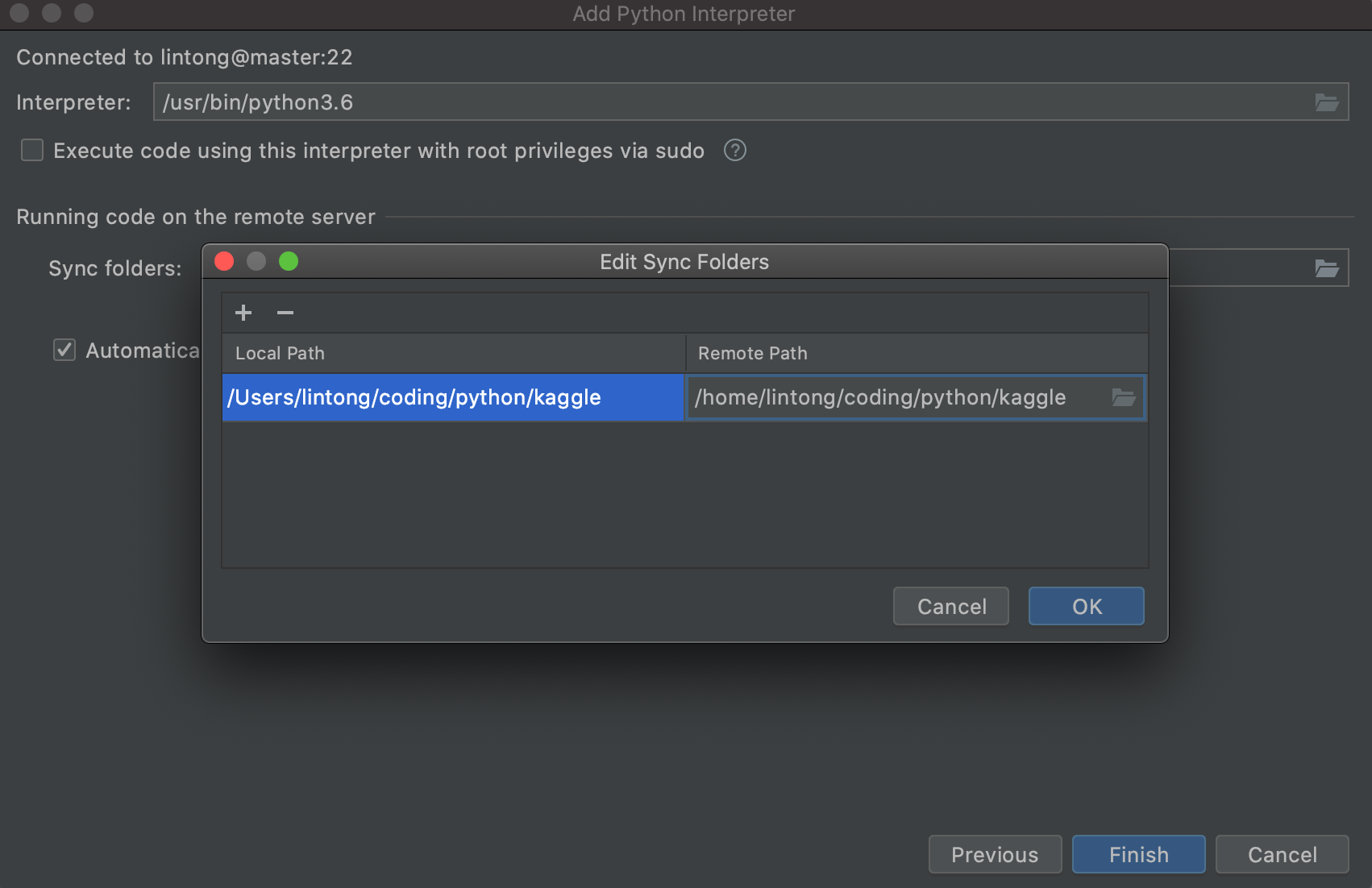
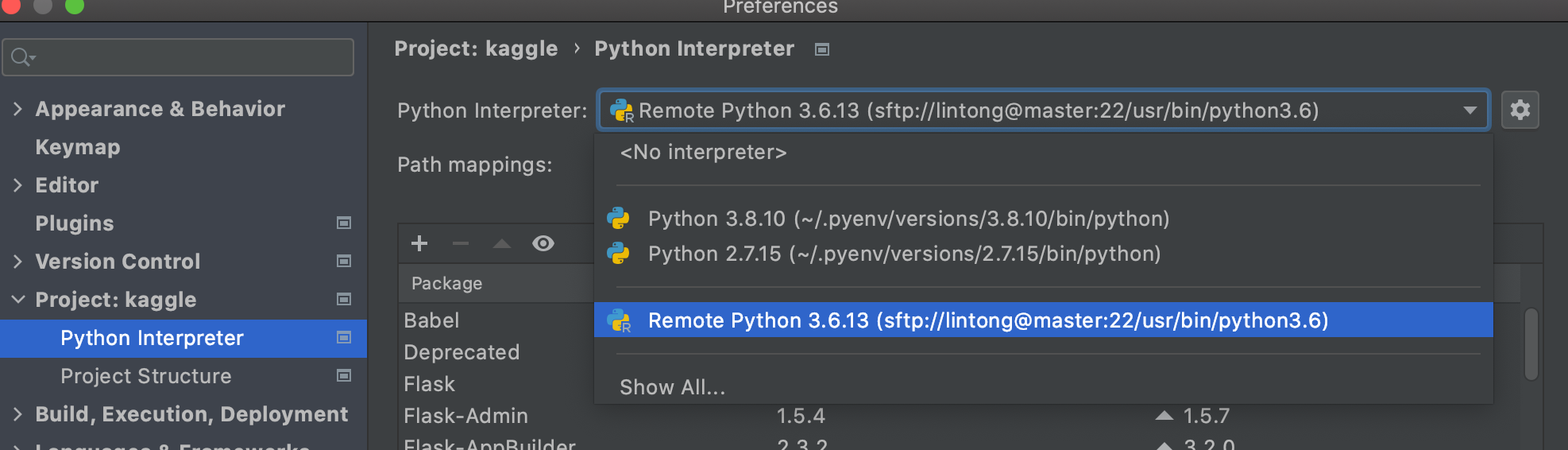
docker ps -a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 3f6822d8f262 confluentinc/cp-schema-registry:latest "/etc/confluent/dock…" 13 minutes ago Up 13 minutes schema-registry
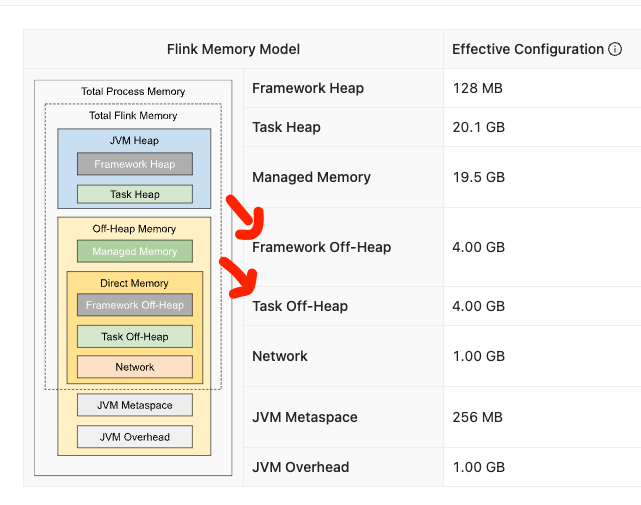
Caused by: java.lang.OutOfMemoryError: Direct buffer memory. The direct out-of-memory error has occurred. This can mean two things: either job(s) require(s) a larger size of JVM direct memory or there is a direct memory leak. <br />The direct memory can be allocated by user code or some of its dependencies. <br />In this case 'taskmanager.memory.task.off-heap.size' configuration option should be increased. Flink framework and its dependencies also consume the direct memory, mostly for network communication. <br />The most of network memory is managed by Flink and should not result in out-of-memory error. In certain special cases, in particular for jobs with high parallelism, the framework may require more direct memory which is not managed by Flink. <br />In this case 'taskmanager.memory.framework.off-heap.size' configuration option should be increased. If the error persists then there is probably a direct memory leak in user code or some of its dependencies which has to be investigated and fixed. The task executor has to be shutdown... at java.nio.Bits.reserveMemory(Bits.java:695) at java.nio.DirectByteBuffer.