Amazon EMR是Amazon提供的托管大数据套件,可选的组件包括Hadoop,Hive,Hue,Hbase,Presto,Spark等
使用Amazon EMR的好处是快速伸缩,版本升级也较为方便,如果配合S3存储,可以做到计算和存储分离,这样对于运维的压力会小一些,存储的稳定性交给S3,计算集群即使故障也可以很方便的进行重建,很适合小团队。缺点是界面友好程度远不如CDH和HDP。
如果使用Amazon EMR,最好阅读一下官方的2个文档:
1.Amazon EMR最佳实践
1 | https://d0.awsstatic.com/whitepapers/aws-amazon-emr-best-practices.pdf |
2.Amazon EMR迁移指南
1 | https://d1.awsstatic.com/whitepapers/amazon_emr_migration_guide.pdf |
1.创建EMR集群#
在创建Amazon EMR集群的时候可以选择快速模式,界面如下
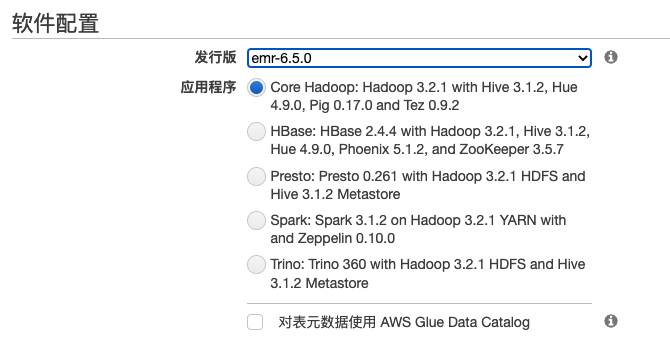
也可以选择高级模式
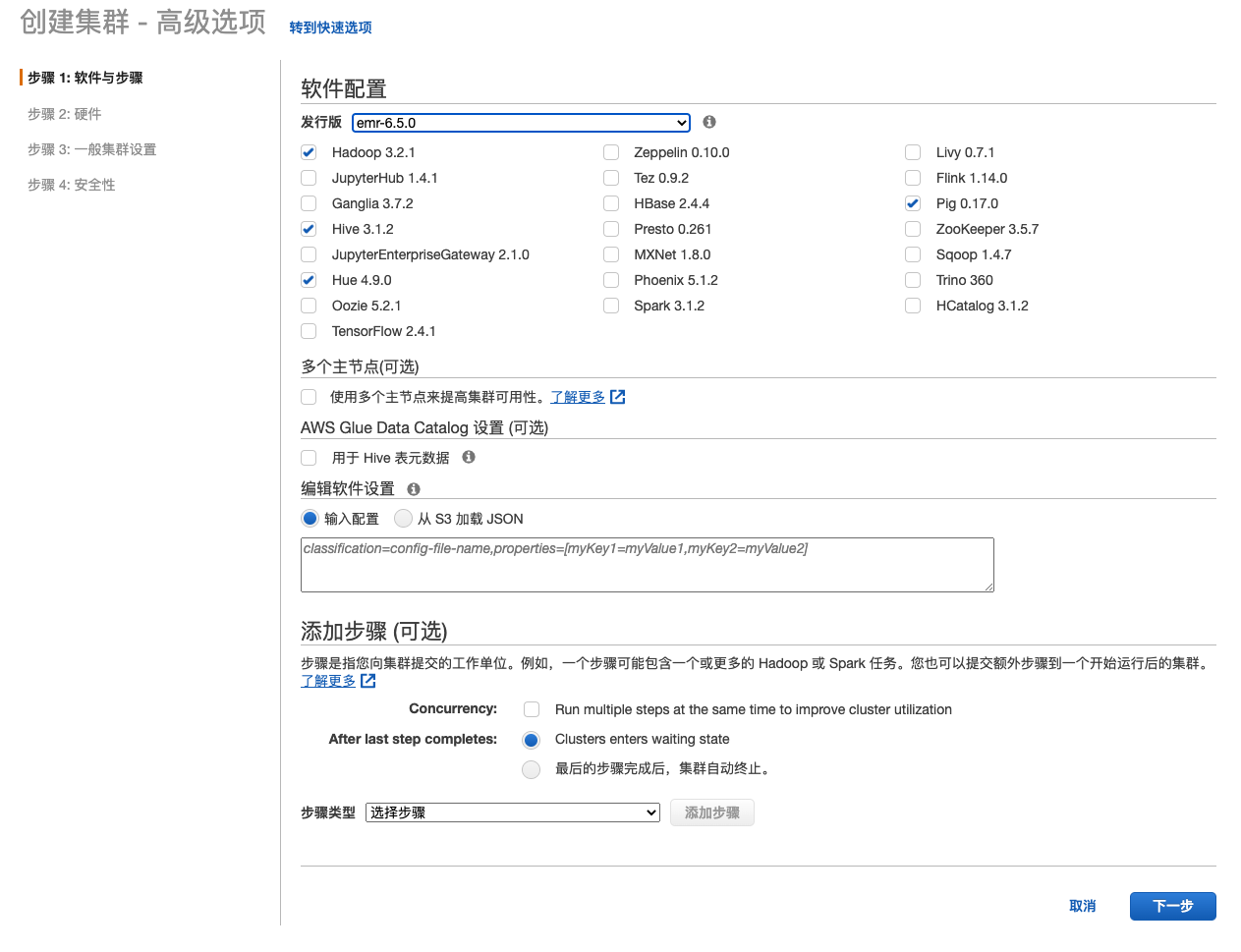
集群启动了之后,EMR大数据组件的安装目录在/usr/lib
1 | [hadoop@ip-xxxxxxxx lib]$ ls |
EMR管理组件的安装目录在/usr/share/aws/emr
1 | [hadoop@ip-xxxxxxxxxx emr]$ ls |
