1.索引(index)#
可以通过在数据库中创建index来加速对表的查询,index可以避免对表的一个全面扫描。对于主键和唯一键,会自动在上面创建索引。
- 通过使用快速路径访问方法快速定位数据,减少了磁盘的I/O
- 与表独立存放,但不能独立存在,必须属于某个表
- 由数据库自动维护,表被删除时,该表上的索引自动被删除
索引的原理:当以某个字段建立一个索引的时候,数据库就会生成一个索引页,索引页不单单保存索引的数据,还保存了索引在数据库的具体的物理地址。
1 | # 手动创建索引 |
注意:如果表的列很少,不适合建立索引。当执行过很多次的insert、delete、update后,会出现索引碎片。影响查询速度,我们应该对索引进行重组。
**索引列最好设置为 NOT NULL**,这通常可以提升查询效率和简化索引操作。
索引失效的场景:
- 当我们使用左或者左右模糊匹配的时候,也就是
like %xx或者like %xx%这两种方式都会造成索引失效; - 当我们在查询条件中对索引列做了计算、函数、类型转换操作,这些情况下都会造成索引失效;
- 联合索引要能正确使用需要遵循最左匹配原则,也就是按照最左优先的方式进行索引的匹配,否则就会导致索引失效。
- 在 WHERE 子句中,如果在 OR 前的条件列是索引列,而在 OR 后的条件列不是索引列,那么索引会失效。
参考:https://xiaolincoding.com/mysql/index/index_interview.html#有什么优化索引的方法?
https://xiaolincoding.com/mysql/index/index_lose.html#索引失效有哪些?
2.常见索引的种类#
主键索引 PRIMARY、唯一索引 UNIQUE、普通索引 INDEX(多字段为组合索引)、全文索引 FULLTEXT、空间索引 SPATIAL
参考:深入理解MySQL索引原理和实现——为什么索引可以加速查询?
1、主键索引#
即主索引,根据主键pk_clolum(length)建立索引,不允许重复,不允许空值;
1 | ALTER TABLE 'table_name' ADD PRIMARY KEY pk_index('col'); |
比如user的id上的主键索引,以PRIMARY命名

主键也可以是复合主键,即有多个字段,比如

主键索引最好是自增的,如果使用的是非自增主键,可能导致页分裂。参考:https://xiaolincoding.com/mysql/index/index_interview.html
2、唯一索引#
用来建立索引的列的值必须是唯一的,允许多个重复的空值,因为根据 SQL 标准,NULL 值之间被认为是不相等的
1 | ALTER TABLE `table_name` ADD UNIQUE index_name(`col`); |
