的不同查询可能看到其他事务已经提交的更改。这样可以保证读取到的是其他事务已提交的数据,但无法保证事务内的多次读取结果一致。当事务执行读取操作时,ReadView会判断数据的每个版本的可见性,这主要取决于版本的 事务 ID(trx_id)
2.Redo Log(重做日志)
redo log 用于支持事务的持久性(Durability)。它记录了已提交的事务对数据库进行的更改,这样在系统崩溃后可以通过redo log来恢复数据。
在redo log记录完成后,事务才算完成。后续,InnoDB 引擎会在适当的时候,由后台线程将缓存在 Buffer Pool 的脏页刷新到磁盘里,这就是 WAL (Write-Ahead Logging)技术。
工作原理:
- 在事务提交之前,所有的更改都会被写入
redo log的日志缓冲区(redo log buffer)。 - 当事务提交时,
redo log缓冲区会刷新到磁盘上的redo log文件。 - 如果数据库崩溃,在重启时,InnoDB 可以使用
redo log来重新应用(重做)日志中的所有更改,以确保所有已提交的事务持久化到数据库中。
存储位置:
redo log存储在专用的日志文件中,InnoDB存储引擎有一个redo log group,由2个文件组成(通常为ib_logfile0和ib_logfile1)中,这些文件位于 InnoDB 的日志目录中。- 重做日志文件组是以**循环写**的方式工作的,从头开始写,写到末尾就又回到开头,相当于一个环形。所以 InnoDB 存储引擎会先写 ib_logfile0 文件,当 ib_logfile0 文件被写满的时候,会切换至 ib_logfile1 文件,当 ib_logfile1 文件也被写满时,会切换回 ib_logfile0 文件。
参考:MySQL 日志:undo log、redo log、binlog 有什么用?
3.两阶段提交(Two-Phase Commit, 2PC)
在 MySQL 中,事务的操作首先写入到 redo log(InnoDB 的物理日志)中,用于崩溃恢复;同时,如果 MySQL 服务器配置了 binlog(二进制日志),事务的变化也需要记录到 binlog 中,作为逻辑日志,用于主从复制和增量备份。
