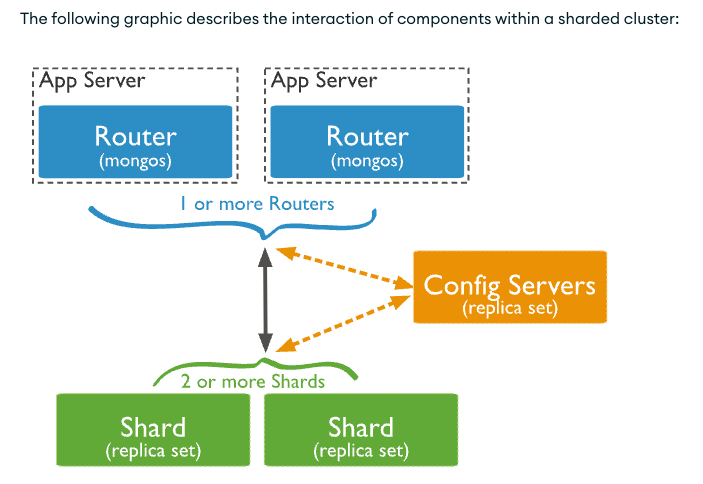
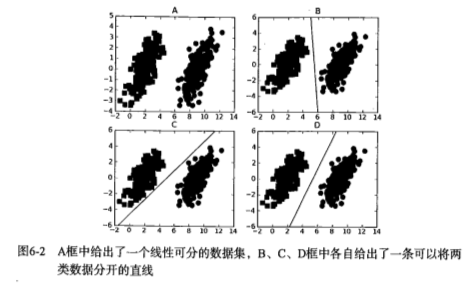
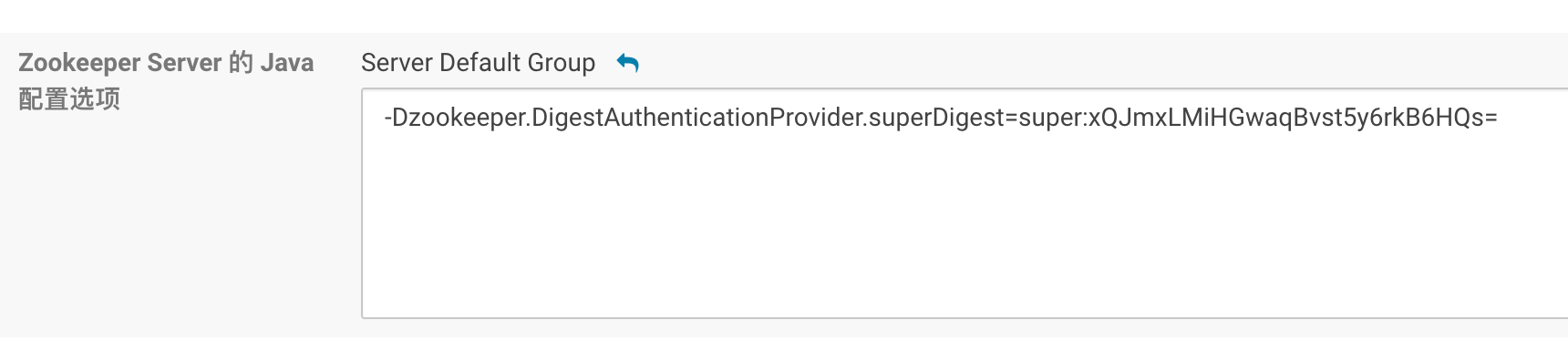
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
| '''#######********************************
以下是没有核函数的版本
'''#######********************************
class optStructK:
def __init__(self,dataMatIn, classLabels, C, toler): # Initialize the structure with the parameters
self.X = dataMatIn
self.labelMat = classLabels
self.C = C
self.tol = toler
self.m = shape(dataMatIn)[0]
self.alphas = mat(zeros((self.m,1)))
self.b = 0
self.eCache = mat(zeros((self.m,2))) #first column is valid flag
def calcEkK(oS, k): #计算误差
fXk = float(multiply(oS.alphas,oS.labelMat).T*(oS.X*oS.X[k,:].T)) + oS.b
Ek = fXk - float(oS.labelMat[k])
return Ek
def selectJK(i, oS, Ei): #用于选择第2个循环(内循环)的alpha值,内循环中的启发式方法
maxK = -1; maxDeltaE = 0; Ej = 0
oS.eCache[i] = [1,Ei] #set valid #choose the alpha that gives the maximum delta E
validEcacheList = nonzero(oS.eCache[:,0].A)[0]
if (len(validEcacheList)) > 1:
for k in validEcacheList: #loop through valid Ecache values and find the one that maximizes delta E
if k == i: continue #跳过本身
Ek = calcEk(oS, k)
deltaE = abs(Ei - Ek)
if (deltaE > maxDeltaE): #选取具有最大步长的j
maxK = k; maxDeltaE = deltaE; Ej = Ek
return maxK, Ej
else: #in this case (first time around) we don't have any valid eCache values
j = selectJrand(i, oS.m)
Ej = calcEk(oS, j)
return j, Ej
def updateEkK(oS, k): #alpha改变后,更新缓存
Ek = calcEk(oS, k)
oS.eCache[k] = [1,Ek]
#内部循环的代码
def innerLK(i, oS):
Ei = calcEk(oS, i)
#判断每一个alpha是否被优化过,如果误差很大,就对该alpha值进行优化,toler是容错率
if ((oS.labelMat[i]*Ei < -oS.tol) and (oS.alphas[i] < oS.C)) or ((oS.labelMat[i]*Ei > oS.tol) and (oS.alphas[i] > 0)):
j,Ej = selectJ(i, oS, Ei) #使用启发式方法选取第2个alpha,选取使得误差最大的alpha
alphaIold = oS.alphas[i].copy(); alphaJold = oS.alphas[j].copy();
#保证alpha在0与C之间
if (oS.labelMat[i] != oS.labelMat[j]): #当y1和y2异号,计算alpha的取值范围
L = max(0, oS.alphas[j] - oS.alphas[i])
H = min(oS.C, oS.C + oS.alphas[j] - oS.alphas[i])
else: #当y1和y2同号,计算alpha的取值范围
L = max(0, oS.alphas[j] + oS.alphas[i] - oS.C)
H = min(oS.C, oS.alphas[j] + oS.alphas[i])
if L==H: print "L==H"; return 0
#eta是alpha[j]的最优修改量,eta=K11+K22-2*K12,也是f(x)的二阶导数,K表示内积
