1.MySQL的存储路径 1 2 3 4 5 6 7 8 mysql> SHOW VARIABLES LIKE 'datadir'; +---------------+----------------------+ | Variable_name | Value | +---------------+----------------------+ | datadir | /var/lib/mysql/data/ | +---------------+----------------------+ 1 row in set (0.01 sec)
查看datadir目录下的所有文件夹
1 2 3 4 5 6 sh-4.2$ ls -l | grep '^d' drwxr-x--- 2 mysql mysql 4096 Aug 24 12:36 default drwxr-x--- 2 mysql mysql 4096 Jan 31 2024 mysql drwxr-x--- 2 mysql mysql 4096 Jan 31 2024 performance_schema drwxr-x--- 2 mysql mysql 12288 Jan 31 2024 sys
这和MySQL的database是对应的
其中default 是创建的database,目录下会包含opt,frm和ibd文件
db.opt ,用来存储当前数据库的默认字符集和字符校验规则。
frm(Form) 文件存储表定义。
ibd(InnoDB Data) 存储数据和索引文件。
1 2 3 4 5 sh-4.2$ pwd /var/lib/mysql/data/default sh-4.2$ ls db.opt singer.frm singer.ibd song.frm song.ibd song_singer.frm song_singer.ibd t_user.frm t_user.ibd test.frm test.ibd user.frm user.ibd
information_schema 是每个MySQL实例中的一个数据库,存储MySQL服务器维护的所有其他数据库的信息。INFORMATION_SCHEMA数据库包含几个只读的表。它们实际上是视图,而不是基表,因此没有与它们关联的文件,而且你不能在它们上设置触发器。此外,没有使用该名称的数据库目录。
mysql 数据库为系统数据库。它包含存储MySQL服务器运行时所需信息的表。参考:https://dev.mysql.com/doc/refman/5.7/en/system-schema.html
performance_schema 是一个用于在底层监控MySQL服务器执行的特性。参考:https://dev.mysql.com/doc/refman/5.7/en/performance-schema-quick-start.html
sys schema,这是一组帮助dba和开发人员解释由Performance schema收集的数据的对象。Sys schema对象可用于典型的调优和诊断用例。参考:https://dev.mysql.com/doc/refman/5.7/en/sys-schema.html
参考:MySQL系统库作用:performance_schema,sys,information_schema,mysql
其他文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 sh-4.2$ ls -l | grep -v '^d' total 41032 -rw-r----- 1 mysql mysql 56 Jan 31 2024 auto.cnf -rw-r----- 1 mysql mysql 2 Aug 15 15:05 bc130f3f763a.pid -rw------- 1 mysql mysql 1680 Jan 31 2024 ca-key.pem -rw-r--r-- 1 mysql mysql 1112 Jan 31 2024 ca.pem -rw-r--r-- 1 mysql mysql 1112 Jan 31 2024 client-cert.pem -rw------- 1 mysql mysql 1680 Jan 31 2024 client-key.pem -rw-r----- 1 mysql mysql 477 Aug 15 15:05 ib_buffer_pool -rw-r----- 1 mysql mysql 8388608 Aug 24 15:25 ib_logfile0 -rw-r----- 1 mysql mysql 8388608 Aug 24 15:05 ib_logfile1 -rw-r----- 1 mysql mysql 12582912 Aug 24 15:25 ibdata1 -rw-r----- 1 mysql mysql 12582912 Aug 24 15:06 ibtmp1 -rw-r--r-- 1 mysql mysql 6 Jan 31 2024 mysql_upgrade_info -rw------- 1 mysql mysql 1676 Jan 31 2024 private_key.pem -rw-r--r-- 1 mysql mysql 452 Jan 31 2024 public_key.pem -rw-r--r-- 1 mysql mysql 1112 Jan 31 2024 server-cert.pem -rw------- 1 mysql mysql 1676 Jan 31 2024 server-key.pem