为了确保这两个日志之间的一致性(即要么都成功,要么都失败),MySQL 使用了两阶段提交。如果没有这种机制,在事务提交过程中如果崩溃,可能会出现 redo log 和 binlog 之间的不一致,从而导致数据不一致的情况。
使用postman创建mock server
可以使用postman创建一个mock server用于临时测试API,参考官方文档:Configure and use a Postman mock server
选择Mock servers,点击+号创建一个mock server
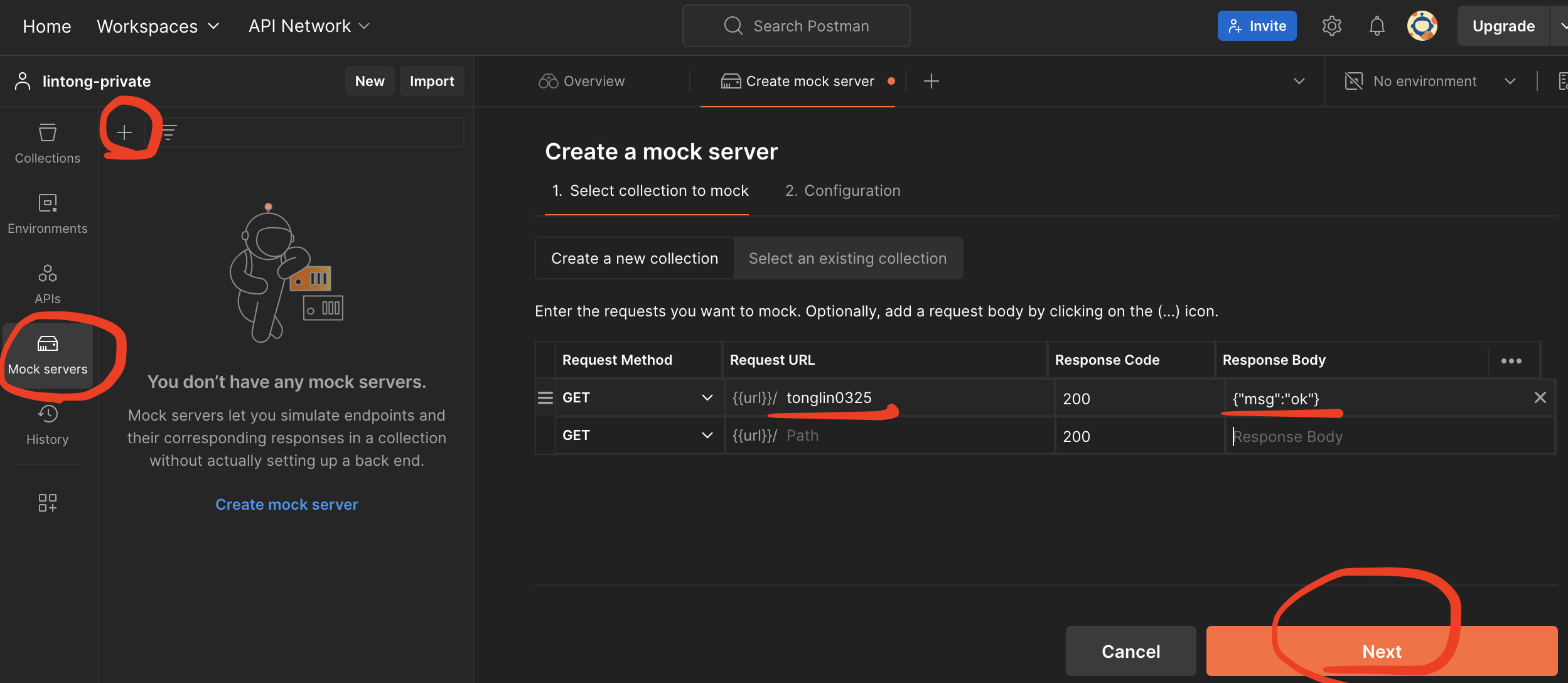
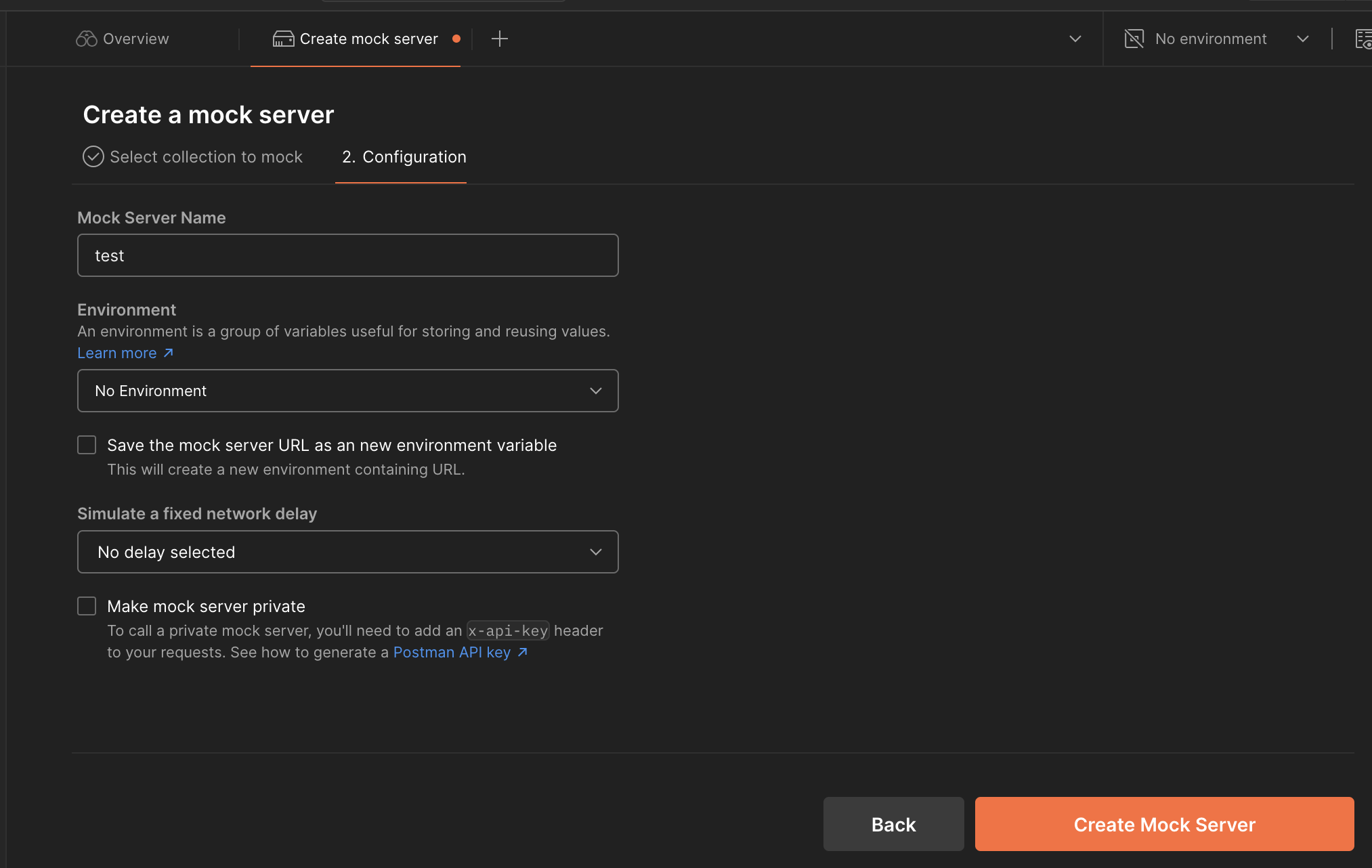
创建
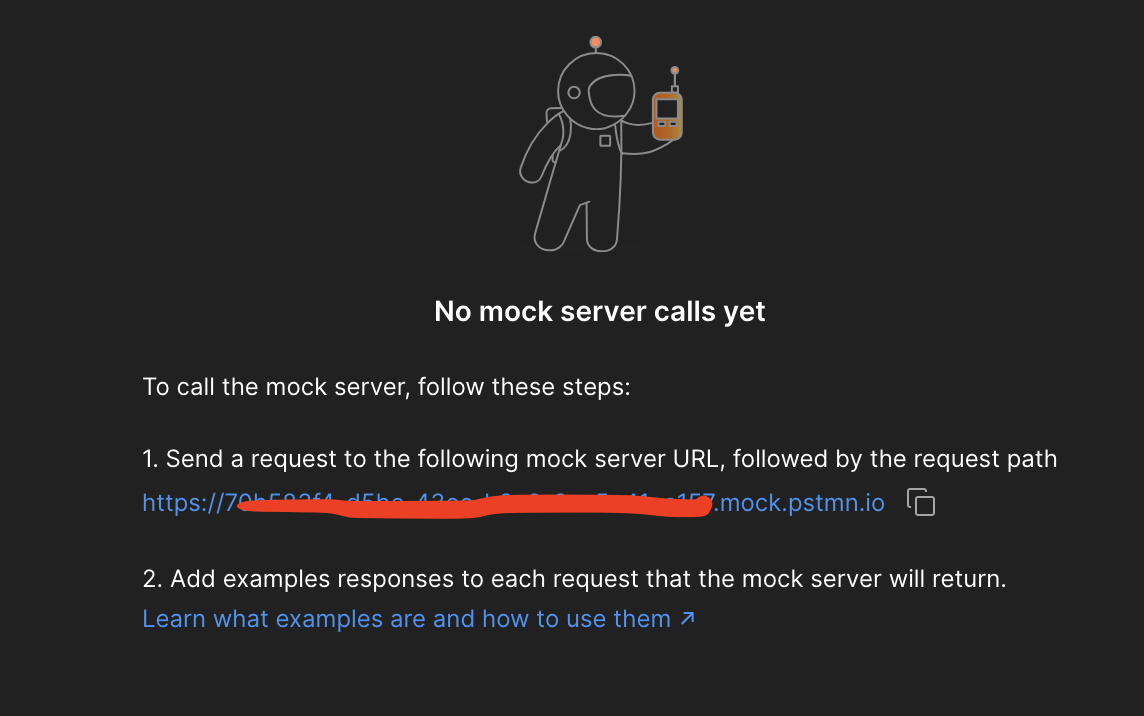
最后会得到一个URL,这就是mock server请求的URL
测试一下
查看postman的logs
Python爬虫——selenium语法
1.获取元素
通过a标签的文本筛选
1 | driver.find_element(By.LINK_TEXT, 'xx').click() |
通过css筛选
1 | driver.find_element(By.CSS_SELECTOR, "input[type='email']").send_keys("xxx") |
通过element name或者css name筛选
1 | driver.find_element(By.NAME, "xx").send_keys("xxx") |
通过xpath筛选,只会contains,starts-with等语法
1 | driver.find_element(By.XPATH, '//a[starts-with(@title, "xx")]').click() |
2.时间筛选器选择时间
可以使用driver.execute_script(js)将元素的readonly属性去掉,再click后clear掉日期,最后send_keys输入新的日期时间