<init>(DirectByteBuffer.java:123) at java.nio.ByteBuffer.allocateDirect(ByteBuffer.java:311) at sun.nio.ch.Util.getTemporaryDirectBuffer(Util.java:247) at sun.nio.ch.IOUtil.write(IOUtil.java:58) at sun.nio.ch.FileChannelImpl.write(FileChannelImpl.java:211) at java.nio.channels.Channels.writeFullyImpl(Channels.java:78) at java.nio.channels.Channels.writeFully(Channels.java:101) at java.nio.channels.Channels.access$000(Channels.java:61) at java.nio.channels.Channels$1.write(Channels.java:174) at java.io.BufferedOutputStream.write(BufferedOutputStream.java:122) at java.security.DigestOutputStream.write(DigestOutputStream.java:145) at com.amazon.ws.emr.hadoop.fs.s3n.MultipartUploadOutputStream.write(MultipartUploadOutputStream.java:172) at org.apache.hadoop.fs.FSDataOutputStream$PositionCache.write(FSDataOutputStream.java:63) at java.io.DataOutputStream.write(DataOutputStream.java:107) at org.apache.hadoop.fs.FSDataOutputStream$PositionCache.write(FSDataOutputStream.java:63) at java.io.DataOutputStream.write(DataOutputStream.java:107) at org.apache.hudi.common.fs.SizeAwareFSDataOutputStream.lambda$write$0(SizeAwareFSDataOutputStream.java:58) at org.apache.hudi.common.fs.HoodieWrapperFileSystem.executeFuncWithTimeMetrics(HoodieWrapperFileSystem.java:106) at org.apache.hudi.common.fs.HoodieWrapperFileSystem.executeFuncWithTimeAndByteMetrics(HoodieWrapperFileSystem.java:124) at org.apache.hudi.common.fs.SizeAwareFSDataOutputStream.write(SizeAwareFSDataOutputStream.java:55) at org.apache.hadoop.fs.FSDataOutputStream$PositionCache.write(FSDataOutputStream.java:63) at java.io.DataOutputStream.write(DataOutputStream.java:107) at java.io.FilterOutputStream.write(FilterOutputStream.java:97) at org.apache.hudi.common.table.log.HoodieLogFormatWriter.appendBlocks(HoodieLogFormatWriter.java:175) at org.apache.hudi.io.HoodieAppendHandle.appendDataAndDeleteBlocks(HoodieAppendHandle.java:404) at