//列出当前目录的文件和文件夹 val filesHere = (new java.io.File(".")).listFiles
for (file <- filesHere) println(file)
//打印1到4 for (i <- 1 to 4) println(i)
//打印1到3 for (i <- 1 until 4) println(i)
//for循环中的过滤功能 for (file <- filesHere if file.getName.endsWith("project")) println(file)
//for循环中的过滤功能,多个条件用;号分隔 for (file <- filesHere if file.isFile; if file.getName.endsWith("sbt") ) println(file)
//嵌套枚举 for( a <- 1 to 3; b <- 1 to 3){ println( "Value of a: " + a ); println( "Value of b: " + b ); }
//for循环采用yield,可以从存储中返回for循环中的变量的值,输出List(1, 2, 4, 5, 6, 7) val numList = List(1,2,3,4,5,6,7,8,9,10) System.out.println( for{ a <- numList if a != 3; if a < 8 }yield a )
4.使用try表达式处理异常
抛出异常
1 2 3 4 5 6 7
//抛出异常 def isEven(n : Int): Unit ={ val half = if (n % 2 == 0) n / 2 else throw new RuntimeException("n必须是偶数") }
捕获异常,finally语句
1 2 3 4 5 6 7 8 9 10 11 12
val file = new FileReader("input.txt") try { //使用文件 } catch { //捕获异常 case ex: FileNotFoundException => case ex: IOException => } finally { //确保文件关闭 file.close() }
/** * Created by common on 17-4-3. */ object Rational { def main(args: Array[String]) {
var r1 = new Rational(1, 2) var r2 = new Rational(1) System.out.println(r1.toString) System.out.println(r1.add(r2).toString) var r3 = new Rational(2, 2) System.out.println(r3) System.out.println(r1 + r3) } }
class Rational(n: Int, d: Int) { //检查先决条件,不符合先决条件将抛出IllegalArgumentException require(d != 0) //最大公约数 private val g = gcd(n.abs, d.abs)
private def gcd(a: Int, b: Int): Int = { if (b == 0) a else gcd(b, a % b) }
//进行约分 val numer: Int = n / g val denom: Int = d / g
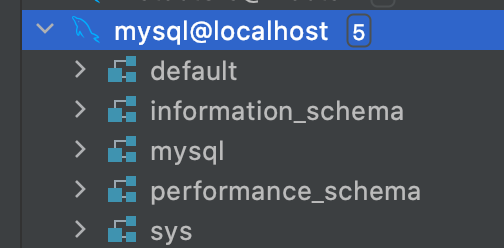
mysql> SHOW VARIABLES LIKE 'datadir'; +---------------+----------------------+ | Variable_name | Value | +---------------+----------------------+ | datadir | /var/lib/mysql/data/ | +---------------+----------------------+ 1 row in set (0.01 sec)
查看datadir目录下的所有文件夹
1 2 3 4 5 6
sh-4.2$ ls -l | grep '^d' drwxr-x--- 2 mysql mysql 4096 Aug 24 12:36 default drwxr-x--- 2 mysql mysql 4096 Jan 31 2024 mysql drwxr-x--- 2 mysql mysql 4096 Jan 31 2024 performance_schema drwxr-x--- 2 mysql mysql 12288 Jan 31 2024 sys
sh-4.2$ ls -l | grep -v '^d' total 41032 -rw-r----- 1 mysql mysql 56 Jan 31 2024 auto.cnf -rw-r----- 1 mysql mysql 2 Aug 15 15:05 bc130f3f763a.pid -rw------- 1 mysql mysql 1680 Jan 31 2024 ca-key.pem -rw-r--r-- 1 mysql mysql 1112 Jan 31 2024 ca.pem -rw-r--r-- 1 mysql mysql 1112 Jan 31 2024 client-cert.pem -rw------- 1 mysql mysql 1680 Jan 31 2024 client-key.pem -rw-r----- 1 mysql mysql 477 Aug 15 15:05 ib_buffer_pool -rw-r----- 1 mysql mysql 8388608 Aug 24 15:25 ib_logfile0 -rw-r----- 1 mysql mysql 8388608 Aug 24 15:05 ib_logfile1 -rw-r----- 1 mysql mysql 12582912 Aug 24 15:25 ibdata1 -rw-r----- 1 mysql mysql 12582912 Aug 24 15:06 ibtmp1 -rw-r--r-- 1 mysql mysql 6 Jan 31 2024 mysql_upgrade_info -rw------- 1 mysql mysql 1676 Jan 31 2024 private_key.pem -rw-r--r-- 1 mysql mysql 452 Jan 31 2024 public_key.pem -rw-r--r-- 1 mysql mysql 1112 Jan 31 2024 server-cert.pem -rw------- 1 mysql mysql 1676 Jan 31 2024 server-key.pem
/** * Created by common on 17-3-26. */ public class WordCount { public static class WordCountMap extends Mapper<LongWritable, Text, Text, IntWritable> {
private final IntWritable one = new IntWritable(1); private Text word = new Text();
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString(); StringTokenizer token = new StringTokenizer(line); while (token.hasMoreTokens()) { word.set(token.nextToken()); context.write(word, one); } } }
public static class WordCountReduce extends Reducer<Text, IntWritable, Text, IntWritable> {
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int sum = 0; for (IntWritable val : values) { sum += val.get(); } context.write(key, new IntWritable(sum)); } }
public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); Job job = new Job(conf); job.setJarByClass(WordCount.class); job.setJobName("wordcount");
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. -->
<!-- Put site-specific property overrides in this file. -->