1 | element = driver.find_elements(By.CSS_SELECTOR, "input[class='xxx']") |
parquet-tools使用
使用parquet-tools的方法有2种
1.在安装了CDH的机器上,会自动有parquet-tools命令
1 | lintong@master:/opt/cloudera/parcels/CDH/bin$ ls| grep parquet-tools |
2.自行编辑jar
git clone并指定分支,master分支已经删除了parquet-tools
1 | git clone git@github.com:apache/parquet-mr.git -b apache-parquet-1.10.1 |
编译
1 | cd parquet-tools && mvn clean package -Plocal |
使用avro-protobuf将protobuf转换成avro
avro-protobuf项目提供ProtobufDatumReader类,可以用于从protobuf定义生成的java class中获得avro schema
使用方法如下:
1.引入依赖
1 | <dependency> |
2.定义protobuf schema,名为other.proto,schema如下
1 | syntax = "proto3"; |
从使用protobuf定义生成java class
1 | protoc -I=./ --java_out=./src/main/java ./src/main/proto/other.proto |
3.编写java代码
1 | package com.example.demo; |
Amazon EMR使用指南
Amazon EMR是Amazon提供的托管大数据套件,可选的组件包括Hadoop,Hive,Hue,Hbase,Presto,Spark等
使用Amazon EMR的好处是快速伸缩,版本升级也较为方便,如果配合S3存储,可以做到计算和存储分离,这样对于运维的压力会小一些,存储的稳定性交给S3,计算集群即使故障也可以很方便的进行重建,很适合小团队。缺点是界面友好程度远不如CDH和HDP。