2.EMR CLI使用#
查看集群的cluster id,参考:https://docs.aws.amazon.com/zh_cn/emr/latest/ManagementGuide/emr-manage-view-clusters.html
1 | aws emr list-clusters |
根据cluster id查看集群配置
1 | aws emr describe-cluster --cluster-id j-xxxxxx |
3.EMR角色分布#
amazon EMR的节点分成3类:主节点,核心节点和任务节点
参考:了解节点类型:主节点、核心节点和任务节点 和 部署高可用的EMR集群,为您的业务连续性保驾护航
主节点:
- HDFS Name Node运行在三个主节点中的其中两个。一个为active状态,另一个为 standby状态。当active的Name Node出现故障时,standby的Name Node会变为active并接管所有客户端的操作。EMR会启用一个新的主节点将故障的Name Node替换,并设为standby状态。
- Yarn ResourceManager(RM)运行在所有的三个主节点上。其中,一个RM是active状态,另外两个是standby状态。当active的RM出现故障时,EMR会进行自动故障转移,将其中一个standby节点变为新的active来接管所有操作。之后EMR会将出现故障的master 节点替换,并设为standby状态。
核心节点:
| 节点类型/组件名称 | HDFS Namenode | HDFS SecondaryNamenode | HDFS Datanode | JournalNodes | Zookeeper Server | YARN ResourceManager | YARN NodeManager | YARN JobHistoryServer | presto coordinator | presto worker | HiveServer2 | HiveMetastore | Hive Gateway | Spark Gateway | Spark HistoryServer | HUE Server |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 主节点(高可用部署的时候节点数据为3个)分配任务,不需要 Amazon EC2 实例和很高的处理能力 | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | |||
| 核心节点(处理任务并将数据存储在 HDFS 中)需要处理能力和存储容量 | ✅ | ✅ | ✅ | |||||||||||||
| 任务节点(不存储数据)只需要处理能力 | ✅ | ✅ |
如果在YARN上运行的是flink任务的话,job manager只能运行在core节点上,不能运行在task节点,因为task节点并不会去/var/lib/flink路径下初始化flink相关组件,而task manager可以运行在task节点上
