有一些手绘风格的素材库:Architecture diagram components,Decision flow control,System Design Template,Cloud Design Patterns
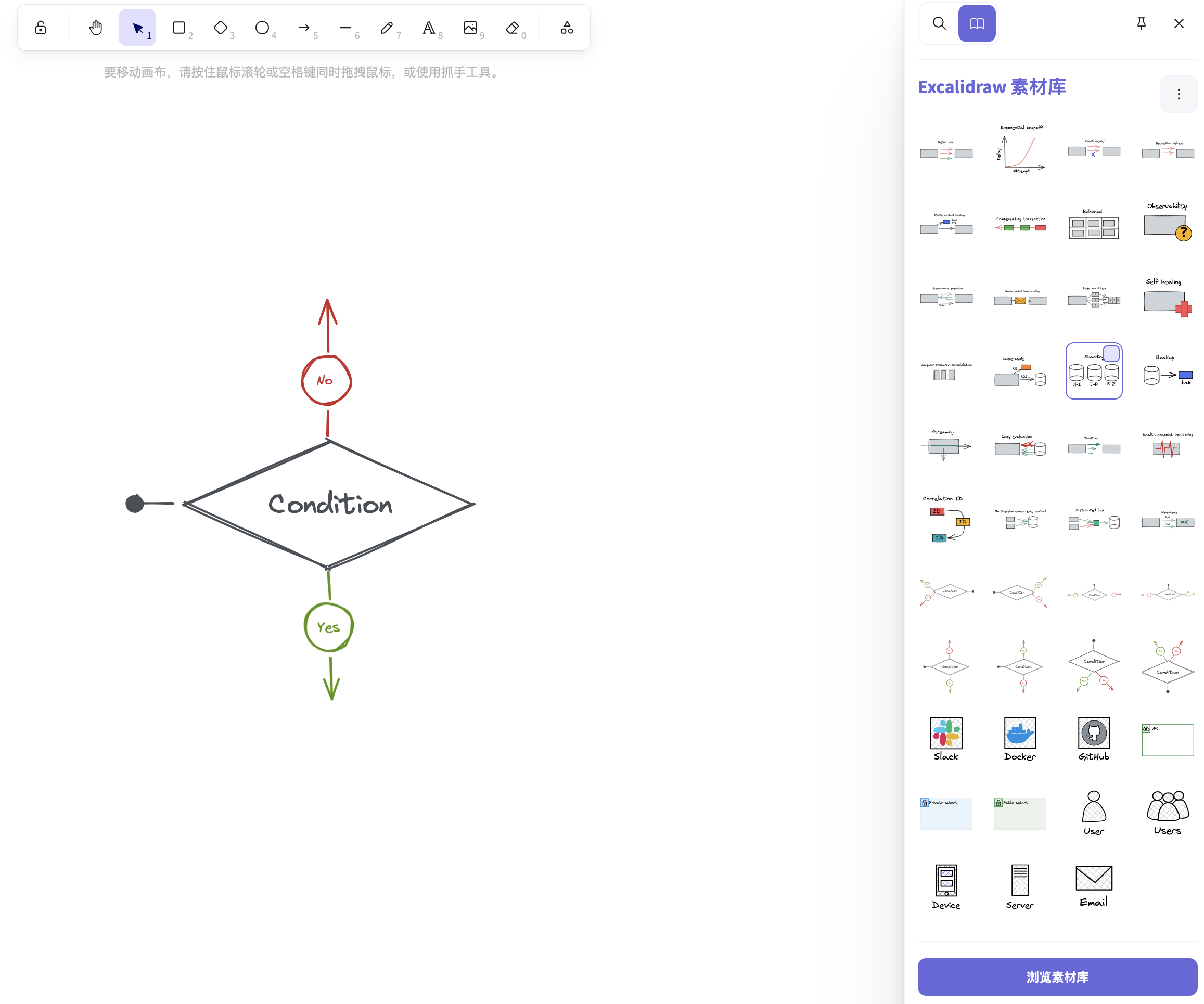
可以用来画趋势图,饼图等
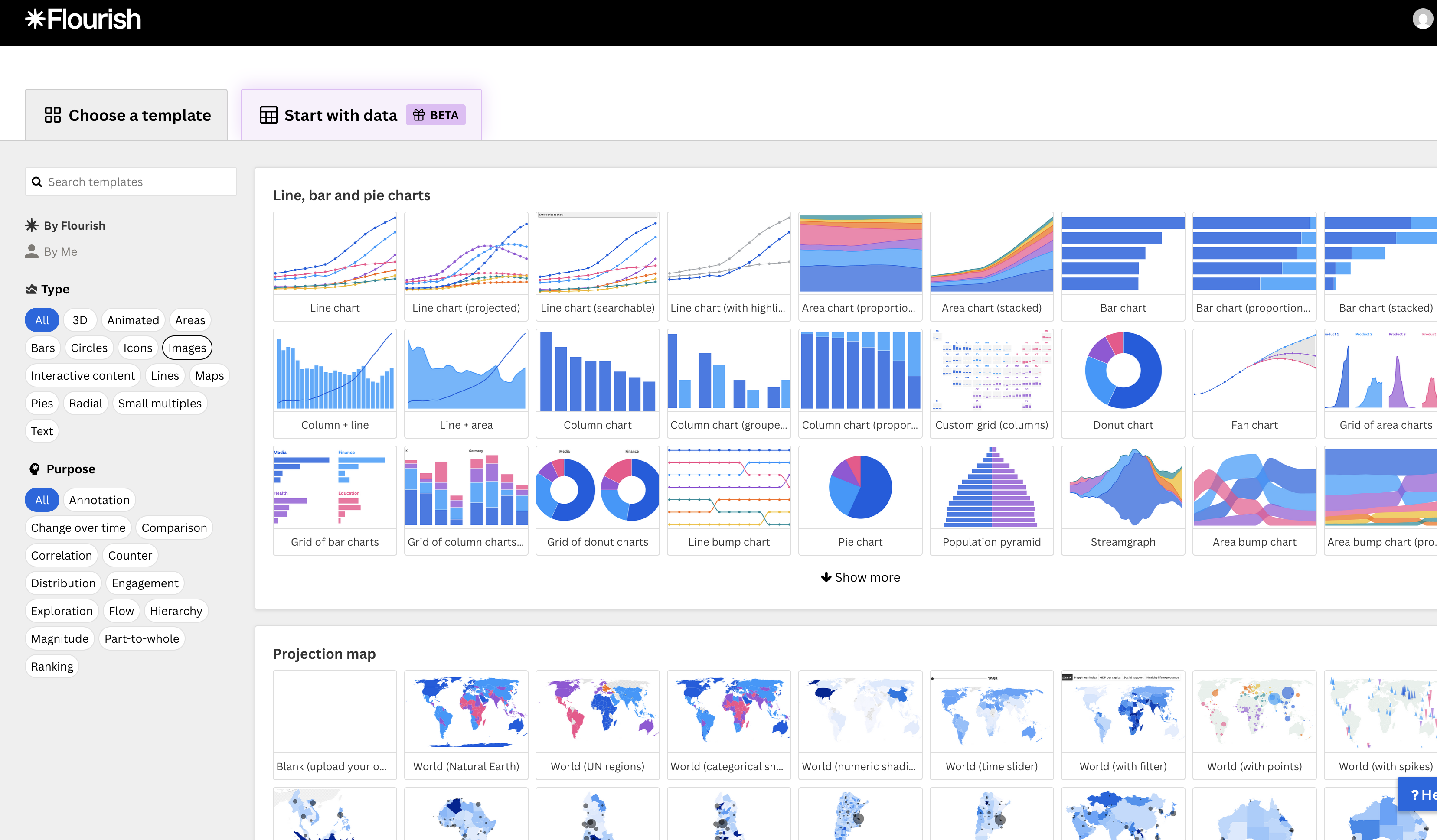
lucidapp是国外一款功能强大的在线作图工具,支持AI画图功能
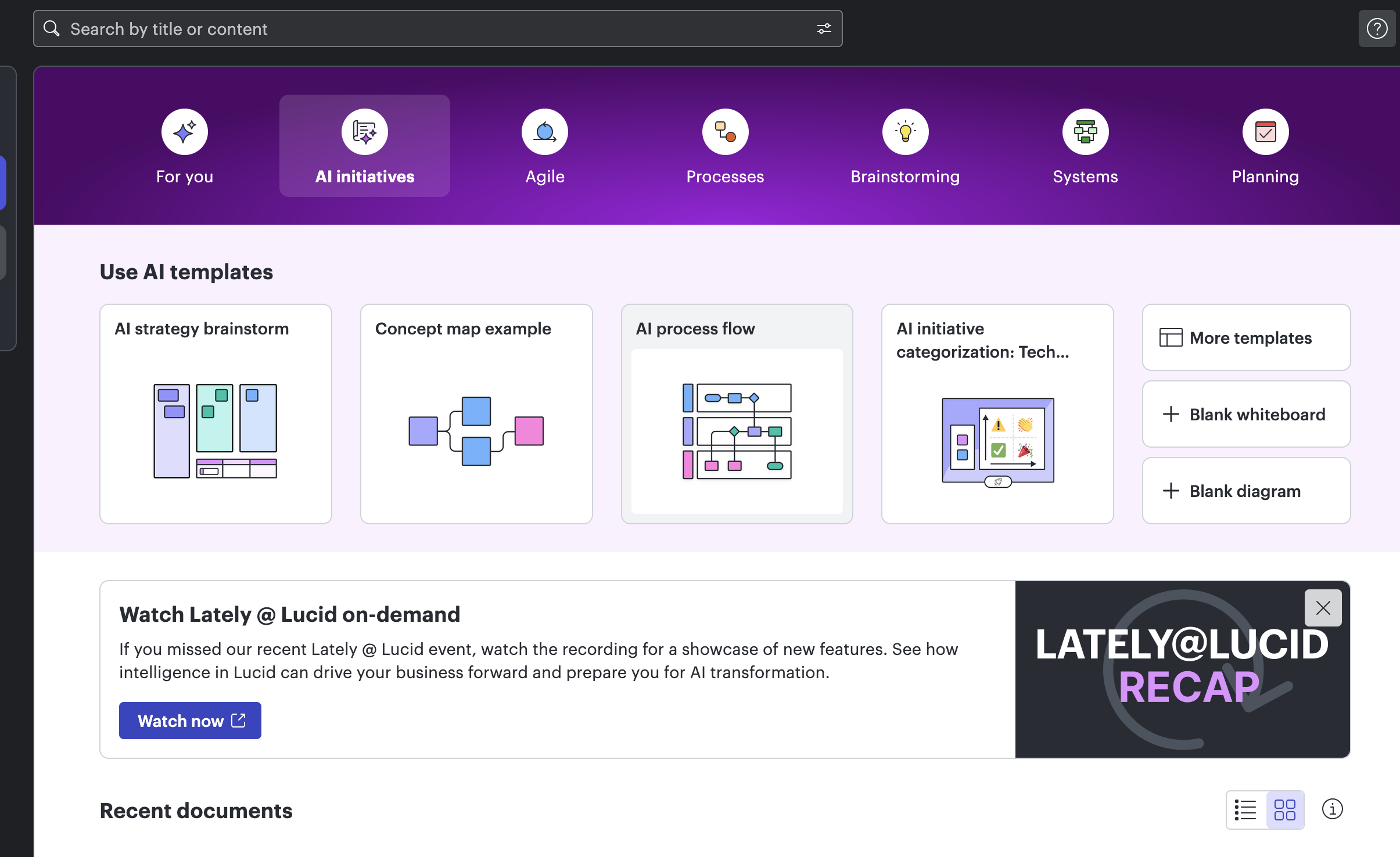
有一些手绘风格的素材库:Architecture diagram components,Decision flow control,System Design Template,Cloud Design Patterns
可以用来画趋势图,饼图等
lucidapp是国外一款功能强大的在线作图工具,支持AI画图功能
官方文档
https://pkg.go.dev/github.com/go-redis/redis/v8#section-readme
添加依赖
1 | go get github.com/go-redis/redis/v8 |
初始化client
1 | client := redis.NewClient(&redis.Options{ |
set key
1 | err = rdb.Set(ctx, "key", 10, time.Hour).Err() |
get key