eta = 2.0 * oS.X[i,:]*oS.X[j,:].T - oS.X[i,:]*oS.X[i,:].T - oS.X[j,:]*oS.X[j,:].T
#如果二阶导数-eta <= 0,说明一阶导数没有最小值,就不做任何改变,本次循环结束直接运行下一次for循环
if eta >= 0: print "eta>=0"; return 0
oS.alphas[j] -= oS.labelMat[j]*(Ei - Ej)/eta #利用公式更新alpha[j],alpha2new=alpha2-yj(Ei-Ej)/eta
oS.alphas[j] = clipAlpha(oS.alphas[j],H,L) #判断alpha的范围是否在0和C之间
updateEk(oS, j) #在alpha改变的时候更新Ecache
#如果alphas[j]没有调整,就忽略下面语句,本次循环结束直接运行下一次for循环
if (abs(oS.alphas[j] - alphaJold) < 0.00001): print "j not moving enough"; return 0
oS.alphas[i] += oS.labelMat[j]*oS.labelMat[i]*(alphaJold - oS.alphas[j])#update i by the same amount as j
updateEk(oS, i) #在alpha改变的时候更新Ecache
#已经计算出了alpha,接下来根据模型的公式计算b
b1 = oS.b - Ei- oS.labelMat[i]*(oS.alphas[i]-alphaIold)*oS.X[i,:]*oS.X[i,:].T - oS.labelMat[j]*(oS.alphas[j]-alphaJold)*oS.X[i,:]*oS.X[j,:].T
b2 = oS.b - Ej- oS.labelMat[i]*(oS.alphas[i]-alphaIold)*oS.X[i,:]*oS.X[j,:].T - oS.labelMat[j]*(oS.alphas[j]-alphaJold)*oS.X[j,:]*oS.X[j,:].T
#根据公式确定偏移量b,理论上可选取任意支持向量来求解,但是现实任务中通常使用所有支持向量求解的平均值,这样更加鲁棒
if (0 < oS.alphas[i]) and (oS.C > oS.alphas[i]): oS.b = b1
elif (0 < oS.alphas[j]) and (oS.C > oS.alphas[j]): oS.b = b2
else: oS.b = (b1 + b2)/2.0
return 1 #如果有任意一对alpha发生改变,返回1
else: return 0
#无核函数 Platt SMO 的外循环
def smoPK(dataMatIn, classLabels, C, toler, maxIter): #full Platt SMO
oS = optStruct(mat(dataMatIn),mat(classLabels).transpose(),C,toler)
iter = 0
entireSet = True; alphaPairsChanged = 0
#有alpha改变同时遍历次数小于最大次数,或者需要遍历整个集合
while (iter < maxIter) and ((alphaPairsChanged > 0) or (entireSet)):
alphaPairsChanged = 0
#首先进行完整遍历,过程和简化版的SMO一样
if entireSet: #go over all
for i in range(oS.m):
alphaPairsChanged += innerL(i,oS) #i是第1个alpha的下标
print "fullSet, iter: %d i:%d, pairs changed %d" % (iter,i,alphaPairsChanged)
iter += 1
#非边界遍历,挑选其中alpha值在0和C之间非边界alpha进行优化
else:#go over non-bound (railed) alphas
nonBoundIs = nonzero((oS.alphas.A > 0) * (oS.alphas.A < C))[0] #然后挑选其中值在0和C之间的非边界alpha进行遍历
for i in nonBoundIs:
alphaPairsChanged += innerL(i,oS)
print "non-bound, iter: %d i:%d, pairs changed %d" % (iter,i,alphaPairsChanged)
iter += 1
#如果这次是完整遍历的话,下次不用进行完整遍历
if entireSet: entireSet = False #终止完整循环
elif (alphaPairsChanged == 0): entireSet = True #如果alpha的改变数量为0的话,再次遍历所有的集合一次
print "iteration number: %d" % iter
return oS.b,oS.alphas
|