from numpy import * from time import sleep import time
def loadDataSet(fileName): #逐行解析,得到每行的类标签和整个数据矩阵 dataMat = []; labelMat = [] fr = open(fileName) for line in fr.readlines(): lineArr = line.strip().split('\t') dataMat.append([float(lineArr[0]), float(lineArr[1])]) labelMat.append(float(lineArr[2])) return dataMat,labelMat
#辅助函数,用于在某一区间范围内随机选择一个整数 #i是第一个alpha的下标,m是所有alpha的数目,只要函数值不等于输入值i,函数就会进行随机选择 def selectJrand(i,m): j=i #we want to select any J not equal to i while (j==i): j = int(random.uniform(0,m)) return j
def clipAlpha(aj,H,L): #辅助函数,数值太大或者太小时对其进行调整 if aj > H: aj = H if L > aj: aj = L return aj
#Platt SMO算法中的外循环确定要优化的最佳aplha集合,而简化版却会跳过这一部分 #首先在数据集上遍历每一个alpha,然后在剩下的alpha集合中随机选择另一个alpha,构建alpha对 #简化版SMO算法,数据集,类别标签,常数C,容错率,取消前最大的循环次数 def smoSimple(dataMatIn, classLabels, C, toler, maxIter): dataMatrix = mat(dataMatIn); labelMat = mat(classLabels).transpose() #把列表dataMatIn和classLabels转换成矩阵dataMatrix和labelMat b = 0; m,n = shape(dataMatrix) #初始的b=0,m=100,n=2 alphas = mat(zeros((m,1))) #生成一个100×1的零矩阵 iter = 0 while (iter < maxIter): #在iter小于maxIter的时候循环 alphaPairsChanged = 0 #用于记录alpha是否已经进行优化 for i in range(m): #循环所有数据集,总共有100个 fXi = float(multiply(alphas,labelMat).T*(dataMatrix*dataMatrix[i,:].T)) + b #fXi是预测的类别,i是alpha的下标,把第i个x代入公式计算 Ei = fXi - float(labelMat[i]) #Ei是第i数据向量的计算误差 #判断每一个alpha是否被优化过,如果误差很大,就对该alpha值进行优化,toler是容错率 if ((labelMat[i]*Ei < -toler) and (alphas[i] < C)) or ((labelMat[i]*Ei > toler) and (alphas[i] > 0)): j = selectJrand(i,m) #随机选择另外一个数据向量j print "随机选择的j下标是",j fXj = float(multiply(alphas,labelMat).T*(dataMatrix*dataMatrix[j,:].T)) + b #同时优化这两个向量,如果都不能被优化,退出内循环 Ej = fXj - float(labelMat[j]) #Ej是第j数据向量的计算误差 alphaIold = alphas[i].copy();alphaJold = alphas[j].copy(); #保证alpha在0与C之间 if (labelMat[i] != labelMat[j]): #当y1和y2异号,计算alpha的取值范围 L = max(0, alphas[j] - alphas[i]) H = min(C, C + alphas[j] - alphas[i]) else: #当y1和y2同号,计算alpha的取值范围 L = max(0, alphas[j] + alphas[i] - C) H = min(C, alphas[j] + alphas[i]) #如果L和H相等,就不做任何改变,本次循环结束直接运行下一次for循环 if L==H: print "L==H"; continue #eta是alpha[j]的最优修改量,eta=K11+K22-2*K12,也是f(x)的二阶导数,K表示内积 eta = 2.0 * dataMatrix[i,:]*dataMatrix[j,:].T - dataMatrix[i,:]*dataMatrix[i,:].T - dataMatrix[j,:]*dataMatrix[j,:].T #如果二阶导数-eta <= 0,说明一阶导数没有最小值,就不做任何改变,本次循环结束直接运行下一次for循环 