在使用hive时候,需要关注hive任务所消耗的资源,否则可能会出现hive任务过于低效,或者把所查询的数据源拉胯的情况
1.查看当前hive所使用的引擎和配置#
使用set语句可以查看当前hive的配置
1 | set; |

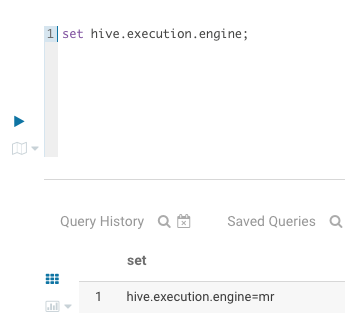
查看hive当前使用的engine
1 | set hive.execution.engine; |
查看hive.input.format和mapreduce.input.fileinputformat.split.maxsize
1 | hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat |
2.explain当前的SQL语句#
1 | explain INSERT OVERWRITE TABLE xx.xx PARTITION (pdate='2022-10-11') |
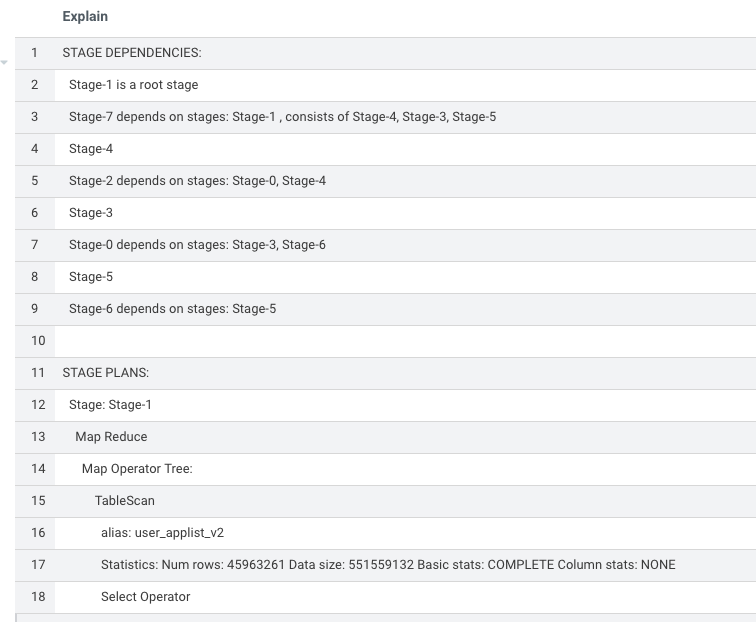
对于input format是HDFS或者s3的hive表,explain的时候可以看到在stage-1读取文件的时候,输入表的行数和数据大小
3.调整map和reduce任务数量#
首先查看SQL运行时候的日志,确定map和reduce task的数量
1 | INFO : Hadoop job information for Stage-1: number of mappers: 1727; number of reducers: 0 |
1.如果input format是HDFS或者s3的hive表#
可以参考文档:【Hive任务优化】—— Map、Reduce数量调整
2.如果hive查询的是其他的数据源#
比如使用了mongo serde来查询mongo,那么则需要去找到该serde里面和split相关的参数,比如mongo.input.split_size
1 | https://github.com/mongodb/mongo-hadoop/blob/r2.0.2/core/src/main/java/com/mongodb/hadoop/util/MongoConfigUtil.java#L155 |