比如urn和modified_date字段需要唯一,命名为uix_表名_字段1_字段2

3、普通索引#
用表中的普通列构建的索引,没有任何限制
1 | ALTER TABLE `table_name` ADD INDEX index_name(`col`); |
1.单列索引(Column Indexes)#
最常见的索引类型涉及单列,它将该列值的副本存储在数据结构中,允许快速查找具有相应列值的行。B-tree数据结构允许索引快速找到一个特定的值、一组值或一个值范围,对应于WHERE子句中的=、>、≤、BETWEEN、IN等操作符。
参考:https://dev.mysql.com/doc/refman/5.7/en/column-indexes.html
比如user表的username上加普通索引,命名为idx_表名_字段名

2.组合索引(联合索引)#
MySQL可以创建复合索引(即在多个列上创建索引)。一个索引最多可以由16列组成。
1 | CREATE TABLE test ( |
参考:https://dev.mysql.com/doc/refman/5.7/en/multiple-column-indexes.html
如果表已经存在,可以使用以下SQL来添加联合索引,在构建联合索引时,组合的多个列中允许有空值(NULL)。
1 | ALTER TABLE `table_name` ADD INDEX index_name(`col1`,`col2`,`col3`); |
组合索引需要注意字段的顺序,遵循最左匹配原则,参考:Mysql联合索引最左匹配原则

4、前缀索引#
MySQL的前缀索引(Prefix Index)是一种对部分列数据进行索引的方式,通常用于字符串类型的列(如 VARCHAR、TEXT、BLOB),而不是对整个列值创建索引。前缀索引可以在提高查询性能的同时,减少索引的大小,尤其在索引非常长的字符串列时,效果显著。
前缀索引的作用:对于较长的字符串列,建立索引时会占用大量的存储空间,前缀索引通过只对字符串的前一部分建立索引来减少存储开销。虽然前缀索引并不适用于所有查询场景,但对于某些情况下,可以有效地平衡空间和查询性能。
假设有一个 users 表,其中有一个名为 email 的列,通常来说 email 字段可能会很长,如果你想只对前 10 个字符建立索引
1 | CREATE INDEX idx_email_prefix ON users (email(10)); |
前缀索引的优点:
- 节省存储空间:相比对整个列创建索引,前缀索引可以显著减少索引的存储空间,特别是在字符串较长时效果更明显。
- 提高查询性能:对于某些查询,前缀索引可以帮助加速查询,因为索引数据量减少了。
前缀索引的缺点:
- 选择性较差:前缀索引的选择性(区分不同记录的能力)通常不如完整索引。当多个记录的前缀相同时,查询可能无法充分利用索引。