4.EMR配置文件#
在EMR中对配置进行了修改,比如hive-metastore.xml, hive-server2.xml,core-site.xml,对应如何配置以及需要重启的组件可以参考如下表格:https://docs.aws.amazon.com/zh_cn/emr/latest/ReleaseGuide/emr-630-release.html

5.EMR启动步骤#
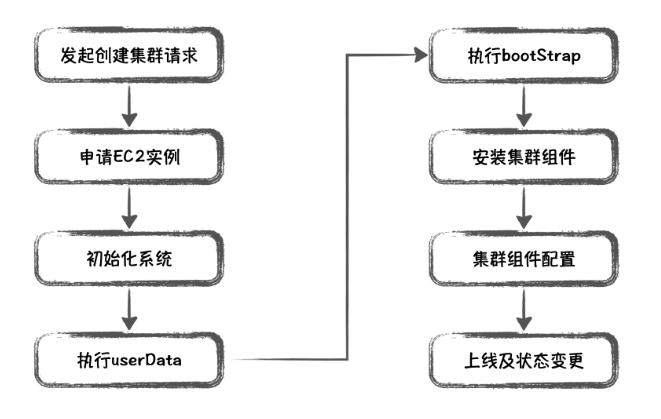
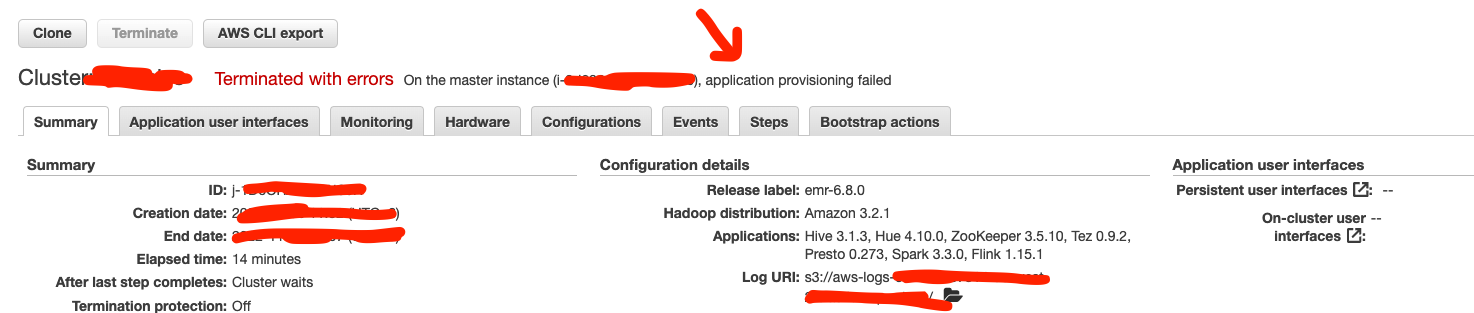
如果EMR集群启动失败的话,可以去Log URI查看日志,Terminated with errors后面会告诉你是哪台实例在哪个步骤的时候报错
6.EMR集群的动态伸缩#
在创建AWS EMR集群的时候,可以选择开启cluster scaling,auto scaling有2种伸缩策略,一种是EMR-manager scaling,另一种是用户自行配置scaling策略来进行扩缩容
注意在只有core节点和task节点是可以进行扩缩容的,master主节点在EMR集群创建后就无法进行变更
1.EMR-manager scaling配置#
这里需要配置的参数主要控制的是core和task节点的扩缩容实例数量,参考:Using managed scaling in Amazon EMR
