case class Person(firstName: String, lastName: String, address: List[Address]) { override def toString = s"Person(firstName=$firstName, lastName=$lastName, address=$address)" }
case class Address(line1: String, city: String, state: String, zip: String) { override def toString = s"Address(line1=$line1, city=$city, state=$state, zip=$zip)" }
object WordCount { def main(args: Array[String]) { val inputJsonFile = "file:///home/common/coding/coding/Scala/word-count/test.json" val conf = new SparkConf().setAppName("WordCount").setMaster("local") val sc = new SparkContext(conf) val input5 = sc.textFile(inputJsonFile) val dataObjsRDD = input5.map { myrecord => implicit val formats = DefaultFormats // Workaround as DefaultFormats is not serializable val jsonObj = parse(myrecord) //val addresses = jsonObj \ "address" //println((addresses(0) \ "city").extract[String]) jsonObj.extract[Person] } dataObjsRDD.saveAsTextFile("file:///home/common/coding/coding/Scala/word-count/test1.json")
}
}
读取的JSON文件
1 2 3
{"firstName":"John","lastName":"Smith","address":[{"line1":"1 main street","city":"San Francisco","state":"CA","zip":"94101"},{"line1":"1 main street","city":"sunnyvale","state":"CA","zip":"94000"}]} {"firstName":"Tim","lastName":"Williams","address":[{"line1":"1 main street","city":"Mountain View","state":"CA","zip":"94300"},{"line1":"1 main street","city":"San Jose","state":"CA","zip":"92000"}]}
输出的文件
1 2 3
Person(firstName=John, lastName=Smith, address=List(Address(line1=1 main street, city=San Francisco, state=CA, zip=94101), Address(line1=1 main street, city=sunnyvale, state=CA, zip=94000))) Person(firstName=Tim, lastName=Williams, address=List(Address(line1=1 main street, city=Mountain View, state=CA, zip=94300), Address(line1=1 main street, city=San Jose, state=CA, zip=92000)))
val conf = new SparkConf().setAppName("WordCount").setMaster("local") val sc = new SparkContext(conf) val input = sc.wholeTextFiles("/home/common/coding/coding/Scala/word-count/sample_map.csv") val result = input.flatMap { case (_, txt) => val reader = new CSVReader(new StringReader(txt)); reader.readAll().map(x => Data(x(0), x(1), x(2))) } for(res <- result){ println(res) } }
val conf = new SparkConf().setAppName("WordCount").setMaster("local") val sc = new SparkContext(conf) val input = sc.wholeTextFiles("/home/common/coding/coding/Scala/word-count/sample_map.csv")<br /> //wholeTextFiles读出来是一个RDD(String,String) val result = input.flatMap { case (_, txt) => val reader = new CSVReader(new StringReader(txt)); //reader.readAll().map(x => Data(x(0), x(1), x(2))) reader.readAll() } result.collect().foreach(x => { x.foreach(println); println("======") })
} }
输出
1 2 3 4 5 6 7 8 9
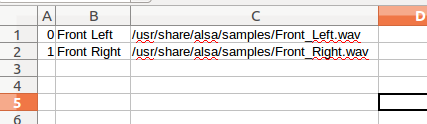
0 Front Left /usr/share/alsa/samples/Front_Left.wav ====== 1 Front Right /usr/share/alsa/samples/Front_Right.wav ======
val conf = new SparkConf().setAppName("WordCount").setMaster("local") val sc = new SparkContext(conf) val inputRDD = sc.parallelize(List(Data("index", "title", "content"))) inputRDD.map(data => List(data.index, data.title, data.content).toArray) .mapPartitions { data => val stringWriter = new StringWriter(); val csvWriter = new CSVWriter(stringWriter); csvWriter.writeAll(data.toList) Iterator(stringWriter.toString) }.saveAsTextFile("/home/common/coding/coding/Scala/word-count/sample_map_out") } }
/** * Created by common on 17-4-6. */ object SparkRDD {
def main(args: Array[String]) { val conf = new SparkConf().setAppName("WordCount").setMaster("local") val sc = new SparkContext(conf)
//使用老式 API 读取 KeyValueTextInputFormat(),以JSON文件为例子 //注意引用的包是org.apache.hadoop.mapred.KeyValueTextInputFormat // val input = sc.hadoopFile[Text, Text, KeyValueTextInputFormat]("input/test.json").map { // case (x, y) => (x.toString, y.toString) // } // input.foreach(println)
// 读取文件,使用新的API,注意引用的包是org.apache.hadoop.mapreduce.lib.input.KeyValueTextInputFormat val job = new Job() val data = sc.newAPIHadoopFile("input/test.json" , classOf[KeyValueTextInputFormat], classOf[Text], classOf[Text], job.getConfiguration) data.foreach(println)