1.使用Spark读取MySQL中某个表中的信息
build.sbt文件
1 | name := "spark-hbase" |
Mysql.scala文件
1 | import org.apache.spark.{SparkConf, SparkContext} |
输出

2.使用Spark写MySQL中某个表中的信息
1 | import org.apache.spark.{SparkConf, SparkContext} |

1.使用Spark读取MySQL中某个表中的信息
build.sbt文件
1 | name := "spark-hbase" |
Mysql.scala文件
1 | import org.apache.spark.{SparkConf, SparkContext} |
输出
2.使用Spark写MySQL中某个表中的信息
1 | import org.apache.spark.{SparkConf, SparkContext} |
进入HBase的安装目录,****启动HBase
1 | bin/start-hbase.sh |
打开shell命令行模式
1 | bin/hbase shell |
关闭HBase
1 | bin/stop-hbase.sh |
一个cell的值,取决于Row,Column family,Column Qualifier和Timestamp
HBase表结构

1.查看当前用户
1 | hbase(main):001:0> whoami |
2. HBase中创建表,这里面的name,sex,age,dept,course都是column-family
1 | create 'student','name','sex','age','dept','course' |

3.列出表
1 | hbase(main):005:0> list |
4.HBase中添加数据,当添加了数据之后,就有了column,‘1000’是ROW
1 | put 'student','1000','name','XiaoMing' #这么写的话,family为name,column为空 |
Spark运行的时候,采用的是主从结构,有一个节点负责中央协调, 调度各个分布式工作节点。这个中央协调节点被称为驱动器( Driver) 节点。与之对应的工作节点被称为执行器( executor) 节点。
所有的 Spark 程序都遵循同样的结构:程序从输入数据创建一系列 RDD, 再使用转化操作派生出新的 RDD,最后使用行动操作收集或存储结果 RDD 中的数据。
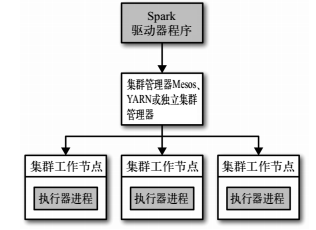
1.驱动器节点:
Spark 驱动器是执行你的程序中的 main() 方法的进程。它执行用户编写的用来创建 SparkContext、创建 RDD,以及进行 RDD 的转化操作和行动操作的代码。其实,当你启动 Spark shell 时,你就启动了一个 Spark 驱动器程序
驱动器程序在 Spark 应用中有下述两个职责:1.把用户程序转为任务 2.为执行器节点调度任务
2.执行器节点:
Spark 执行器节点是一种工作进程,负责在 Spark 作业中运行任务,任务间相互独立。 Spark 应用启动时, 执行器节点就被同时启动,并且始终伴随着整个 Spark 应用的生命周期而存在。
执行器进程有两大作用: 第一,它们负责运行组成 Spark 应用的任务,并将结果返回给驱动器进程; 第二,它们通过自身的块管理器(Block Manager)为用户程序中要求缓存的 RDD 提供内存式存储。
3.集群管理器:
驱动器节点和执行器节点是如何启动的呢? Spark 依赖于集群管理器来启动执行器节点,而在某些特殊情况下,也依赖集群管理器来启动驱动器节点。
Spark架构

1 | http://spark.apache.org/docs/latest/cluster-overview.html |
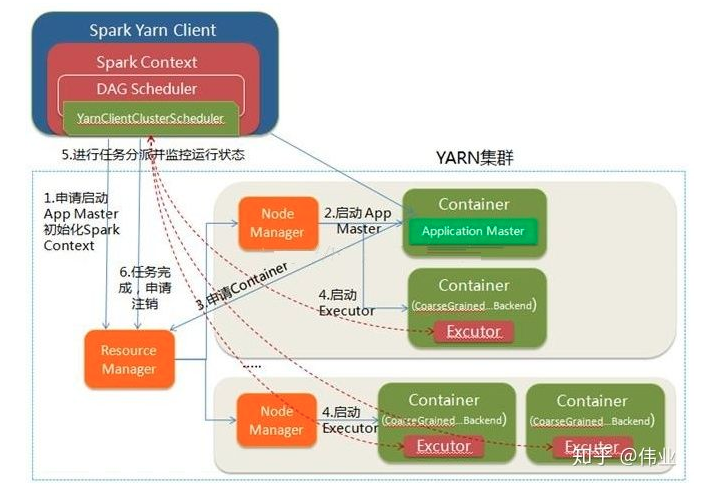
转自
1 | https://zhuanlan.zhihu.com/p/91143069 |
spark所支持的文件格式