1 | Minimum 3 (core + task 最小为3台机器) |

在使用了EMR-manager scaling之后,EMR集群的扩容主要由集群容量指标控制,比如 TaskNodesRequested,CoreNodesRequested等,``参考:了解托管扩展指标
这里我们手动将task节点的数量从0点resizing成5个,或者可以往YARN上提交需要较大资源的任务,参考:实验9: EMR AUTO SCALING
可以在cloud watch中的EMR相关指标中看到,TaskNodesRequested从0上升到5个
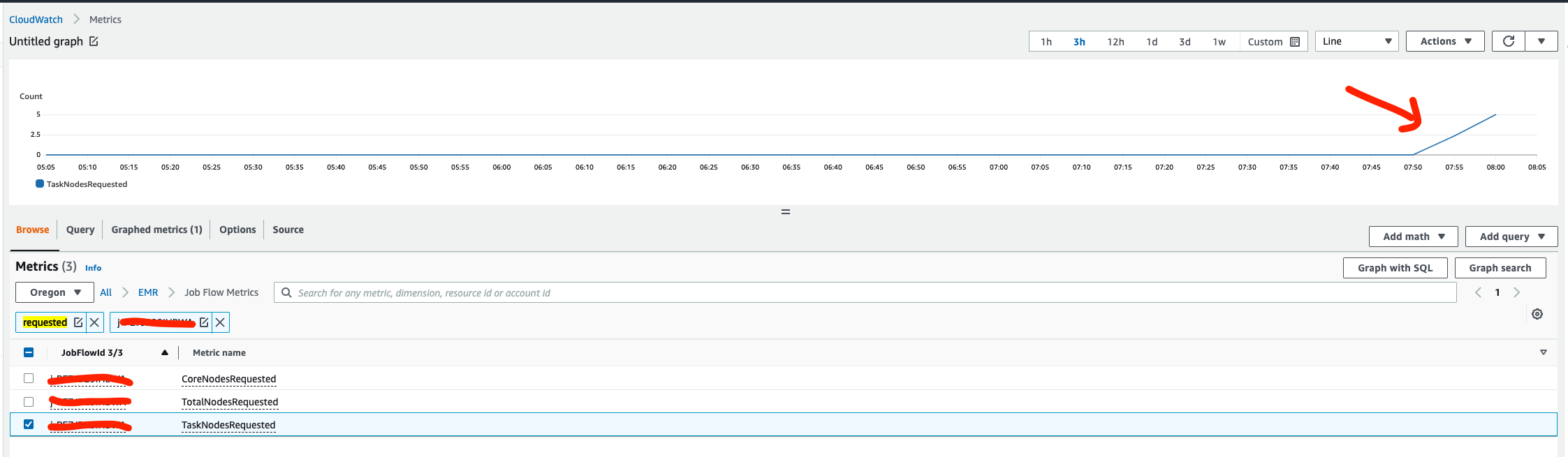
如果实际任务不需要这么多资源,过一小段时间后就会自动缩容
但是实际测试下来,EMR-manager scaling有时候会出现无法扩容的问题,例如我创建了如下扩容策略的EMR集群

这时即使在创建集群时指定了task的instance group,但是因为其中task节点的数量初始为0,所以集群创建后不会有task的instance group,之后也不能进行扩容
然后我使用如下命令创建了一个flink session cluster
1 | /usr/lib/flink/bin/yarn-session.sh -s 1 -jm 10240 -tm 10240 --detached |
但是该flink集群缺无法正常启动,一直提示获取不到足够的资源

在cloudwatch和EMR监控上也看不到任何扩容的请求

所以这里推荐使用用户自行配置scaling策略