1 | result := client.Get(ctx, "key") |
特征平台(feature store)的定义:一个用于机器学习的数据管理层,允许共享和发现特征并创建更有效的机器学习管道。
其最早由uber于2017年提出,uber的feature store名为Michaelangelo,参考:Meet Michelangelo: Uber’s Machine Learning Platform
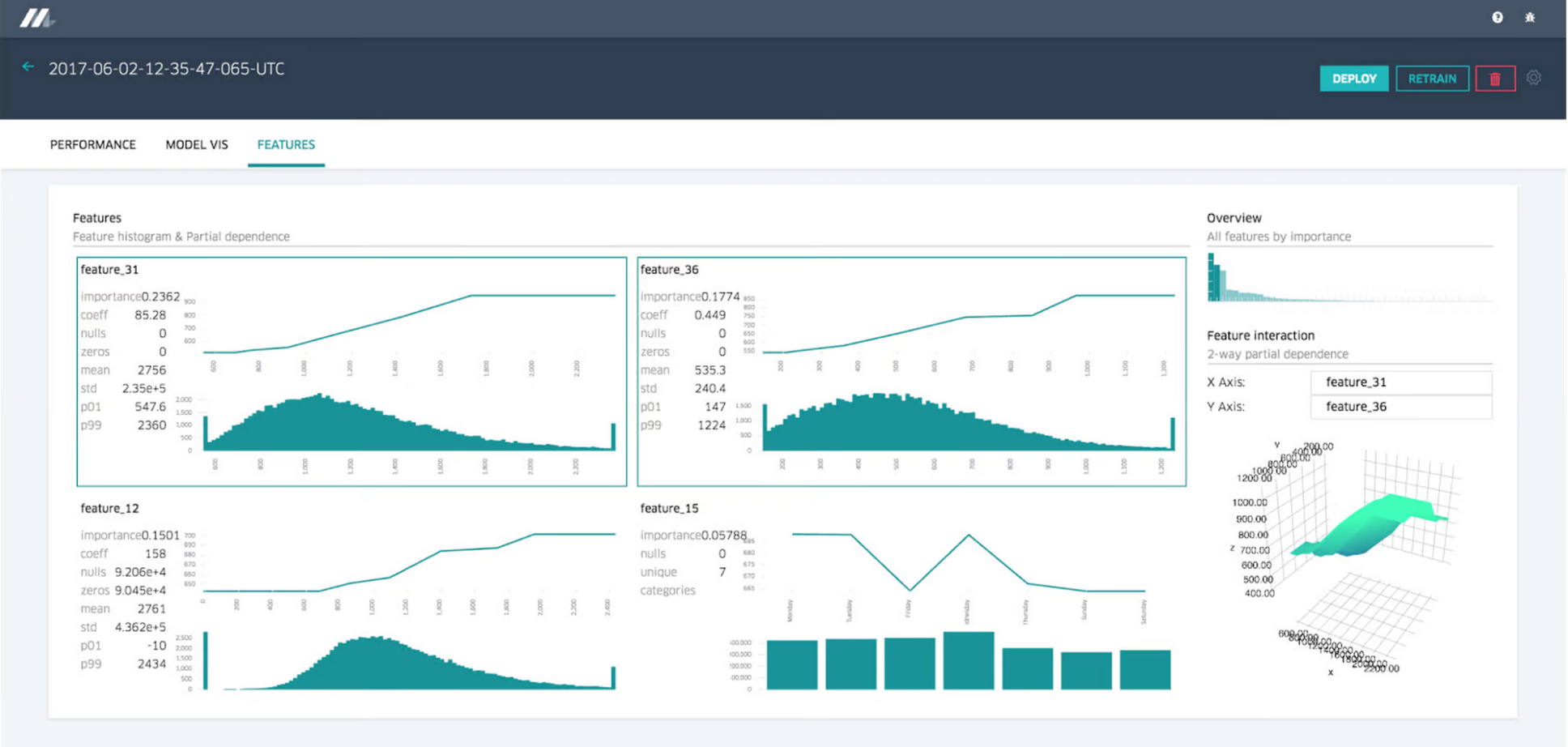
Michaelangelo主要提供以下6种特性,如下图所示:

特征平台所能解决的一些问题:
其他美团的文章:美团配送实时特征平台建设实践
特征存储所解决的一些问题:
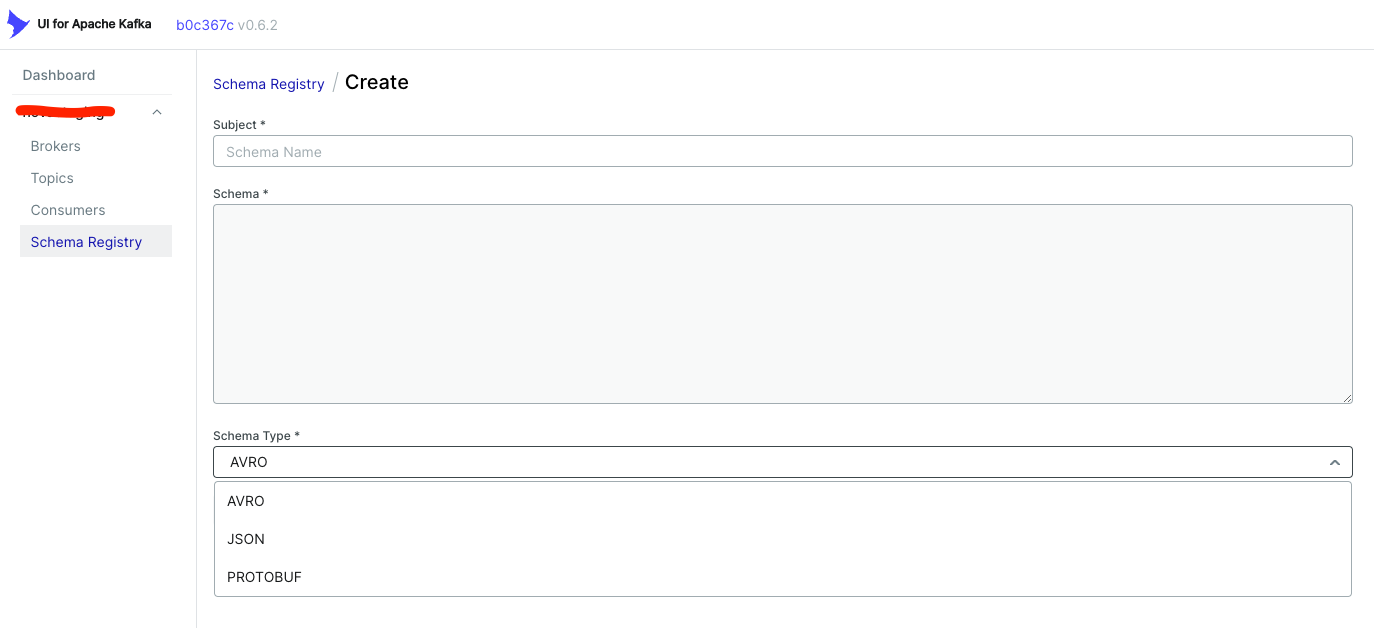
kafka-ui是一个开源的kafka ui工具,支持kafka,schema registry(avro和protobuf都支持),kafka connect,KSQL DB等组件
github项目
1 | https://github.com/provectus/kafka-ui |
docker镜像地址
1 | https://hub.docker.com/r/provectuslabs/kafka-ui |
注意:该kafka-ui只支持2.x.x版本的kafka,对于低版本的kafka不支持,参考issue:https://github.com/provectus/kafka-ui/issues/2097
界面如下

其中schema registry的schema类型支持AVRO,JSON和PROTOBUF