在 Spark 中读写文本文件很容易。
当我们将一个文本文件读取为** RDD** 时,输入的每一行 都会成为 RDD 的 一个元素。
也可以将多个完整的文本文件一次性读取为一个 pair RDD, 其中键是文件名,值是文件内容。
在 Scala 中读取一个文本文件
1 | val inputFile = "file:///home/common/coding/coding/Scala/word-count/test.segmented" |
在 Scala 中读取给定目录中的所有文件
1 | val input = sc.wholeTextFiles("file:///home/common/coding/coding/Scala/word-count") |
保存文本文件,Spark 将传入的路径作为目录对待,会在那个目录下输出多个文件
1 | textFile.saveAsTextFile("file:///home/common/coding/coding/Scala/word-count/writeback") |
键值对 RDD是 Spark 中许多操作所需要的常见数据类型
键值对 RDD 通常用来进行聚合计算。我们一般要先通过一些初始** ETL(抽取、转化、装载)**操作来将数据转化为键值对形式。
Spark 为包含键值对类型的 RDD 提供了一些专有的操作。
1.创建Pair RDD
1 | val input = sc.parallelize(List(1, 2, 3, 4)) |
2.Pair RDD的转化操作
Pair RDD 可以使用所有标准 RDD 上的可用的转化操作。



Pair RDD也支持RDD所支持的函数
1 | pairs.filter{case (key, value) => value.length < 20} |
1.RDD——弹性分布式数据集(Resilient Distributed Dataset)
RDD是一个分布式的元素集合,在Spark中,对数据的操作就是创建RDD、转换已有的RDD和调用RDD操作进行求值。
Spark 中的 RDD 就是一个不可变的分布式对象集合。每个 RDD 都被分为多个分区,这些分区运行在集群中的不同节点上。
1 | object WordCount { |
创建一个RDD
1 | val textFile = sc.textFile(inputFile) |
或者
1 | val lines = sc.parallelize(List("pandas", "i like pandas")) |
RDD支持两种类型的操作: **转化操作(transformation)和行动操作(action)**。
转化操作,是返回一个新的RDD的操作:
filter()函数
1 | val RDD = textFile.filter(line => line.contains("Hadoop")) |
1.本地函数
可以在一个方法内再次定义一个方法,这个方法就是外部方法的内部私有方法,省略了private关键字
2.头等函数
1 | var increase = (x: Int) => x + 1 |
集合类的foreach方法
1 | var list1 = List(1, 2) |
集合类的filter方法
1 | list1.filter((x: Int) => x > 1) |
3.函数字面量的短格式,使得函数写的更加简洁
1 | //函数字面量的短格式 |
4.占位符语法,如果想让函数字面量更加简洁,可以把下划线当做一个或更多参数的占位符
1 | //使用占位符语法 |
1.通过realy机器登录relay-shell
1 | ssh XXX@XXX |
2.登录了跳板机之后,连接可以用的机器
1 | XXXX.bj |
3.在本地的idea生成好程序的jar包(word-count_2.11-1.0.jar)之后,把jar包和需要put到远程机器的hdfs文件系统中的文件通过scp命令从开发机传到远程的机器中
1 | scp 开发机用户名@开发机ip地址:/home/XXXXX/文件 . #最后一个.表示cd的根目录下 |
1 | object WordCount { |
4.通过put命令将远程机器中的txt文件,传到远程机器的hdfs文件系统
1.在清华镜像站点下载hbase的安装文件,选择的是stable的版本,版本号是hbase-1.2.5/
2.解压放在/usr/local的目录下
3.修改权限
1 | sudo chown -R hduser hadoop hbase-1.2.5/ |
4.修改文件夹的名称为hbase
5.在~/.bashrc下添加,之后source一下
1 | export PATH=$PATH:/usr/local/hbase/bin |
或者在 /etc/profile中添加
1 | export HBASE_HOME=/usr/local/hbase |
6.修改文件夹的权限
2.删除三个文件夹: SogouPY, SogouPY.users, sogou-qimpanel
然后重启输入法