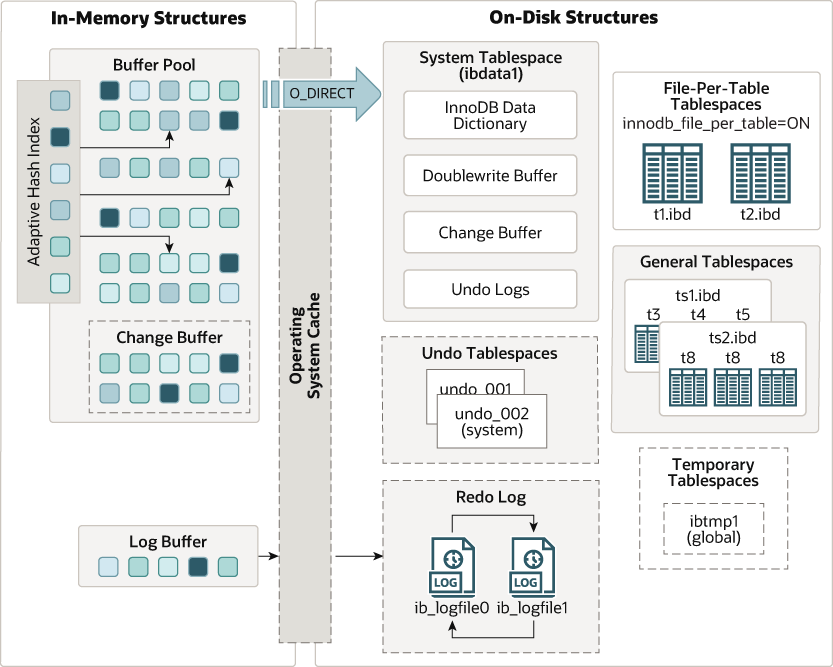
在 MySQL 的 InnoDB 存储引擎中,这些文件(ib_buffer_pool、ib_logfile0、ib_logfile1、ibdata1、ibtmp1)代表了数据库运行时的不同数据结构和存储机制。它们各自有不同的用途,用于管理和存储 InnoDB 的数据和日志。
ib_buffer_pool
ib_logfile0**ib_logfile1** 这两个文件是 InnoDB 的 **重做日志(Redo Logs)** 文件,记录了数据库事务的更改信息(插入、更新、删除等)。这些日志文件用于在崩溃恢复过程中重新应用未写入数据文件的更改。<br />
ibdata1系统表空间 的默认文件。它用于存储多个 InnoDB 表的数据和索引,以及全局表元数据(如数据字典、回滚段等)。
表数据即可以存储在系统表空间ibdata1中,也可以存储在独立表空间中ibd,这个由参数 innodb_file_per_table 来控制,MySQL5.7及以上这个默认值为1,所以MySQL每张表都是一个独立的ibd文件。
1 2 3 4 5 6 7 8 mysql> SHOW VARIABLES LIKE 'innodb_file_per_table'; +-----------------------+-------+ | Variable_name | Value | +-----------------------+-------+ | innodb_file_per_table | ON | +-----------------------+-------+ 1 row in set (0.01 sec)
ibtmp1临时表空间 文件,专门用于存储临时表和临时数据。
2.MySQL innoDB的存储结构 1.innoDB架构 参考:https://dev.mysql.com/doc/refman/5.7/en/innodb-architecture.html
2.表空间(Tablespace) 表空间是 InnoDB 用于存储表数据和索引数据的物理存储区域。可以把表空间理解为一块大的存储区域,其中可以存放多个表和索引。
表空间由多个文件组成,这些文件可能是系统表空间 (如 ibdata1)、独立表空间 (每个表对应一个 .ibd 文件)、通用表空间 (用户定义的多个表空间文件)、临时表空间 (专门用于存储临时表和临时数据等,如ibtmp1)、Undo 表空间 (也叫做回滚表空间,是 InnoDB 存储引擎中用于存储事务的 undo logs (回滚日志) 的一种特殊类型的表空间)。
3.段,区,页,行 1.页(page) 每个表空间(tablespace) 由页(page) 组成。MySQL实例中的每个表空间都有相同的页面大小。默认情况下,所有表空间的页面大小都是16KB。在创建MySQL实例时,可以通过指定innodb_page_size选项将页面大小减小到8KB或4KB。您还可以将页面大小增加到32KB或64KB。磁盘和内存之间的数据传输是逐页进行的,innodb_page_size 表示InnoDB在任何时候在磁盘(数据文件)和内存(Buffer Pool)之间传输数据的大小。
每个表中的数据被划分为多个页(page) 。组成每个表的页(page) 被安排在一个称为b树索引 的树状数据结构中。表数据/聚簇索引(Table Data) 和辅助索引(Secondary Index) 都使用这种类型的结构。表示整个表的b树索引 称为聚簇索引 ,它是根据主键列 组织的。聚簇索引数据结构的节点包含行(row) 中所有列(字段)的值。辅助索引 结构的节点包含索引列和主键列 的值。
参考:https://dev.mysql.com/doc/refman/5.7/en/innodb-row-format.html
B+ 树中包含数据页(Data Page) 和索引页(Index Page)
索引页位于 B+ 树的非叶子节点 中,主要存储索引键和指向子节点的指针。
数据页位于 B+ 树的叶子节点 中,存储实际的数据记录。
Page的结构 如下图,其中User Records是一个单向链表,而
参考:MySQL Storage Structure
2.区(extent) 这些页被分组为大小为1MB的区段(extents) ,其中最大的页大小为16KB(64个连续的16KB页,或128个8KB页,或256个4KB页)。对于一个32KB的页面,区段大小是2MB。对于64KB的页面,区段大小为4MB。
B+ 树中每一层都是通过双向链表连接起来的,如果是以页为单位来分配存储空间,那么链表中相邻的两个页之间的物理位置并不是连续的,可能离得非常远,那么磁盘查询时就会有大量的随机I/O,随机 I/O 是非常慢的。所以在表中数据量大的时候,为某个索引分配空间的时候就不再按照页为单位分配了,而是按照区(extent)为单位分配。每个区的大小为 1MB,对于 16KB 的页来说,连续的 64 个页会被划为一个区,这样就使得链表中相邻的页的物理位置也相邻,就能使用顺序 I/O 了。
参考:MySQL 一行记录是怎么存储的?