参考:Amazon EMR Managed Scaling 介绍——自动调整集群大小,高效节约运营成本
同时EMR托管的扩容只支持YARN应用程序,如 Spark、Hadoop、Hive、Flink;不支持不基于YARN的应用程序,例如 Presto 或 HBase。如果想要对Presto进行扩缩容,只能使用指标来自定义自动扩展,比如查询延迟,CPU使用率,内存使用率以及磁盘I/O等

参考:https://docs.aws.amazon.com/zh_cn/emr/latest/ManagementGuide/emr-scale-on-demand.html
2.用户自行配置scaling策略#
这里配置的扩缩容的节点是Task节点,Core节点由于有HDFS,所以不进行扩缩容

自行编辑扩容策略,这里设置的扩容策略是当AppsPending这个指标大于等于1的时候,扩容2台机器
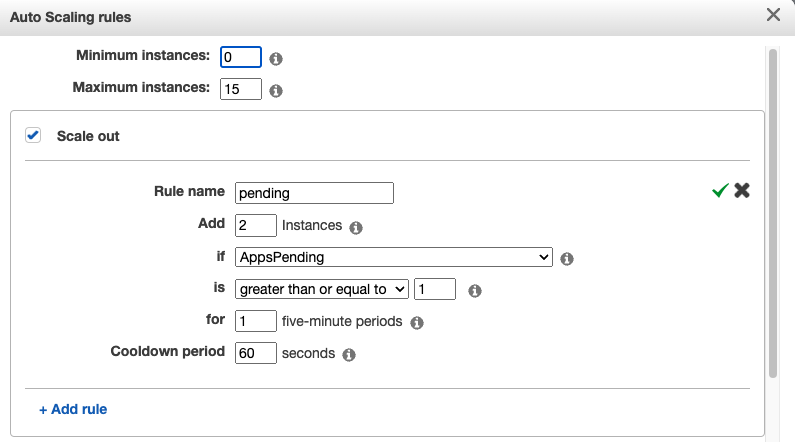
扩缩容可以支持的指标有很多,如下
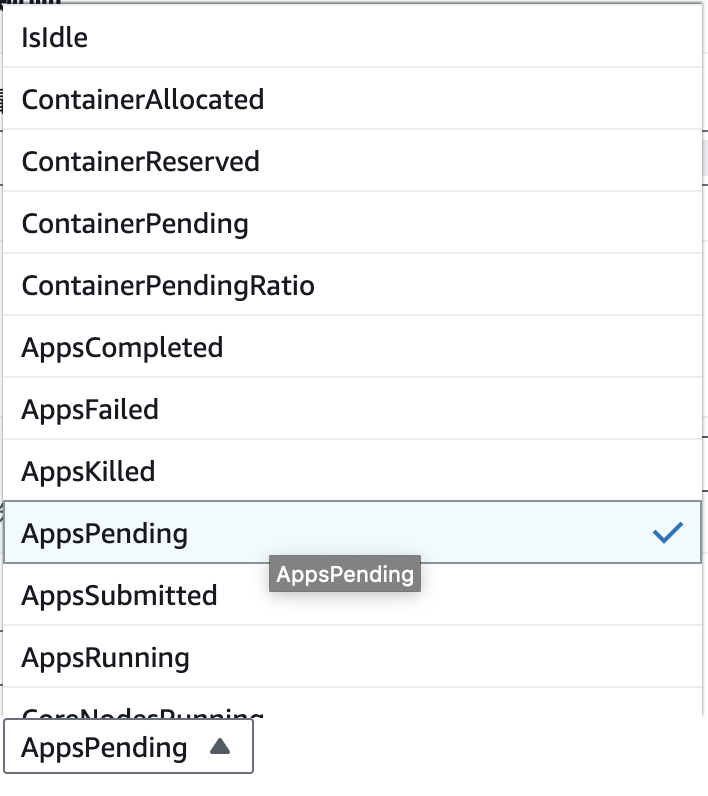
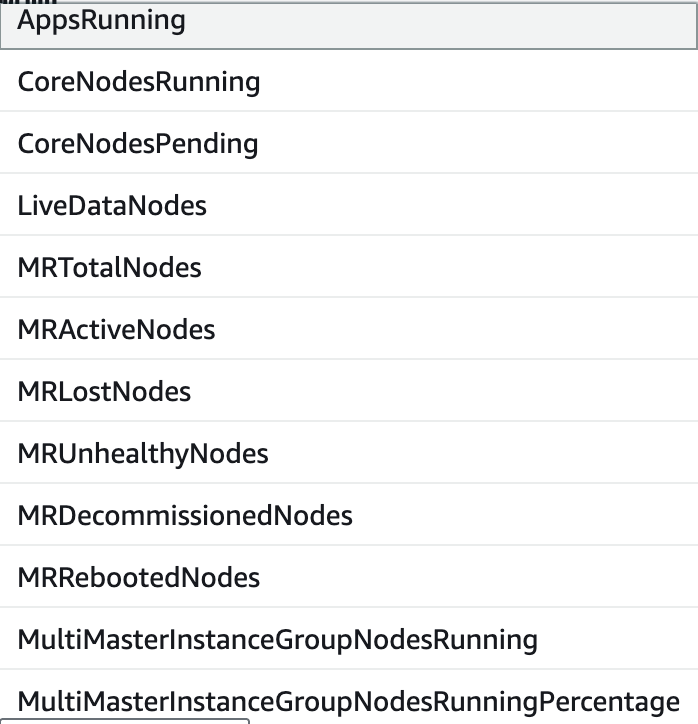
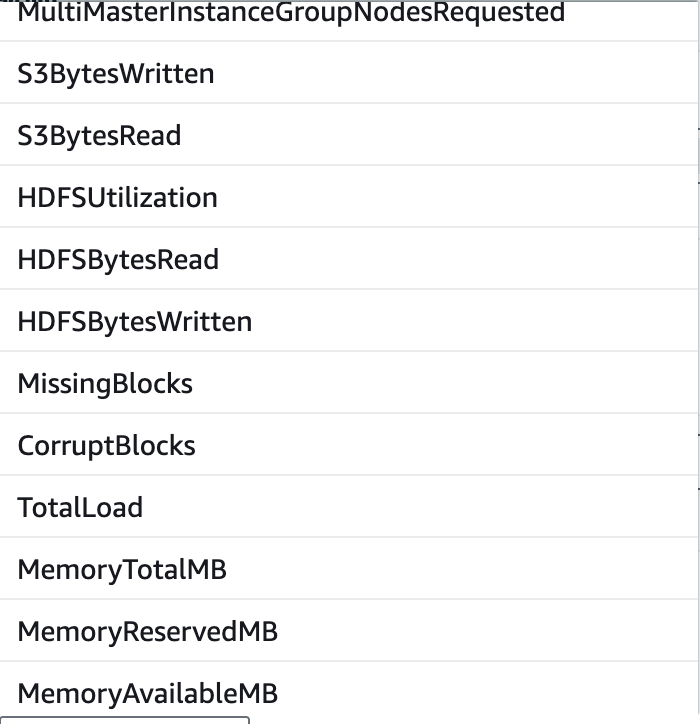
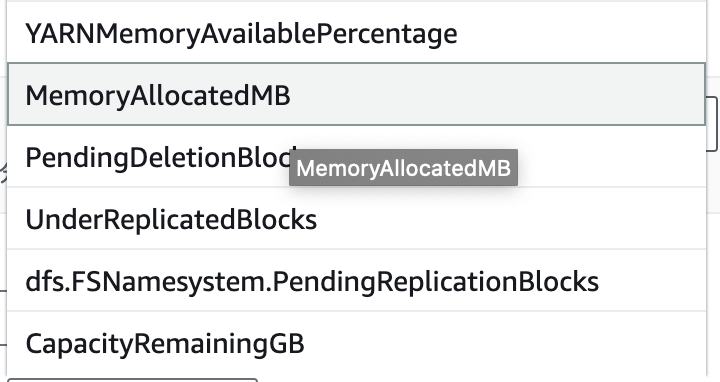
指标分成3类,Cluster Status,Node Status以及IO