if eta >= 0: print "eta>=0"; continue alphas[j] -= labelMat[j]*(Ei - Ej)/eta #利用公式更新alpha[j],alpha2new=alpha2-yj(Ei-Ej)/eta alphas[j] = clipAlpha(alphas[j],H,L) #再判断一次alpha[j]的范围 #如果alphas[j]没有调整,就忽略下面语句,本次循环结束直接运行下一次for循环 if (abs(alphas[j] - alphaJold) < 0.00001): print "j改变的不够"; continue alphas[i] += labelMat[j]*labelMat[i]*(alphaJold - alphas[j]) #调整alphas[i],修改量与j相同,但是方向相反 #已经计算出了alpha,接下来根据模型的公式计算b b1 = b - Ei- labelMat[i]*(alphas[i]-alphaIold)*dataMatrix[i,:]*dataMatrix[i,:].T - labelMat[j]*(alphas[j]-alphaJold)*dataMatrix[i,:]*dataMatrix[j,:].T b2 = b - Ej- labelMat[i]*(alphas[i]-alphaIold)*dataMatrix[i,:]*dataMatrix[j,:].T - labelMat[j]*(alphas[j]-alphaJold)*dataMatrix[j,:]*dataMatrix[j,:].T #根据公式确定偏移量b,理论上可选取任意支持向量来求解,但是现实任务中通常使用所有支持向量求解的平均值,这样更加鲁棒 if (0 < alphas[i]) and (C > alphas[i]): b = b1 elif (0 < alphas[j]) and (C > alphas[j]): b = b2 else: b = (b1 + b2)/2.0 alphaPairsChanged += 1 print "总共100次迭代的次数: %d 当前i的下标:%d, 成对改变的alpha的数量 %d" % (iter,i,alphaPairsChanged) #print "输出现在的alphas",alphas.T #只有满足alphaPairsChanged为0的条件,即100个alpha的误差都在范围之内,才能进入下一个递归,不然只能在100个alpha再次循环优化 if (alphaPairsChanged == 0): iter += 1 else: iter = 0 print "iteration number: %d" % iter plotBestFit(alphas,dataArr,labelArr,b) return b,alphas
def calcWs(alphas,dataArr,classLabels): X = mat(dataArr); labelMat = mat(classLabels).transpose() m,n = shape(X) w = zeros((n,1)) for i in range(m): w += multiply(alphas[i]*labelMat[i],X[i,:].T) return w
def plotBestFit(alphas,dataArr,labelArr,b): #画出数据集和超平面 import matplotlib.pyplot as plt dataMat,labelMat=loadDataSet('testSet.txt') #数据矩阵和标签向量 dataArr = array(dataMat) #转换成数组 n = shape(dataArr)[0] xcord1 = []; ycord1 = [] #声明两个不同颜色的点的坐标 xcord2 = []; ycord2 = [] for i in range(n): if int(labelMat[i])== 1: xcord1.append(dataArr[i,0]); ycord1.append(dataArr[i,1]) else: xcord2.append(dataArr[i,0]); ycord2.append(dataArr[i,1]) fig = plt.figure() ax = fig.add_subplot(111) ax.scatter(xcord1, ycord1, s=30, c='red') ax.scatter(xcord2, ycord2, s=30, c='green', marker='s') x = arange(2.0, 6.0, 0.1) ws = calcWs(alphas,dataArr,labelArr) #最佳拟合曲线,因为0是两个分类(0和1)的分界处(Sigmoid函数) #图中y表示x2,x表示x1 y = [(i*ws[0]+array(b)[0])/-ws[1] for i in x] ax.plot(x, y) plt.xlabel('X1'); plt.ylabel('X2'); plt.show()