官方下载地址
1 | https://go.dev/dl/ |
1.下载pkg版本的安装包,直接双击安装,比如
1 | https://go.dev/dl/go1.20.12.darwin-amd64.pkg |
这时默认的GOPATH路径(go依赖的下载路径)在~/go
2.也可以下载tar的压缩包进行安装
下载mac对应的安装版,intel版本的mac下载x86版本
1 | https://go.dev/dl/go1.20.12.darwin-amd64.tar.gz |
解压到/usr/local目录
1 | sudo tar -xzvf go1.20.12.darwin-amd64.tar.gz -C /usr/local |
redis共有5种基本数据类型:
String(可以是字符串,整数或者浮点数)、
Hash(哈希,Redis hash 是一个 string 类型的 field(字段) 和 value(值) 的映射表,hash 特别适合用于存储对象。Redis 中每个 hash 可以存储 232 - 1 键值对(40多亿))、
Redis Hash 类型底层有两种编码格式:ziplist、hashtable,当哈希对象同时满足以下两种条件时,对象使用 ziplist 编码;不能满足则使用 hashtable 编码。
这里是可以由使用者自定义进行控制的,redis提供了这么几个参数:
hash-max-ziplist-value 64 // ziplist中最大能存放的值长度
hash-max-ziplist-entries 512 // ziplist中最多能存放的
List(列表)、
Set(集合)、
Zset(有序集合)
随着 Redis 版本的更新,后面又支持了四种数据类型: BitMap(2.2 版新增)、HyperLogLog(2.8 版新增)、GEO(3.2 版新增)、Stream(5.0 版新增)。
在多个应用之间共享数据
热点数据缓存
只有redis的key不存在的时候,才能获得这个锁
JSR 303 – Bean Validation 是一个数据验证的规范,2009 年 11 月确定最终方案。2009 年 12 月 Java EE 6 发布,Bean Validation 作为一个重要特性被包含其中。本文将对 Bean Validation 的主要功能进行介绍,并通过一些示例来演示如何在 Java 开发过程正确的使用 Bean Validation。
在任何时候,当你要处理一个应用程序的业务逻辑,数据校验是你必须要考虑和面对的事情。应用程序必须通过某种手段来确保输入进来的数据从语 义上来讲是正确的。在通常的情况下,应用程序是分层的,不同的层由不同的开发人员来完成。很多时候同样的数据验证逻辑会出现在不同的层,这样就会导致代码 冗余和一些管理的问题,比如说语义的一致性等。为了避免这样的情况发生,最好是将验证逻辑与相应的域模型进行绑定。
Bean Validation 为 JavaBean 验证定义了相应的元数据模型和 API。缺省的元数据是 Java Annotations,通过使用 XML 可以对原有的元数据信息进行覆盖和扩展。