当做重要决定时,我们可能会考虑吸取多个专家而不只是一个人的意见。机器学习处理问题也是这样,这就是元算法(meta-algorithm)背后的思路。
** 元算法是对其他算法进行组合的一种方式,其中最流行的一种算法就是AdaBoost算法。某些人认为AdaBoost是最好的监督学习的方法**,所以该方法是机器学习工具箱中最强有力的工具之一。
集成学习或者元算法的一般结构是:先产生一组**“个体学习器”,再用某种策略将他们结合起来。个体学习器**通常是由一个现有的学习算法从训练数据产生。
根据个体学习器的生成方式,目前的集成学习方法大致可分为两大类,即
1.个体学习器间存在强依赖关系、必须串行生成的序列化方法,典型的代表是Boosting,其中AdaBoost就是Boosting的最流行的一个版本
2.个体学习器间不存在强依赖关系、可同时生成的并行化方法,典型的代表是Bagging和“随机森林”(Random Forest)
AdaBoost
优点:泛化错误率低,易编码,可以应用在大部分分类器上,无参数调整
缺点:对离群点敏感
使用数据类型:数值型和标称型数据
bagging:基于数据随机重抽样的分类器构建方法
自举汇聚法(bootstrap aggregating),也称为bagging方法,它直接基于自助采样法(bootstrap samping)。
给定包含m个样本的数据集,我们先随机取出一个样本放入采样集中,再把该样本放回初始数据集,使得下次采样时该样本仍有可能被选中,这样,经过m次随机采样操作,我们得到了含m个样本的采样集。这样从原始数据集选择T次后得到T个新数据集,且每个新数据集的大小和原数据集的大小相等。在T个新数据集建好之后,将某个学习算法分别作用于每个数据集就得到了T个分类器。当我们要对新数据集进行分类时,就可以应用这T个分类器进行分类。与此同时,选择分类器投票结果中最多的类别作为最后的分类结果(权重相等)。
Boosting
boosting是一种和bagging很类似的技术。其使用的多个分类器的类型都是一致的。
在boosting中,不同的分类器是通过串行训练而获得的,每个新分类器都根据已训练出的分类器的性能来进行训练。boosting是通过集中关注被已有分类器错分的那些数据来获得新的分类器。
boosting分类的结果是基于所有分类器的加权求和结果的,在bagging中的分类器权重是相等的,而boosting中的分类器权重并不相等,每个权重代表的是其对应分类器在上一轮迭代中的成功度。
现在介绍其中的AdaBoost