org.apache.hudi.io.HoodieAppendHandle.close(HoodieAppendHandle.java:439) at org.apache.hudi.io.FlinkAppendHandle.close(FlinkAppendHandle.java:99) at org.apache.hudi.execution.ExplicitWriteHandler.closeOpenHandle(ExplicitWriteHandler.java:62) at org.apache.hudi.execution.ExplicitWriteHandler.finish(ExplicitWriteHandler.java:52) at org.apache.hudi.common.util.queue.BoundedInMemoryQueueConsumer.consume(BoundedInMemoryQueueConsumer.java:41) at org.apache.hudi.common.util.queue.BoundedInMemoryExecutor.lambda$null$2(BoundedInMemoryExecutor.java:135) at java.util.concurrent.FutureTask.run(FutureTask.java:266) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) ... 1 more
class Output{ public void output(String name){ int len = name.length(); synchronized(this){ //不能使用name,因为“输出1”和"输出2"两个字符串不是同一个对象 for(int i=0;i<len;i++){ System.out.print(name.charAt(i)); } System.out.println(); } } }
public class Huchi {
private void init(){ final Output outputer = new Output(); //线程1 new Thread(new Runnable(){ @Override public void run() { //覆写Thread类中的run()方法 while(true){ try { Thread.sleep(10); } catch (InterruptedException e) { // TODO 自动生成的 catch 块 e.printStackTrace(); } //new Output().output("输出1"); //也不能new对象,new对象的话,this就不代表同一个对象了 outputer.output("输出1"); } } }).start(); //线程2 new Thread(new Runnable(){ @Override public void run() { //覆写Thread类中的run()方法 while(true){ try { Thread.sleep(10); } catch (InterruptedException e) { // TODO 自动生成的 catch 块 e.printStackTrace(); } //new Output().output("输出1"); //也不能new对象,new对象的话,this就不代表同一个对象了 outputer.output("输出2"); } } }).start(); } public static void main(String[] args) { // TODO 自动生成的方法存根 new Huchi().init(); }