3.段(segment) 表空间是由各个段(segment) 组成的,段是由多个区(extent)组成的。段一般分为数据段、索引段和回滚段等。
索引段(Non-Leaf Node Segment):存放 B+ 树的非叶子节点的区的集合; 数据段(Leaf Node Segment):存放 B+ 树的叶子节点的区的集合; 回滚段(Rollback Segment):存放的是回滚数据的区的集合,MVCC 利用了回滚段实现了多版本查询数据。回滚段作为undo log的一部分,undo log主要用于事务回滚和MVCC(多并发版本控制)。 参考:MySQL 一行记录是怎么存储的?
表空间中的“文件”在InnoDB中称为段(segment) 。(这些段不同于回滚段,后者实际上包含许多表空间段。)
参考:https://dev.mysql.com/doc/refman/5.7/en/innodb-file-space.html
4.行(row) InnoDB存储引擎支持四种行格式:REDUNDANT, COMPACT, DYNAMIC 和 COMPRESSED。
MySQL5.7默认的row format是dynamic
1 2 3 4 5 6 7 8 mysql> SHOW VARIABLES LIKE 'innodb_default_row_format'; +---------------------------+---------+ | Variable_name | Value | +---------------------------+---------+ | innodb_default_row_format | dynamic | +---------------------------+---------+ 1 row in set (0.00 sec)
变长(Variable-length)列不符合列值存储在b树索引节点中的规则。变长列太长而不能放在b树页上,它们存储在单独分配的磁盘页上,称为溢出页(overflow page)。这样的列称为页外列。页外列的值存储在溢出页的单链表中,每个列都有自己的一个或多个溢出页的列表。根据列的长度,可变长列的所有值或其前缀都存储在B-tree中,以避免浪费存储空间和另行读取一页。
参考:https://dev.mysql.com/doc/refman/5.7/en/innodb-row-format.html
4.Buffer Pool Buffer Pool(缓冲池)是主内存中的一个区域,InnoDB在访问表和索引数据时将在这里缓存数据。缓冲池允许频繁使用的数据直接从内存中访问,这加快了处理速度。在专用服务器上,高达80%的物理内存通常分配给缓冲池。
为了提高大容量读操作的效率,缓冲池被划分为可以容纳多行数据的页。为提高缓存管理的效率,缓冲池实现为页(Page)的链表。很少使用的数据使用最近最少使用(least recently used, LRU)算法的变体从缓存中老化。在需要空间向缓冲池添加新页时,会将最近最少使用的页清除,并将新页添加到列表的中间。
Buffer Pool的作用:
当读取数据时,如果数据存在于 Buffer Pool 中,客户端就会直接读取 Buffer Pool 中的数据,否则再去磁盘中读取。 当修改数据时,如果数据存在于 Buffer Pool 中,那直接修改 Buffer Pool 中数据所在的页,然后将其页设置为脏页(该页的内存数据和磁盘上的数据已经不一致),为了减少磁盘I/O,不会立即将脏页写入磁盘,后续由后台线程选择一个合适的时机将脏页写入到磁盘。 参考:MySQL 日志:undo log、redo log、binlog 有什么用?
3.InnoDB和MyISAM存储引擎区别 1.InnoDB和MyISAM的区别 参考:深入理解MySQL索引原理和实现——为什么索引可以加速查询?
存储引擎 InnoDB MyISAM 索引类型 InnoDB 主键是聚簇索引,二级索引是非聚簇索引 MyISAM 是非聚簇索引 支持事务 InnoDB 支持事务 MyISAM 不支持事务 锁 InnoDB 支持表锁,但默认使用行锁 MyISAM 支持表锁,不支持行锁 支持全文索引 InnoDB(5.6以后) 支持全文索引 MyISAM 支持全文索引 并发性能 InnoDB 适用于大量的插入、删除和更新操作,尤其是高并发的写操作场景,因为它支持行级锁和多版本并发控制(MVCC) MyISAM 由于其表锁机制,非常适合只读操作的大量 select 查询。 外键约束 InnoDB 支持外键约束 MyISAM 不支持外键约束
2.存储区别 MyISAM在磁盘上会存储3个文件:frm(Form)文件存储表定义,myd(MyISAM Data)存储数据文件,myi(MyISAM Index)存储索引文件
Innodb在磁盘上会存储2个文件:frm(Form)文件存储表定义,ibd(InnoDB Data)存储数据和索引文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 root@master:/var/lib/mysql/wherehows# ls cfg_application.frm flow_execution.frm FTS_00000000000001a5_CONFIG.ibd log_dataset_instance_load_status#P#P201609.ibd stg_flow_job.frm cfg_application.ibd flow_execution_id_map.frm FTS_00000000000001a5_DELETED_CACHE.ibd log_dataset_instance_load_status#P#P201610.ibd stg_flow_job.par cfg_cluster.frm flow_execution_id_map.par FTS_00000000000001a5_DELETED.ibd log_dataset_instance_load_status#P#P201611.ibd stg_flow_job#P#p0.ibd cfg_cluster.ibd flow_execution_id_map#P#p0.MYD FTS_00000000000001b1_BEING_DELETED_CACHE.ibd log_dataset_instance_load_status#P#P201612.ibd stg_flow_job#P#p1.ibd cfg_database.frm flow_execution_id_map#P#p0.MYI FTS_00000000000001b1_BEING_DELETED.ibd log_dataset_instance_load_status#P#P203507.ibd stg_flow_job#P#p2.ibd cfg_database.ibd flow_execution_id_map#P#p1.MYD FTS_00000000000001b1_CONFIG.ibd log_lineage_pattern.frm