弱分类器的“弱”意味着分类器的性能比随机猜测要略好,但是也不会好太多。这就是说,在二分类情况下,弱分类器的错误率会高于50%,而强分类器的错误率会低很多。
AdaBoost是adaptive boosting(自适应boosting)的缩写,其运行过程如下:
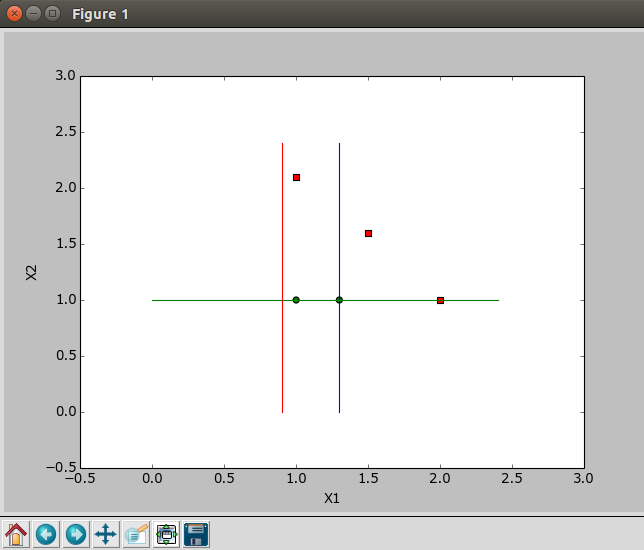
假设一个二类分类的训练数据集
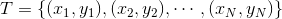
<1>训练数据中的每个样本,并赋予其一个权重,这些权重构成了初始向量D。一开始,这些权重都初始化成相等值。
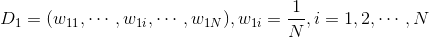
AdaBoost算法多种推导方式,比较容易理解的是基于“加性模型”,即基学习器的线性组合
 ,其中
,其中  为基学习器,
为基学习器,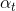 为系数
为系数
来最小化指数损失函数(exponential loss function),损失函数见 机器学习-损失函数 (转)
** 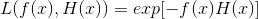 ,其中f(x)是正确的分类,等于-1或者1,H(x)是分类器的分类结果,等于-1或者1**
,其中f(x)是正确的分类,等于-1或者1,H(x)是分类器的分类结果,等于-1或者1**
** 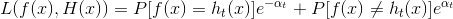 **
**
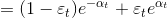
,所以对该式子求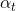 的偏导,得
的偏导,得 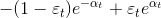 ,并令其等于0,得
,并令其等于0,得
** 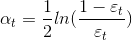 **
**
<2>首先在训练分类器上训练出一个弱分类器并计算该分类的错误率,然后在同一数据集上再次训练弱分类器。
在分类器的第二次训练中,将会重新调整每个样本的权重,其中第一次分对的样本的权重将会降低,而第一次分错的样本的权重将会提高。为了从所有弱分类器中得到最终的分类结果,AdaBoost为每个分类器都分配了一个权重值alpha,这些alpha值是基于每个弱分类器的错误率进行计算的。
其中,错误率  的定义为
的定义为
= 为正确分类的样本数目/所有样本数目
而alpha的计算公式如下:
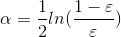
计算出alpha值之后,可以对权重向量D进行更新,以使得那些正确分类的样本的权重降低而错分样本的权重升高。D的计算方法如下:

其中,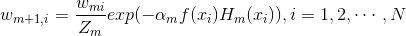 ,
,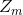 是规范化因子
是规范化因子

它使得成为一个概率分布
如果某个样本被正确分类,那么该样本的权重更改为
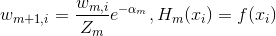
如果某个样本被错误分类,那么该样本的权重更改为
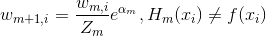
在计算出D之后,AdaBoost算法又开始进入下一轮迭代。
AdaBoost算法会不断地重复训练和调整权重的过程,直到训练错误率为0或者弱分类器的数目达到用户的指定值为止。
1 | from numpy import * |
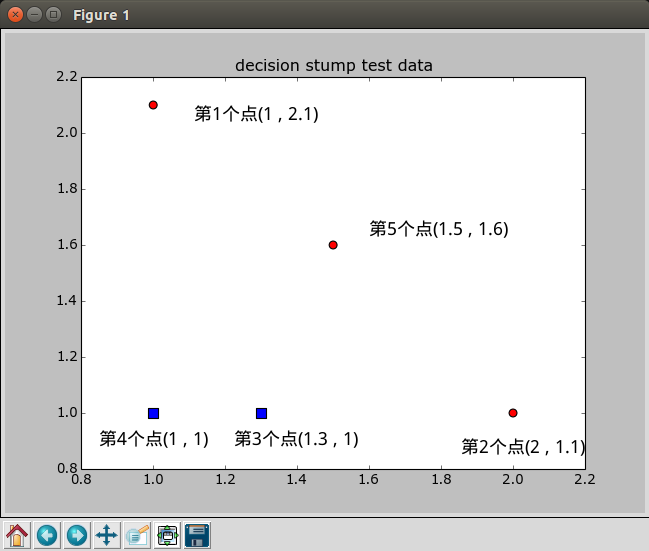
1 | def plotBestFit(weakClassArr): #画出数据集和所有的基学习器 |
main.py
1 | # coding:utf-8 |
1个分类器———— 2个分类器———— 3个分类器————