如果使用Amazon EMR,最好阅读一下官方的2个文档:
1.Amazon EMR最佳实践
1 | https://d0.awsstatic.com/whitepapers/aws-amazon-emr-best-practices.pdf |
2.Amazon EMR迁移指南
1 | https://d1.awsstatic.com/whitepapers/amazon_emr_migration_guide.pdf |
1.创建EMR集群
在创建Amazon EMR集群的时候可以选择快速模式,界面如下
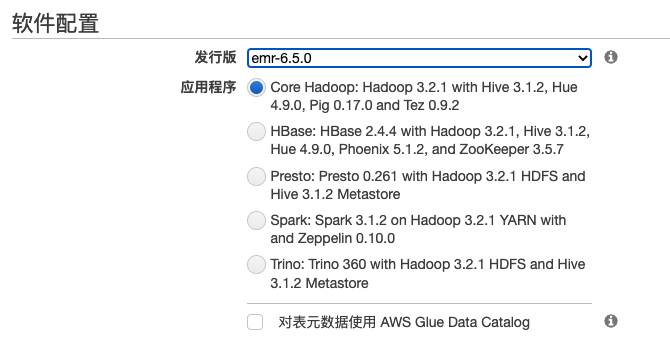
也可以选择高级模式
Grafana学习笔记——filter语法
在使用grafana的filter的时候,其支持一些语法用于对指标进行过滤,如下

literal_or : tagv的过滤规则: 精确匹配多项迭代值,多项迭代值以’|’分隔,大小写敏感
iliteral_or: tagv的过滤规则: 精确匹配多项迭代值,多项迭代值以’|’分隔,忽略大小写
wildcard: tagv的过滤规则: 通配符匹配,大小写敏感
iwildcard: tagv的过滤规则: 通配符匹配,忽略大小写
regexp: tagv的过滤规则: 正则表达式匹配
not_literal_or: tagv的过滤规则: 通配符取非匹配,大小写敏感
not_iliteral_or: tagv的过滤规则: 通配符取非匹配,忽略大小写
HAProxy学习笔记——HAProxy Data Plane API
HAProxy1.9.0及其以上版本支持了Data Plane API功能,可以使用API的方式来管理HAProxy
官方网址
1 | https://github.com/haproxytech/dataplaneapi |
以及
1 | https://ci-jie.github.io/2020/10/25/HAProxy-Data-Plane-API/ |
react学习笔记——基础



tonglin0325
