本文只发表于博客园和tonglin0325的博客,作者:tonglin0325,转载请注明原文链接:
tonglin0325的个人主页
Java关键字
private default protected public的访问控制权限


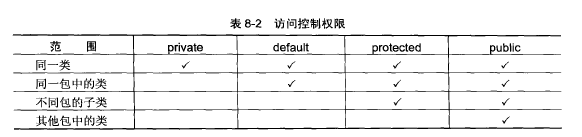
protected范例

transient关键字
当使用Serializable接口实现序列化操作时,如果一个对象中的某一属性不希望被序列化,则可以使用transient关键字进行声明
1 | import java.io.File; |
<3>序列化一组对象
1 | import java.io.File; |
volatile关键字
一旦一个共享变量(类的成员变量、类的静态成员变量)被volatile修饰之后,那么就具备了两层语义:
保证了不同线程对这个变量进行操作时的可见性,即一个线程修改了某个变量的值,这新值对其他线程来说是立即可见的。
SpringBoot学习笔记——校验
JSR-303提供了一些注解,将其放到属性上,可以限制这些属性的值。
参考:Spring MVC学习笔记——JSR303介绍及最佳实践
校验放在DTO层上,不要和数据库交互的model层混用
关于model,VO等的区别,参考:Spring MVC学习笔记——POJO和DispatcherServlet
如何赋值,参考:优雅的使用BeanUtils对List集合的操作
DTO和DO的转换,可以使用BeanUtils,参考:设计之道-controller层的设计
也可以使用ModelMapper,参考:Spring Boot DTO示例:实体到DTO的转换
如果使用的springboot版本大于2.3.x,需要额外引用依赖
1 | <dependency> |
Java多线程
Java进程与线程
进程是程序的一次动态执行过程,它经历了从代码加载、执行到执行完毕的一个完整过程,这个过程也是进程本身从产生、发展到最终消亡的过程。
多进程操作系统能同时运行多个进程(程序),由于CPU具备分时机制,所以每个进程都能循环获得自己的CPU时间片。
多线程是指一个进程在执行过程中可以产生多个线程,这些线程可以同时存在、同时运行,一个进程可能包含了多个同时执行的线程。
比如JVM就是一个操作系统,每当使用java命令执行一个类时,实际上都会启动一个jvm,每一个JVM实际上就是在操作系统中启动一个进程,java本身具备了垃圾回收机制,所以每个java运行时至少会启动两个线程,一个main线程,另外一个是垃圾回收机制。
Java中线程的实现
在Java中要想实现多线程代码有两种手段,一种是继承Thread类,另一种就是实现Runnable接口。
1.继承Thread类
1 | class MyThread extends Thread{ |
输出的结果可能是A线程和B线程交替进行,哪一个线程对象抢到了CPU资源,哪个线程就可以运行,在线程启动时虽然调用的是start()方法,但是实际上调用的却是run()方法的主体
如果一个类通过Thread类来实现,那么只能调用一次start()方法,如果调用多次,则将会抛出”IllegalThreadStateException”异常。



2.实现Runnable接口
仍然要依靠Thread类完成启动,在Thread类中提供了public Thread(Runnable target)和public Thread(Runnable target,String name)两个构造方法。
这两个构造方法都可以接受Runnable的子类实例对象。
1 | class MyThread_1 implements Runnable{ |

通过Thread和Runnable接口都可以实现多线程,其中Thread类也是Runnable接口的子类,但在Thread类中并没有完全地实现Runnable接口中的run()方法。
HBase学习笔记——存储结构
ubuntu删除输入法后,循环登陆
在登陆界面ctrl+alt+F1进入tty界面,登陆账号,然后输入
1 | dpkg -l |grep ^rc|awk '{print $2}' |sudo xargs dpkg -P |
主要就是 sudo chown root:root .Xauthority
应该改成 sudo chown 图形界面的own:图形界面的grp .Xauthority
登陆之后没有中文输入法
首先安装fcitx
sudo apt-get install fcitx libssh2-1到搜狗输入法的首页下载deb的安装文件
然后安装搜狗输入法,双击安装或者sudo dpkg -i XXXX.deb
ElasticSearch学习笔记——Request请求的类型
- TransportNodesListGatewayMetaState.Request
获取各个节点的元信息的请求
2. TransportNodesListGatewayStartedShards.Request
获取started的shard的列表的请求
3. org.elasticsearch.action.admin.cluster.node.stats.NodesStatsRequest
获取节点状态的请求,es默认会每隔30s去检查一遍节点的状态
4. org.elasticsearch.action.admin.indices.stats.IndicesStatsRequest
获取索引状态的请求,es默认会每隔30s去检查一遍index的状态
5. org.elasticsearch.action.search.SearchRequest
search query的请求
HAProxy+Keepalive实现HA
keepalive原理可以参考:Ubuntu安装keepalived
- 首先需要安装keepalived
1 | sudo apt-get install keepalived |
- 编辑 /etc/keepalived/keepalived.conf 配置,参考:16.6 Configuring Simple Virtual IP Address Failover Using Keepalived
master配置
将master的一个网卡的ip绑定到一个虚拟ip上,其中 interface 是绑定的网卡,virtual_ipaddress 是绑定的虚拟ip的地址
1 | global_defs { |
启动
1 | sudo service keepalived start |
Hive学习笔记——在Hive中使用AvroSerde
Hive支持使用avro serde作为序列化的方式,参考:
1 | https://cwiki.apache.org/confluence/display/hive/avroserde |
以及CDH官方的文档
1 | https://docs.cloudera.com/documentation/enterprise/6/6.3/topics/cdh_ig_avro_usage.html |
1.定义avro schema,kst.avsc
1 | { |
将schema文件其放到HDFS上
1 | hadoop fs -ls /user/hive/schema |
2.建Hive表
1 | CREATE TABLE default.kst |
Java抽象类与接口的关系


1.抽象类:
Java可以创建一种类专门用来当做父类,这种类称为“抽象类”。
“抽象类”的作用类似“模板”,其目的是要设计者依据它的格式来修改并创建新的类。但是不能直接由抽象类创建对象,只能通过抽象类派生出新的类,再由它来创建对象。
抽象类的定义及使用规则:
<1>包含一个抽象方法的类必须是抽象类
<2>抽象类和抽象方法都要使用abstract关键字声明
<3>抽象方法只需声明而不需要实现
tonglin0325