stg_flow_job#P#p3.ibd cfg_data_center.frm flow_execution_id_map#P#p1.MYI FTS_00000000000001b1_DELETED_CACHE.ibd log_lineage_pattern.ibd stg_flow_job#P#p4.ibd cfg_data_center.ibd flow_execution_id_map#P#p2.MYD FTS_00000000000001b1_DELETED.ibd log_reference_job_id_pattern.frm stg_flow_job#P#p5.ibd cfg_deployment_tier.frm flow_execution_id_map#P#p2.MYI FTS_0000000000000272_BEING_DELETED_CACHE.ibd log_reference_job_id_pattern.ibd stg_flow_job#P#p6.ibd cfg_deployment_tier.ibd flow_execution_id_map#P#p3.MYD FTS_0000000000000272_BEING_DELETED.ibd source_code_commit_info.frm stg_flow_job#P#p7.ibd cfg_job_type.frm flow_execution_id_map#P#p3.MYI FTS_0000000000000272_CONFIG.ibd source_code_commit_info.ibd stg_flow_owner_permission.frm cfg_job_type.ibd flow_execution_id_map#P#p4.MYD FTS_0000000000000272_DELETED_CACHE.ibd #sql-4312_14688.frm stg_flow_owner_permission.par cfg_job_type_reverse_map.frm flow_execution_id_map#P#p4.MYI FTS_0000000000000272_DELETED.ibd stg_cfg_object_name_map.frm stg_flow_owner_permission#P#p0.ibd cfg_job_type_reverse_map.ibd flow_execution_id_map#P#p5.MYD job_attempt_source_code.frm stg_cfg_object_name_map.ibd stg_flow_owner_permission#P#p1.ibd cfg_object_name_map.frm flow_execution_id_map#P#p5.MYI job_attempt_source_code.ibd stg_database_scm_map.frm stg_flow_owner_permission#P#p2.ibd cfg_object_name_map.ibd flow_execution_id_map#P#p6.MYD job_execution_data_lineage.frm stg_database_scm_map.ibd stg_flow_owner_permission#P#p3.ibd cfg_search_score_boost.frm flow_execution_id_map#P#p6.MYI job_execution_data_lineage.par stg_dataset_owner.frm stg_flow_owner_permission#P#p4.ibd cfg_search_score_boost.ibd flow_execution_id_map#P#p7.MYD job_execution_data_lineage#P#p0.ibd stg_dataset_owner.ibd stg_flow_owner_permission#P#p5.ibd comments.frm flow_execution_id_map#P#p7.MYI job_execution_data_lineage#P#p1.ibd stg_dataset_owner_unmatched.frm stg_flow_owner_permission#P#p6.ibd comments.ibd flow_execution.par job_execution_data_lineage#P#p2.ibd stg_dataset_owner_unmatched.ibd stg_flow_owner_permission#P#p7.ibd dataset_capacity.frm flow_execution#P#p0.ibd job_execution_data_lineage#P#p3.ibd stg_dict_dataset_field_comment.frm stg_flow.par dataset_capacity.ibd flow_execution#P#p1.ibd job_execution_data_lineage#P#p4.ibd stg_dict_dataset_field_comment.par stg_flow#P#p0.ibd dataset_case_sensitivity.frm flow_execution#P#p2.ibd job_execution_data_lineage#P#p5.ibd stg_dict_dataset_field_comment#P#p0.ibd stg_flow#P#p1.ibd dataset_case_sensitivity.ibd flow_execution#P#p3.ibd job_execution_data_lineage#P#p6.ibd stg_dict_dataset_field_comment#P#p1.ibd stg_flow#P#p2.ibd dataset_compliance.frm flow_execution#P#p4.ibd job_execution_data_lineage#P#p7.ibd stg_dict_dataset_field_comment#P#p2.ibd stg_flow#P#p3.ibd dataset_compliance.ibd flow_execution#P#p5.ibd job_execution_ext_reference.frm stg_dict_dataset_field_comment#P#p3.ibd stg_flow#P#p4.ibd dataset_constraint.frm flow_execution#P#p6.ibd job_execution_ext_reference.par stg_dict_dataset_field_comment#P#p4.ibd stg_flow#P#p5.ibd dataset_constraint.ibd flow_execution#P#p7.ibd