在应用程序中,通过使用 Bean Validation 或是你自己定义的 constraint,例如 @NotNull, @Max, @ZipCode, 就可以确保数据模型(JavaBean)的正确性。constraint 可以附加到字段,getter 方法,类或者接口上面。对于一些特定的需求,用户可以很容易的开发定制化的 constraint。Bean Validation 是一个运行时的数据验证框架,在验证之后验证的错误信息会被马上返回。
下载 JSR 303 – Bean Validation 规范 http://jcp.org/en/jsr/detail?id=303
Hibernate Validator 是 Bean Validation 的参考实现 . Hibernate Validator 提供了 JSR 303 规范中所有内置 constraint 的实现,除此之外还有一些附加的 constraint。如果想了解更多有关 Hibernate Validator 的信息,请查看 http://www.hibernate.org/subprojects/validator.html
表 1. Bean Validation 中内置的 constraint
| Constraint | 详细信息
|@Null|被注释的元素必须为 null
|@NotNull|被注释的元素必须不为 null
|@AssertTrue|被注释的元素必须为 true
|@AssertFalse|被注释的元素必须为 false
|@Min(value)|被注释的元素必须是一个数字,其值必须大于等于指定的最小值
|@Max(value)|被注释的元素必须是一个数字,其值必须小于等于指定的最大值
|@DecimalMin(value)|被注释的元素必须是一个数字,其值必须大于等于指定的最小值
|@DecimalMax(value)|被注释的元素必须是一个数字,其值必须小于等于指定的最大值
|@Size(max, min)|被注释的元素的大小必须在指定的范围内
|@Digits (integer, fraction)|被注释的元素必须是一个数字,其值必须在可接受的范围内
|@Past|被注释的元素必须是一个过去的日期
|@Future|被注释的元素必须是一个将来的日期
|@Pattern(value)|被注释的元素必须符合指定的正则表达式
建立一个动态web项目,起名为SpringMVC_crud
导包,其中包括jstl的一些包等
1.先写一个User.java,是用户类
**  **
**
** 文件User.java文件**
1 | package org.common.model; |
2.再创建Controller控制器
**  **
**
** 文件UserController.java**
add的时候有两种,第一种
1 | //链接到add页面时候是GET请求,会访问这段代码 |
第二种
1 | //链接到add页面时候是GET请求,会访问这段代码 |
1 | package org.common.controller; |
jsp/user/add.jsp
1 | http://localhost:8080/springmvc_crud/user/add |