- 不能用于某些查询:前缀索引不能用于 ORDER BY 或 GROUP BY 中涉及的列,也不能用于基于列的全值比较。
前缀索引的适用场景:前缀索引适合用于字符串较长且分布比较分散的列,例如:
- Email 地址:通常前几个字符就能有效区分不同的邮箱地址。
- URL:长 URL 的前缀部分往往能很好地区分不同的记录。
- 某些大文本字段:如文章标题、内容的摘要等。
5、全文索引#
用大文本对象的列构建的索引
1 | ALTER TABLE 'table_name' ADD FULLTEXT INDEX ft_index('col'); |
比如,命名为fti_表名_all

6、空间索引 SPATIAL(只存在于MyISAM存储引擎)#
空间索引是对空间数据类型的字段建立的索引,MYSQL中的空间数据类型有4种,分别是GEOMETRY、POINT、LINESTRING、POLYGON。
MYSQL使用SPATIAL关键字进行扩展,使得能够用于创建正规索引类型的语法创建空间索引。
创建空间索引的列,必须将其声明为NOT NULL,空间索引只能在存储引擎为MyISAM的表中创建。
参考:详细介绍mysql索引类型:FULLTEXT、NORMAL、SPATIAL、UNIQUE
3.不同存储引擎的索引类型#
MySQL支持诸多存储引擎,而各种存储引擎对索引的支持也各不相同,因此MySQL数据库支持多种索引类型,如BTree索引(实际上是B+Tree索引),哈希索引,全文索引等等。参考:https://dev.mysql.com/doc/refman/5.7/en/create-index.html

索引记录存储在b树或r树数据结构的叶页中。索引页的默认大小是16KB。页面大小由MySQL实例初始化时的innodb_page_size设置决定。
参考:https://dev.mysql.com/doc/refman/5.7/en/innodb-physical-structure.html
1.InnoDB#
InnoDB索引都是b-tree数据结构。实际上InnoDB也可以额外开启hash index,hash索引的创建由InnoDB存储引擎引擎自动优化创建。
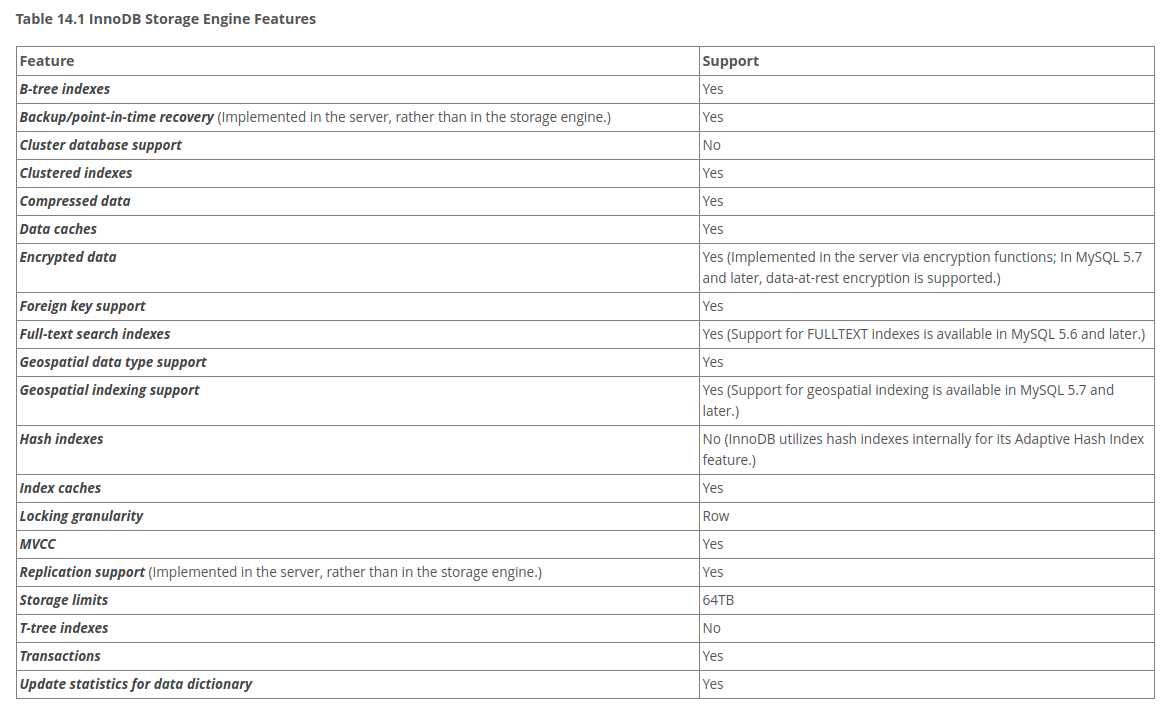
参考:**https://dev.mysql.com/doc/refman/5.7/en/innodb-introduction.html**
2.MyISAM#
MyISAM的空间索引使用r-tree,这是一种专门用于索引多维数据的数据结构。
4.Innodb存储引擎使用的是B+树#
1.B树#
BTree是平衡搜索多叉树,一棵  m阶(M阶表示这个树的每一个节点最多可以拥有的子节点个数)的 B树的特性:
m阶(M阶表示这个树的每一个节点最多可以拥有的子节点个数)的 B树的特性:
- 每个节点最多有 m 个子节点
- 每一个非叶子节点(除根节点)最少有 [m/2] 个子节点
- 如果根节点不是叶子节点,那么它至少有两个子节点
- 有 k 个子节点的非叶子节点拥有 k-1 个键,且升序排列,满足 k[i] < k[i+1]
- 所有的叶子节点都在同一层
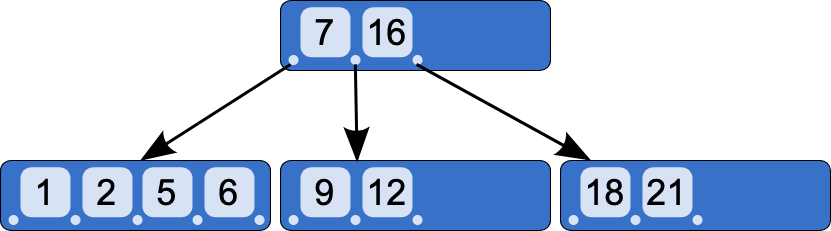
在BTree的结构下,就可以使用二分查找的查找方式,查找复杂度为h*log(n),一般来说树的高度是很小的,一般为3左右,因此BTree是一个非常高效的查找结构。
参考:https://oi-wiki.org/ds/b-tree/
2.B+树#
B+Tree是BTree的一个变种,在B+树中的节点通常被表示为一组有序的元素和子指针。
- B+树是一棵m阶树,即每个节点最多有
m个子节点,最少有⌈m/2⌉个子节点。 - 每个非叶子节点至多有
m-1个键值(也称为分支或索引),用于引导查找过程。 - 所有的数据都存储在叶子节点
- 根节点可以有少于
⌈m/2⌉的子节点(允许少于最小数量的子节点)。
m − 1 

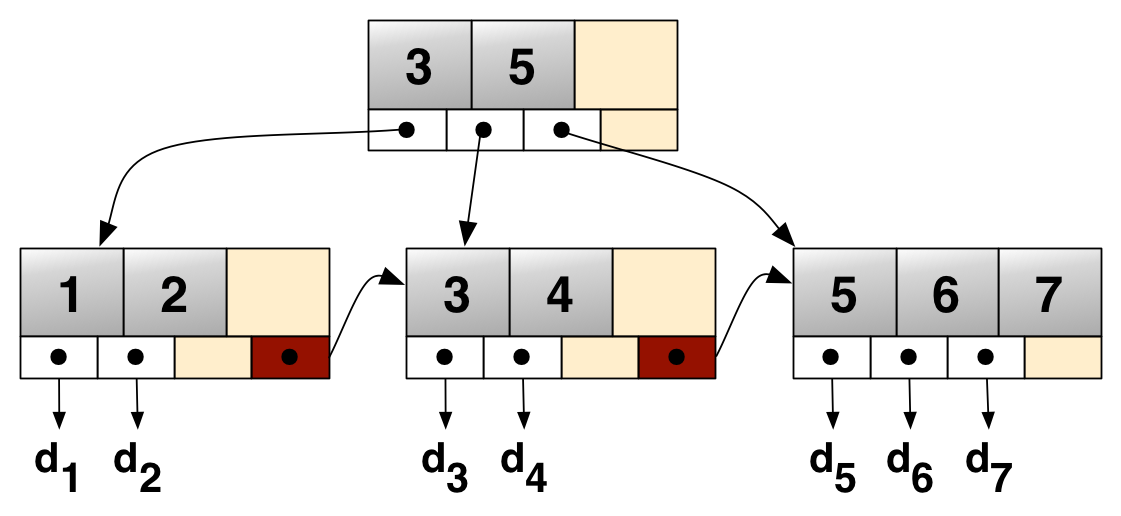
参考:https://oi-wiki.org/ds/bplus-tree/
3.B+Tree对比BTree的优点#
1、磁盘读写代价更低#
一般来说B+Tree比BTree更适合实现外存的索引结构,因为存储引擎的设计专家巧妙的利用了外存(磁盘)的存储结构,即磁盘的最小存储单位是扇区(sector),而操作系统的块(block)通常是整数倍的sector,操作系统以页(page)为单位管理内存,一页(page)通常默认为4K,数据库的页通常设置为操作系统页的整数倍,因此索引结构的节点被设计为一个页的大小,然后利用外存的“预读取”原则,每次读取的时候,把整个节点的数据读取到内存中,然后在内存中查找,已知内存的读取速度是外存读取I/O速度的几百倍,那么提升查找速度的关键就在于尽可能少的磁盘I/O,由于 B+ 树的 非叶子节点 不存储实际数据,能够容纳更多的索引键和指针,从而使每个节点的存储效率更高。也就是说,B+ 树的非叶子节点可以容纳更多的子节点,B+树的 扇出系数 更大,导致树的层级深度更低,那么树的高度越小,需要I/O的次数越少,因此一般来说B+Tree比BTree更快。
2、查询速度更稳定#
由于 B+Tree 非叶子节点不存储数据(data),因此所有的数据都要查询至叶子节点,而叶子节点的高度都是相同的,因此所有数据的查询速度都是一样的。而B树查询时候的波动就会比较大,因为数据可能在非叶子节点,也可能在叶子节点。
3、适合范围查询#
B+Tree 叶子节点采用的是双链表连接,适合 MySQL 中常见的基于范围的顺序查找,而 B 树无法做到这一点。
