Scylla兼容cassandra API,所以可以使用spark读写cassandra的方法来进行读写
1.查看scyllaDB对应的cassandra版本#
1 | cqlsh:my_db> SHOW VERSION |
2.查看spark和cassandra对应的版本#
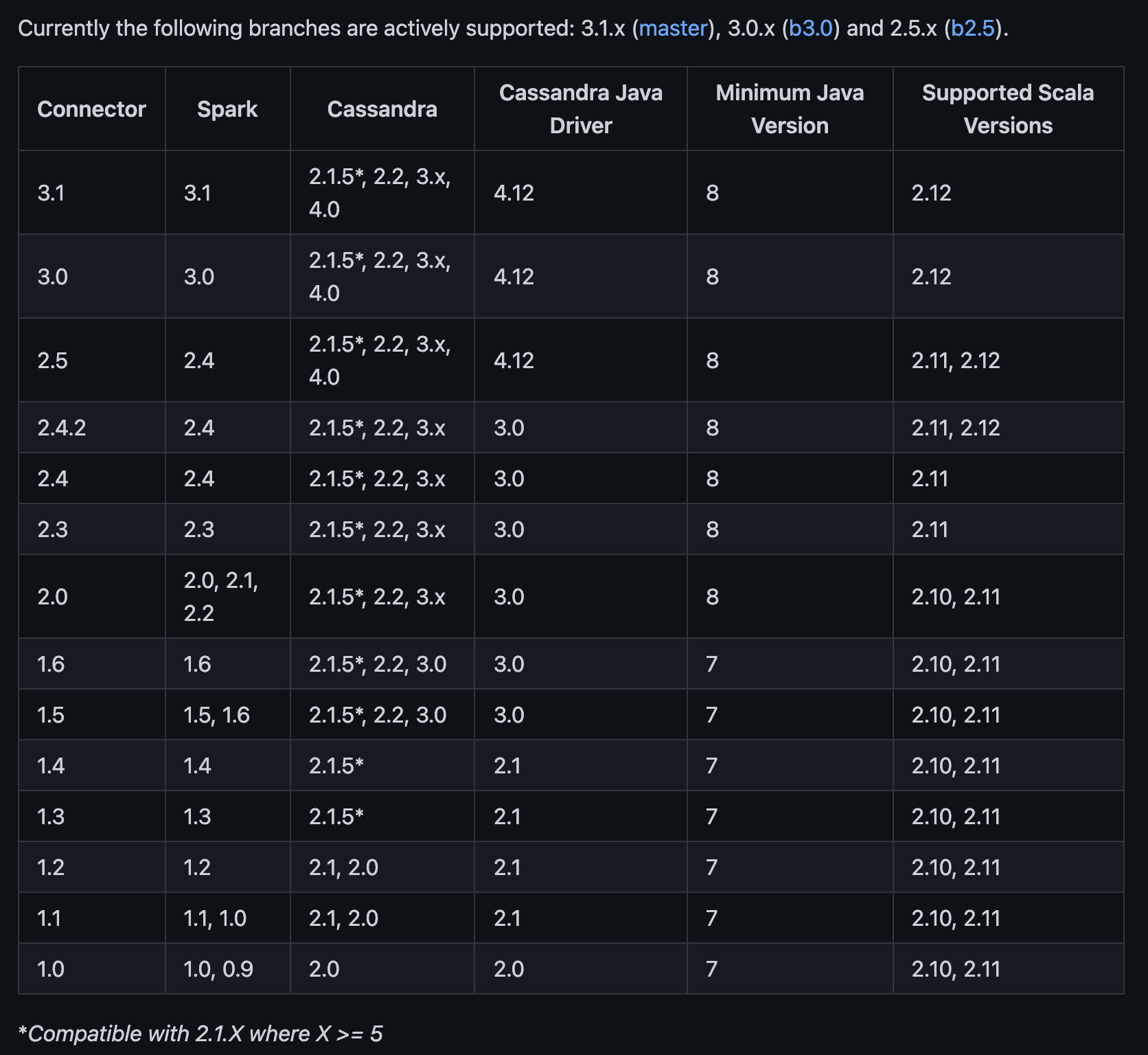
参考:https://github.com/datastax/spark-cassandra-connector
3.写scyllaDB#
dataset API写scyllaDB
1 | ds2.write |
RDD API写scyllaDB
1 | import com.datastax.oss.driver.api.core.ConsistencyLevel |
注意字段的数量和顺序需要和ScyllaDB表的顺序一致,可以使用下面方式select字段
1 | val columns = Seq[String]( |
不过官方推荐使用DataFrame API,而不是RDD API
If you have the option we recommend using DataFrames instead of RDDs
1 | https://github.com/datastax/spark-cassandra-connector/blob/master/doc/4_mapper.md |
4.读scyllaDB#
1 | val df = spark |
参考:通过 Spark 创建/插入数据到 Azure Cosmos DB Cassandra API
Cassandra Optimizations for Apache Spark
5.cassandra connector参数#
比如如果想实现spark更新scylla表的部分字段,可以将spark.cassandra.output.ignoreNulls设置为true
connector参数:https://github.com/datastax/spark-cassandra-connector/blob/master/doc/reference.md
参数调优参考:Spark + Cassandra, All You Need to Know: Tips and Optimizations