job_execution_ext_reference#P#p0.ibd stg_dict_dataset_field_comment#P#p5.ibd stg_flow#P#p6.ibd dataset_deployment.frm flow.frm job_execution_ext_reference#P#p1.ibd stg_dict_dataset_field_comment#P#p6.ibd stg_flow#P#p7.ibd dataset_deployment.ibd flow_job.frm job_execution_ext_reference#P#p2.ibd stg_dict_dataset_field_comment#P#p7.ibd stg_flow_schedule.frm dataset_index.frm flow_job.par job_execution_ext_reference#P#p3.ibd stg_dict_dataset.frm stg_flow_schedule.par dataset_index.ibd flow_job#P#p0.ibd job_execution_ext_reference#P#p4.ibd stg_dict_dataset_instance.frm stg_flow_schedule#P#p0.ibd dataset_inventory.frm flow_job#P#p1.ibd job_execution_ext_reference#P#p5.ibd stg_dict_dataset_instance.par stg_flow_schedule#P#p1.ibd dataset_inventory.ibd flow_job#P#p2.ibd job_execution_ext_reference#P#p6.ibd stg_dict_dataset_instance#P#p0.ibd stg_flow_schedule#P#p2.ibd dataset_owner.frm flow_job#P#p3.ibd job_execution_ext_reference#P#p7.ibd stg_dict_dataset_instance#P#p1.ibd stg_flow_schedule#P#p3.ibd dataset_owner.ibd flow_job#P#p4.ibd job_execution.frm stg_dict_dataset_instance#P#p2.ibd stg_flow_schedule#P#p4.ibd dataset_partition.frm flow_job#P#p5.ibd job_execution_id_map.frm stg_dict_dataset_instance#P#p3.ibd stg_flow_schedule#P#p5.ibd dataset_partition.ibd flow_job#P#p6.ibd job_execution_id_map.par stg_dict_dataset_instance#P#p4.ibd stg_flow_schedule#P#p6.ibd dataset_partition_layout_pattern.frm flow_job#P#p7.ibd job_execution_id_map#P#p0.MYD stg_dict_dataset_instance#P#p5.ibd stg_flow_schedule#P#p7.ibd dataset_partition_layout_pattern.ibd flow_owner_permission.frm job_execution_id_map#P#p0.MYI stg_dict_dataset_instance#P#p6.ibd stg_git_project.frm dataset_privacy_compliance.frm flow_owner_permission.par job_execution_id_map#P#p1.MYD stg_dict_dataset_instance#P#p7.ibd stg_git_project.ibd dataset_privacy_compliance.ibd flow_owner_permission#P#p0.ibd job_execution_id_map#P#p1.MYI stg_dict_dataset.par stg_job_execution_data_lineage.frm dataset_reference.frm flow_owner_permission#P#p1.ibd job_execution_id_map#P#p2.MYD stg_dict_dataset#P#p0.ibd stg_job_execution_data_lineage.ibd dataset_reference.ibd flow_owner_permission#P#p2.ibd job_execution_id_map#P#p2.MYI stg_dict_dataset#P#p1.ibd stg_job_execution_ext_reference.frm dataset_schema_info.frm flow_owner_permission#P#p3.ibd job_execution_id_map#P#p3.MYD stg_dict_dataset#P#p2.ibd stg_job_execution_ext_reference.par dataset_schema_info.ibd flow_owner_permission#P#p4.ibd job_execution_id_map#P#p3.MYI stg_dict_dataset#P#p3.ibd stg_job_execution_ext_reference#P#p0.ibd dataset_security.frm flow_owner_permission#P#p5.ibd job_execution_id_map#P#p4.MYD stg_dict_dataset#P#p4.ibd stg_job_execution_ext_reference#P#p1.ibd dataset_security.ibd flow_owner_permission#P#p6.ibd job_execution_id_map#P#p4.MYI stg_dict_dataset#P#p5.ibd stg_job_execution_ext_reference#P#p2.ibd dataset_tag.frm flow_owner_permission#P#p7.ibd job_execution_id_map#P#p5.MYD stg_dict_dataset#P#p6.ibd stg_job_execution_ext_reference#P#p3.ibd dataset_tag.ibd flow.par job_execution_id_map#P#p5.MYI stg_dict_dataset#P#p7.ibd