5.聚簇索引和非聚簇索引#
MySQL中最常见的两种存储引擎分别是MyISAM和InnoDB,MyISAM采用非聚簇索引,而InnoDB主键索引是聚簇索引,而二级索引是非聚簇索引。
如下图,Primary key是主键索引,Secondary key是二级索引
InnoDB 存储引擎:B+ 树索引的叶子节点保存数据本身;
MyISAM 存储引擎:B+ 树索引的叶子节点保存数据的物理地址;
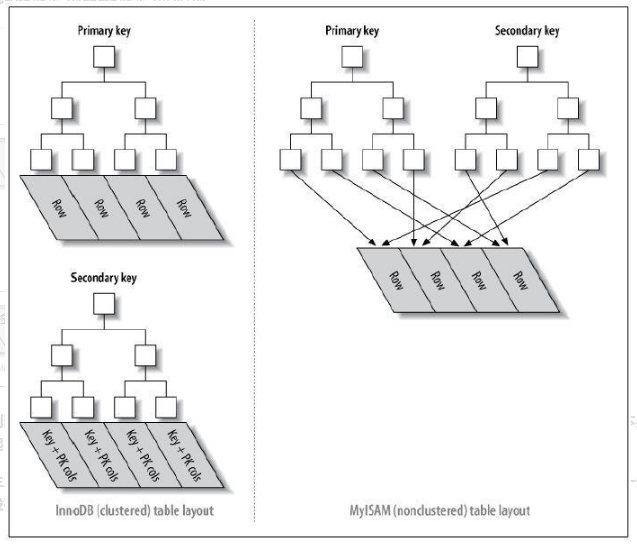
5.聚簇索引和非聚簇索引#
1.聚簇索引#
每个InnoDB表都有一个特殊的索引,称为**聚簇索引(clustered index)**,用于存储行数据。 聚簇索引的 B+ 树的叶子节点存储了整行数据。聚簇索引的顺序就是数据的物理存储顺序。
- 当你在表上定义一个主键时,InnoDB使用它作为聚簇索引。应该为每个表定义一个主键。如果没有逻辑唯一且非空的列或一组列可以使用主键,则添加一个自动递增列。自动递增的列值是唯一的,在插入新行时自动添加。
- 如果你没有为表定义一个主键,InnoDB会使用第一个唯一的索引作为聚簇索引,所有的键列都定义为not NULL。
- 如果一张表没有主键或合适的唯一索引,InnoDB会在一个包含行ID值的合成列上生成一个名为GEN_CLUST_INDEX的隐藏聚簇索引。这些行是根据InnoDB分配的行ID来排序的。row ID是一个6字节的字段,随着新行插入单调递增。因此,按行ID排序的行在物理上是按插入顺序排列的。
参考:https://dev.mysql.com/doc/refman/5.7/en/innodb-index-types.html
2.非聚簇索引#
InnoDB 的二级索引是非聚簇索引,也是基于 B+ 树的,但是其叶子节点存储的并不是完整的行数据,而是主键值和索引列的值。通过二级索引查找到主键值后,InnoDB 会使用主键查找来获取完整的行数据(这就是所谓的”回表“操作)。索引顺序与数据物理排列顺序无关。
回表 是指 MySQL 在使用非聚簇索引(也称为辅助索引或二级索引)查询时,无法通过索引本身获取所需的全部数据,必须回到主表(聚簇索引)中获取完整的行数据的过程。
回表通常会在以下情况下发生:
- 使用非聚簇索引:查询条件使用了非聚簇索引,且查询需要的列不完全包含在索引中。
- 查询所需数据不在索引中:查询需要的数据列没有在索引中全部覆盖。
具体参考:深入理解MySQL索引原理和实现——为什么索引可以加速查询?
什么时候不需要回表:
- 在查询执行时,MySQL 可以完全从索引中获取所有需要的数据,而不需要回表(即访问实际的表数据)。这叫做覆盖索引(Covering Index),覆盖索引就是包含了查询所需的所有列的索引。
如果使用了覆盖索引,在explain的时候Extra的值为Using index
