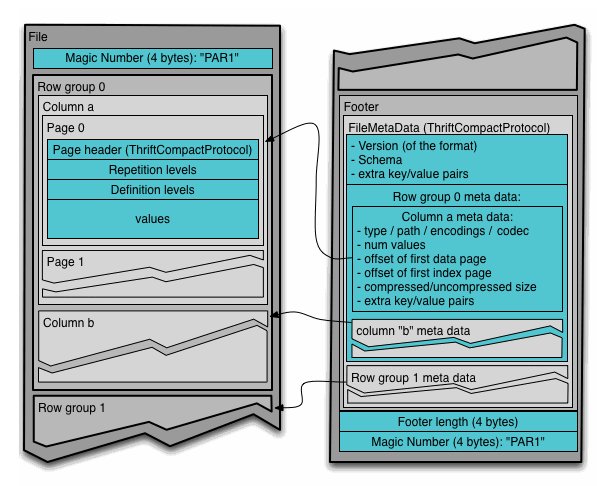
**Superset **是Airbnb 开源的大数据可视化平台
其支持的datasource
1 | https://superset.incubator.apache.org/index.html?highlight=datasource |
类似的开源项目Zeppelin所支持的datasource
1 | https://zeppelin.apache.org/docs/0.8.0/quickstart/sql_with_zeppelin.html |
1.升级python3.5到python3.6,否则会报 ERROR: Sorry, Python < 3.6 is not supported
1 | sudo add-apt-repository ppa:jonathonf/python-3.6 |
2.官方的安装文档
1 | https://superset.incubator.apache.org/installation.html |
3.安装虚拟环境