parquet是列式存储格式,官方文档
1 | https://parquet.apache.org/documentation/latest/ |
一个Parquet文件是由一个header以及一个或多个block块组成,以一个footer结尾。
header中只包含一个4个字节的数字PAR1用来识别整个Parquet文件格式,PAR1的ASCII码是[80, 65, 82, 49],所以如果使用读取parquet文件的时候,如果magic number不对的话,会报如下错误
1 | expected magic number at tail [80, 65, 82, 49] but found [xx, xx, xx, xx] |
文件中所有的metadata都存在于footer中。footer中的metadata包含了格式的版本信息,schema信息、key-value paris以及所有block中的metadata信息。footer中最后两个字段为一个以4个字节长度的footer的metadata,以及同header中包含的一样的PAR1。
在Parquet文件中,每一个block都具有一组Row group,它们是由一组Column chunk组成的列数据。继续往下,每一个column chunk中又包含了它具有的pages。每个page就包含了来自于相同列的值

Parquet 文件在磁盘上的分布情况如下图所示:
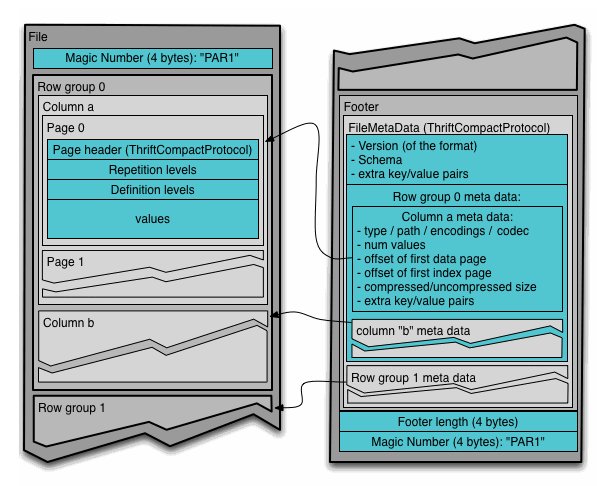
所有的数据被水平切分成 Row group,一个 Row group 包含这个 Row group 对应的区间内的所有列的 column chunk。
一个 column chunk 负责存储某一列的数据,这些数据是这一列的 Repetition levels, Definition levels 和 values。
一个 column chunk 是由 Page 组成的,Page 是压缩和编码的单元,对数据模型来说是透明的。
一个 Parquet 文件最后是 Footer,存储了文件的元数据信息和统计信息。Row group 是数据读写时候的缓存单元,所以推荐设置较大的 Row group 从而带来较大的并行度,当然也需要较大的内存空间作为代价。一般情况下推荐配置一个 Row group 大小 1G,一个 HDFS 块大小 1G,一个 HDFS 文件只含有一个块。
列式存储的优势:
1.可以跳过不符合条件的数据,只读取需要的数据,降低 IO 数据量。
2.压缩编码可以降低磁盘存储空间。由于同一列的数据类型是一样的,可以使用更高效的压缩编码(例如 Run Length Encoding 和 Delta Encoding)进一步节约存储空间。
3.只读取需要的列,支持向量运算,能够获取更好的扫描性能。
场景:重复数据
举例来说,一组资料串”AAAABBBCCDEEEE”,由4个A、3个B、2个C、1个D、4个E组成,经过变动长度编码法可将资料压缩为4A3B2C1D4E(由14个单位转成10个单位)。
场景:有序数据集,例如 timestamp,自动生成的 ID,以及监控的各种 metrics
差异存储在称为“delta”或“diff”的不连续文件中。由于改变通常很小(平均占全部大小的2%),差分编码能大幅减少资料的重复。一连串独特的delta文件在空间上要比未编码的相等文件有效率多了。
差分编码的简单例子是存储序列式资料之间的差异(而不是存储资料本身):不存“2, 4, 6, 9, 7”,而是存“2, 2, 2, 3, -2”。单独使用用处不大,但是在序列式数值常出现时可以帮助压缩资料
场景:小规模的数据集合,例如 IP 地址
词典编码是指用符号代替一串字符,在编码中仅仅把字符串看成是一个号码,而不去管它来表示什么意义,1977年由两位以色列教授发明,1985年美国Wekch对该算法进行了改进。
其他资料:获得parquet文件的schema 合并parquet小文件