stg_job_execution_ext_reference#P#p4.ibd db.opt flow#P#p0.ibd job_execution_id_map#P#p6.MYD stg_dict_dataset_sample.frm stg_job_execution_ext_reference#P#p5.ibd dict_business_metric.frm flow#P#p1.ibd job_execution_id_map#P#p6.MYI stg_dict_dataset_sample.ibd stg_job_execution_ext_reference#P#p6.ibd dict_business_metric.ibd flow#P#p2.ibd job_execution_id_map#P#p7.MYD stg_dict_field_detail.frm stg_job_execution_ext_reference#P#p7.ibd dict_dataset_field_comment.frm flow#P#p3.ibd job_execution_id_map#P#p7.MYI stg_dict_field_detail.par stg_job_execution.frm dict_dataset_field_comment.ibd flow#P#p4.ibd job_execution.par stg_dict_field_detail#P#p0.ibd stg_job_execution.par dict_dataset.frm flow#P#p5.ibd job_execution#P#p0.ibd stg_dict_field_detail#P#p1.ibd stg_job_execution#P#p0.ibd dict_dataset.ibd flow#P#p6.ibd job_execution#P#p1.ibd stg_dict_field_detail#P#p2.ibd stg_job_execution#P#p1.ibd dict_dataset_instance.frm flow#P#p7.ibd job_execution#P#p2.ibd stg_dict_field_detail#P#p3.ibd stg_job_execution#P#p2.ibd dict_dataset_instance.par flow_schedule.frm job_execution#P#p3.ibd stg_dict_field_detail#P#p4.ibd stg_job_execution#P#p3.ibd dict_dataset_instance#P#p0.ibd flow_schedule.par job_execution#P#p4.ibd stg_dict_field_detail#P#p5.ibd stg_job_execution#P#p4.ibd dict_dataset_instance#P#p1.ibd flow_schedule#P#p0.ibd job_execution#P#p5.ibd stg_dict_field_detail#P#p6.ibd stg_job_execution#P#p5.ibd dict_dataset_instance#P#p2.ibd flow_schedule#P#p1.ibd job_execution#P#p6.ibd stg_dict_field_detail#P#p7.ibd stg_job_execution#P#p6.ibd dict_dataset_instance#P#p3.ibd flow_schedule#P#p2.ibd job_execution#P#p7.ibd stg_flow_dag_edge.frm stg_job_execution#P#p7.ibd dict_dataset_instance#P#p4.ibd flow_schedule#P#p3.ibd job_execution_script.frm stg_flow_dag_edge.par stg_kafka_gobblin_compaction.frm dict_dataset_instance#P#p5.ibd flow_schedule#P#p4.ibd job_execution_script.ibd stg_flow_dag_edge#P#p0.ibd stg_kafka_gobblin_compaction.ibd dict_dataset_instance#P#p6.ibd flow_schedule#P#p5.ibd job_source_id_map.frm stg_flow_dag_edge#P#p1.ibd stg_kafka_gobblin_distcp.frm dict_dataset_instance#P#p7.ibd flow_schedule#P#p6.ibd job_source_id_map.par stg_flow_dag_edge#P#p2.ibd stg_kafka_gobblin_distcp.ibd dict_dataset_sample.frm flow_schedule#P#p7.ibd job_source_id_map#P#p0.MYD stg_flow_dag_edge#P#p3.ibd stg_kafka_gobblin_lumos.frm dict_dataset_sample.ibd flow_source_id_map.frm job_source_id_map#P#p0.MYI stg_flow_dag_edge#P#p4.ibd stg_kafka_gobblin_lumos.ibd dict_dataset_schema_history.frm flow_source_id_map.par job_source_id_map#P#p1.MYD stg_flow_dag_edge#P#p5.ibd stg_kafka_metastore_audit.frm dict_dataset_schema_history.ibd flow_source_id_map#P#p0.MYD job_source_id_map#P#p1.MYI stg_flow_dag_edge#P#p6.ibd stg_kafka_metastore_audit.ibd dict_field_detail.frm flow_source_id_map#P#p0.MYI job_source_id_map#P#p2.MYD stg_flow_dag_edge#P#p7.ibd stg_product_repo.frm dict_field_detail.ibd flow_source_id_map#P#p1.MYD job_source_id_map#P#p2.MYI stg_flow_dag.frm stg_product_repo.ibd dir_external_group_user_map.frm flow_source_id_map#P#p1.MYI job_source_id_map#P#p3.MYD