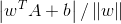
 表示向量的模,
表示向量的模,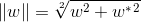 ,w与w共轭的内积再开方
,w与w共轭的内积再开方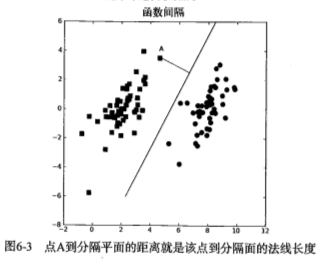
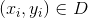 ,
,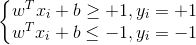

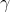 最大,即
最大,即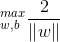 ,
,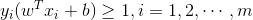 ,其实这个约束条件就是把两个不等式合并成了一个
,其实这个约束条件就是把两个不等式合并成了一个 ,这等价于最小化
,这等价于最小化  ,于是上式可重写为
,于是上式可重写为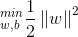 ,
,
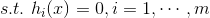
 用一个系数与目标函数f(x)写为一个式子,称为拉格朗日函数,而系数称为拉格朗日乘子。拉格朗日函数的形式如下,u即拉格朗日乘子:
用一个系数与目标函数f(x)写为一个式子,称为拉格朗日函数,而系数称为拉格朗日乘子。拉格朗日函数的形式如下,u即拉格朗日乘子:
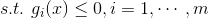

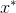 是这个最优点,即此时有
是这个最优点,即此时有
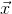 是一个n维向量的话,那么 f(x) 对向量
是一个n维向量的话,那么 f(x) 对向量 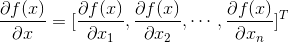
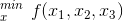

 上寻找函数
上寻找函数  的最小值
的最小值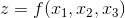 ,当 z 取不同的值的时候,相当于可以投影在曲面
,当 z 取不同的值的时候,相当于可以投影在曲面 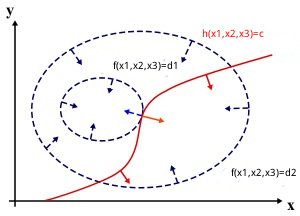
 的时候,在曲面
的时候,在曲面 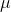 * h(x)的梯度,
* h(x)的梯度, 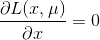 ,最后求得最优解是
,最后求得最优解是  。
。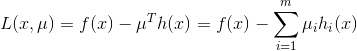 ,
,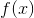 是需要求其最小值的目标函数,
是需要求其最小值的目标函数, 是拉格朗日乘子,
是拉格朗日乘子, 是约束条件
是约束条件 **
**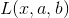 在取得最大值的时候,即a*g(x)=0的时候,就等于f(x),(注意此处的a*g(x)=0是KKT条件的第3个**)
在取得最大值的时候,即a*g(x)=0的时候,就等于f(x),(注意此处的a*g(x)=0是KKT条件的第3个**)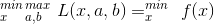

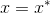 的时候有最优解,此时
的时候有最优解,此时


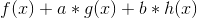 在
在 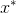 处取得最小值
处取得最小值
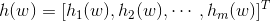 ,
,
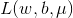 对
对 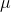 和 b 的偏导等于0,可得
和 b 的偏导等于0,可得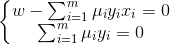
 中,得
中,得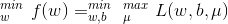 的对偶表达式等于
的对偶表达式等于
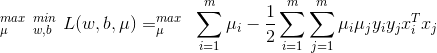
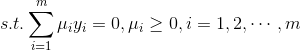
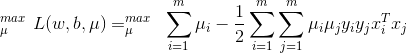
 ,允许出现例外
,允许出现例外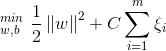 ,其中约束条件为
,其中约束条件为 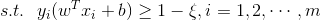
 求偏导的过程,进行简化之后,也是得到
求偏导的过程,进行简化之后,也是得到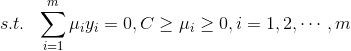

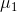 和
和  ,根据约束条件
,根据约束条件  ,即1和2相加,等于3到m相加的负数。
,即1和2相加,等于3到m相加的负数。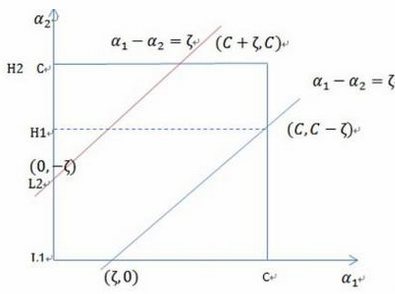
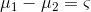 ,那么
,那么 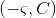 ,即
,即 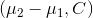
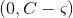 ,即
,即