stg_flow_dag.par stg_repo_owner.frm dir_external_group_user_map.ibd flow_source_id_map#P#p2.MYD job_source_id_map#P#p3.MYI stg_flow_dag#P#p0.ibd stg_repo_owner.ibd dir_external_user_info.frm flow_source_id_map#P#p2.MYI job_source_id_map#P#p4.MYD stg_flow_dag#P#p1.ibd stg_source_code_commit_info.frm dir_external_user_info.ibd flow_source_id_map#P#p3.MYD job_source_id_map#P#p4.MYI stg_flow_dag#P#p2.ibd stg_source_code_commit_info.ibd favorites.frm flow_source_id_map#P#p3.MYI job_source_id_map#P#p5.MYD stg_flow_dag#P#p3.ibd track_object_access_log.frm favorites.ibd flow_source_id_map#P#p4.MYD job_source_id_map#P#p5.MYI stg_flow_dag#P#p4.ibd track_object_access_log.ibd field_comments.frm flow_source_id_map#P#p4.MYI job_source_id_map#P#p6.MYD stg_flow_dag#P#p5.ibd user_login_history.frm field_comments.ibd flow_source_id_map#P#p5.MYD job_source_id_map#P#p6.MYI stg_flow_dag#P#p6.ibd user_login_history.ibd filename_pattern.frm flow_source_id_map#P#p5.MYI job_source_id_map#P#p7.MYD stg_flow_dag#P#p7.ibd user_settings.frm filename_pattern.ibd flow_source_id_map#P#p6.MYD job_source_id_map#P#p7.MYI stg_flow_execution.frm user_settings.ibd flow_dag.frm flow_source_id_map#P#p6.MYI log_dataset_instance_load_status.frm stg_flow_execution.par users.frm flow_dag.par flow_source_id_map#P#p7.MYD log_dataset_instance_load_status.par stg_flow_execution#P#p0.ibd users.ibd flow_dag#P#p0.ibd flow_source_id_map#P#p7.MYI log_dataset_instance_load_status#P#P201601.ibd stg_flow_execution#P#p1.ibd watch.frm flow_dag#P#p1.ibd FTS_0000000000000184_BEING_DELETED_CACHE.ibd log_dataset_instance_load_status#P#P201602.ibd stg_flow_execution#P#p2.ibd watch.ibd flow_dag#P#p2.ibd FTS_0000000000000184_BEING_DELETED.ibd log_dataset_instance_load_status#P#P201603.ibd stg_flow_execution#P#p3.ibd wh_etl_job_history.frm flow_dag#P#p3.ibd FTS_0000000000000184_CONFIG.ibd log_dataset_instance_load_status#P#P201604.ibd stg_flow_execution#P#p4.ibd wh_etl_job_history.ibd flow_dag#P#p4.ibd FTS_0000000000000184_DELETED_CACHE.ibd log_dataset_instance_load_status#P#P201605.ibd stg_flow_execution#P#p5.ibd wh_etl_job_schedule.frm flow_dag#P#p5.ibd FTS_0000000000000184_DELETED.ibd log_dataset_instance_load_status#P#P201606.ibd stg_flow_execution#P#p6.ibd wh_etl_job_schedule.ibd flow_dag#P#p6.ibd FTS_00000000000001a5_BEING_DELETED_CACHE.ibd log_dataset_instance_load_status#P#P201607.ibd stg_flow_execution#P#p7.ibd flow_dag#P#p7.ibd FTS_00000000000001a5_BEING_DELETED.ibd log_dataset_instance_load_status#P#P201608.ibd stg_flow.frm
3.锁区别 MyISAM存储引擎使用的是表锁。
Innodb存储引擎默认使用的是行锁,同时也支持表级锁。InnoDB使用表锁的场景,比如:
1.显式表锁
使用 LOCK TABLES 语句显式地请求 InnoDB 表锁。使用显式表锁通常是为了确保在一个会话内多个表的操作不被其他会话打扰。
1 2 3 4 LOCK TABLES table_name WRITE; -- 执行一些操作 UNLOCK TABLES;
在这种情况下,InnoDB 会为指定的表加一个表锁,防止其他事务对该表进行操作,直到显式解锁。
2.操作不使用索引的场景
当执行的操作没有使用到索引时,InnoDB 可能会退化为使用表锁。这通常发生在以下几种情况下:
全表扫描 :在执行更新或删除操作时,如果没有使用索引(例如 UPDATE table SET column = value 或 DELETE FROM table 之类的语句没有 WHERE 条件,或者 WHERE 条件没有使用索引列),InnoDB 会使用表锁以确保数据一致性。
1 2 UPDATE my_table SET column_a = 'value'; -- 没有WHERE条件,可能触发表锁
不使用索引的条件查询 :在 UPDATE 或 DELETE 语句中,使用了条件查询但条件不使用索引时,InnoDB 可能会锁住整张表。
3.ALTER TABLE 操作
ALTER TABLE 语句通常需要对表进行结构修改,这样的操作会自动导致表锁。这个锁是一个“意向独占锁”(意图锁),以便其他事务不能同时对表进行写操作。
1 2 ALTER TABLE my_table ADD COLUMN new_column INT;
4.使用全表扫描的 INSERT ... SELECT 操作
在执行 INSERT ... SELECT 时,如果 SELECT 语句对表进行了全表扫描,InnoDB 可能会使用表锁以保证插入的数据的一致性。
1 2 3 INSERT INTO my_table (column1, column2) SELECT column1, column2 FROM another_table;
如果 another_table 没有索引,并且 SELECT 语句涉及到全表扫描,那么 InnoDB 可能会锁住整张表。
5.高并发下的死锁检测优化
6.外键约束
当执行涉及外键约束的操作(如 INSERT、UPDATE 或 DELETE)时,如果父表或子表需要修改且有外键引用的约束关系时,InnoDB 可能会锁住相关的表,特别是当操作没有命中索引的情况下。
4.MySQL InnoDB的锁类型 1.共享锁(Share Locks),又称为S锁 共享锁允许持有锁的事务读取一行数据。
如果事务T1持有行r上的一个共享锁,那么来自不同事务T2的对行r上的一个锁的请求将被处理如下:T2对S锁的请求可以立即被授予。因此,T1和T2都对r持有S锁。 T2对X锁的请求不能立即被授予。
2.互斥锁(Exclusive Locks),又称为排他锁,独占锁,X锁 排他(X)锁允许持有锁的事务更新或删除一行。如果事务T1持有行r上的排他(X)锁,那么某个不同事务T2对r上任何一种类型的锁的请求都不能立即被授予。相反,事务T2必须等待事务T1释放对行r的锁。
3.意向锁(Intention Locks) 有2种类型的意向锁:
给表添加意图共享锁(IS锁)表示事务打算在表中的个别行上设置共享锁(S锁)。 比如
1 2 SELECT ... LOCK IN SHARE MODE
给表添加意图排他锁(IX锁)表示事务打算对表中的个别行设置排他锁(X锁)。比如
意图锁的协议 如下:
1.在一个事务获得表中某一行的共享锁之前,它必须首先获得表上的IS锁或更强的锁。
2.在事务获得表中某一行的排它锁之前,它必须首先获得表上的IX锁。
表级别的锁类型兼容性 总结在下面的矩阵中:
锁 X IX S IS X Conflict Conflict Conflict Conflict IX Conflict Compatible Conflict Compatible S Conflict Conflict Compatible Compatible IS Conflict Compatible Compatible Compatible
如果请求事务与现有锁兼容 ,则授予该锁,但如果与现有锁冲突 ,则不授予该锁。事务一直等待,直到有冲突的现有锁被释放。如果锁请求与已有的锁冲突,并且由于会导致死锁而无法授予,则会发生错误。
意图锁不会阻塞除了全表请求(例如,LOCK TABLES … WRITE)。意图锁的主要目的 是表明有人正在锁定某一行,或者将要锁定表中的某一行。
4.记录锁(Record Lock) 记录锁是索引记录上的锁。例如,
1 2 3 START TRANSACTION; # 或者 begin; SELECT c1 FROM t WHERE c1 = 10 FOR UPDATE;
其防止任何其他事务插入、更新或删除t.c1值等于10的行
记录锁总是锁定索引记录,即使定义的表没有索引。对于这种情况,InnoDB会创建一个隐藏的聚集索引,并使用这个索引来锁定记录。
5.间隙锁(Gap Lock) 间隙锁是对索引记录之间的间隙的锁,或者对第一个或最后一个索引记录之前或之后的间隙的锁。例如,
1 2 3 START TRANSACTION; # 或者 begin; SELECT c1 FROM t WHERE c1 BETWEEN 10 and 20 FOR UPDATE;
其防止其他事务将值15插入到列t.c1中,无论该列中是否已经有这样的值,因为范围中所有现有值之间的差距被锁定。
间隙可能跨越单个索引值、多个索引值,甚至是空的。
间隔锁是性能和并发性之间权衡的一部分,只用于如下2种事务隔离级别,而不用于其他级别。
可重复读(REPEATABLE READ):在这个级别中,间隙锁防止了幻读,确保同一查询在同一事务中多次执行时返回相同的结果。 串行化(SERIALIZABLE):这个级别进一步加强了对并发事务的控制,间隙锁会被用于确保事务之间完全隔离。 这里还值得注意的是,不同的事务可以在gap上持有冲突的锁。例如,事务A可以在一个间隙上持有一个共享间隙锁(gap S-lock),而事务B可以在同一个间隙上持有一个排他间隙锁(gap X-lock)。允许冲突间隔锁的原因是,如果从索引中清除记录,则不同事务在记录上持有的间隔锁必须合并。
6.下一键锁(Next-Key Lock) 下一键锁是索引记录上的记录锁(Record Locks)和索引记录前间隙上的间隙锁(Gap Locks)的组合。 例如,即id == 2的记录锁和id < 2的间隙锁
1 2 3 START TRANSACTION; # 或者 begin; SELECT * FROM employees WHERE id <= 2 FOR UPDATE;
默认情况下,InnoDB使用可重复读取事务隔离级别操作。在这种情况下,InnoDB使用下一键锁(next-key lock)来进行搜索和索引扫描,从而防止出现幻读。
7.插入意向锁( Insert Intention Locks) 插入意图锁是一种间隙锁,它由行插入之前的插入操作设置。该锁表示插入的意图,插入到相同索引间隙的多个事务如果不在间隙内的相同位置插入,则无需等待对方。
假设有值为4和7的索引记录。分别尝试插入值5和6的独立事务,在获得插入行上的互斥锁之前,每个锁的插入意图锁间隔在4和7之间,但不会相互阻塞,因为行不冲突。
8.自增锁(AUTO-INC锁) AUTO-INC锁是一种特殊的表级锁,由插入到具有AUTO_INCREMENT列的表中的事务获得。在最简单的情况下,如果一个事务正在向表中插入值,那么任何其他事务都必须等待在该表中进行自己的插入,以便第一个事务插入的行接收连续的主键值。
9.空间索引的谓词锁( Predicate Locks for Spatial Indexes) 为了支持具有空间索引的表的隔离级别,InnoDB使用谓词锁。空间索引包含最小边界矩形(minimum bounding rectangle, MBR)值,因此InnoDB通过对查询使用的MBR值设置一个谓词锁来强制索引的一致性读取。其他事务不能插入或修改符合查询条件的行。
参考:https://dev.mysql.com/doc/refman/5.7/en/innodb-locking.html