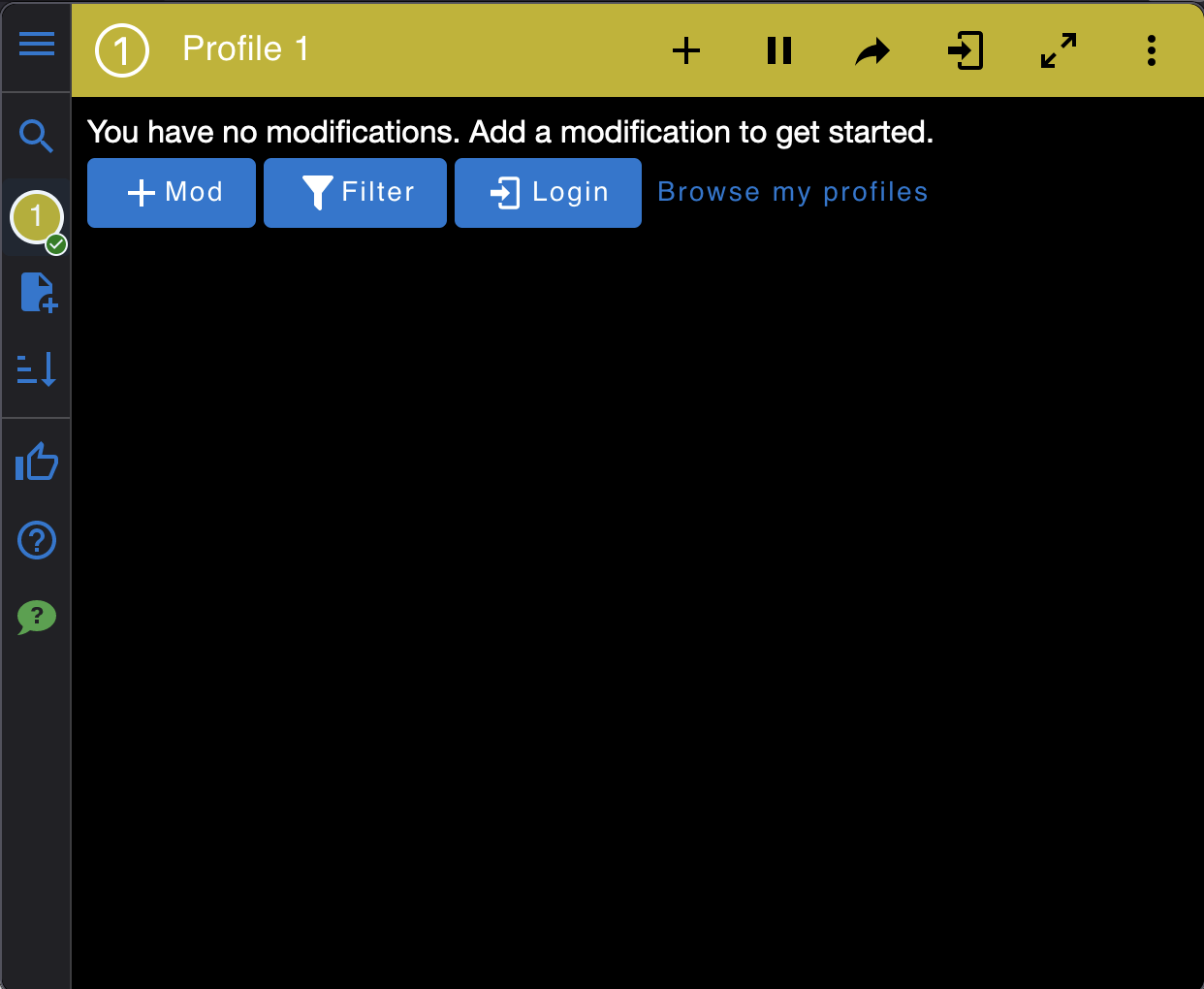
ModHeader全名modify header,这是一款可以对HTTP请求header进行修改的插件,其支持添加模式Mod和过滤器Filter。
Mod可以支持对request的header,response的header进行修改,对请求进行重定向redirect等;
Filter支持对特定的URL生效这面的这些Mod
ModHeader全名modify header,这是一款可以对HTTP请求header进行修改的插件,其支持添加模式Mod和过滤器Filter。
Mod可以支持对request的header,response的header进行修改,对请求进行重定向redirect等;
Filter支持对特定的URL生效这面的这些Mod
下面列举了一些常用的加密算法
| 加密算法 | 类别 | 介绍 | 安全性 |
|---|---|---|---|
| MD5 | hash函数 | MD5一种被广泛使用的密码散列函数,可以产生出一个128位(16个字节)的散列值(hash value)。MD5是输入不定长度信息,输出固定长度128-bits的算法。 | 不安全 |
| base64 | 编码 | Base64就是一种基于64个可打印字符来表示二进制数据的方法。Base64会增加原文的长度,通常是原始长度的 4/3 | - |
| SHA-1 | hash函数 | Secure Hash Algorithm 1(SHA-1)安全散列算法1是一种密码散列函数。SHA-1结果的长度:160 位(20 字节) | 不安全 |
| SHA-256 | hash函数 | SHA-256是一种加密哈希函数,可生成固定大小的256 位(32 字节)哈希值,其广泛用于数据完整性校验 | 安全 |
| SHA-384/512 | hash函数 | SHA-384是SHA系列中的另一种算法,它产生的哈希值为96个字符长度的十六进制数字。 与SHA256相比,SHA384具有更强的安全性。 由于其输出长度更长,因此在实际应用中适用于更高的安全需求 | 安全 |
| Hmac | 消息认证码 | HMAC(Hash-based Message Authentication Code)是一种基于哈希函数的消息认证码,用于验证消息的完整性和真实性。它结合了一个加密密钥和哈希函数,为消息提供更高的安全性。它要求通信双方共享密钥、约定算法、对报文进行Hash运算,形成固定长度的认证码。 Hmac算法可以用来作加密、数字签名、报文验证等。 | HMAC 的安全性依赖于所使用的哈希函数的强度 |
| DES | 对称加密算法 | DES全称为Data Encryption Standard,即数据加密标准,是一种使用密钥加密的块算法。DES算法的入口参数有三个:Key、Data、Mode。其中Key为DES算法的秘钥,长度8个字节(64位),其中有56位用于实际加密,还有8位用于奇偶校验;Data为8个字节64位,是要被加密或被解密的数据;Mode为DES的工作方式,有两种:加密或解密。 | 不安全 |
| 3DES | 对称加密算法 | 3DES(即Triple DES)是DES向AES过渡的加密算法,它使用3条56位的密钥对数据进行三次加密。是DES的一个更安全的变形。它以DES为基本模块,通过组合分组方法设计出分组加密算法。比起最初的DES,3DES更为安全。 | 较安全 |
| AES | 对称加密算法 | 密码学中的高级加密标准(Advanced Encryption Standard,AES),又称Rijndael加密法,是美国联邦政府采用的一种区块加密标准。这个标准用来替代原先的DES(Data Encryption Standard)。支持128位,192位和256位的秘钥长度,是目前最流行的对称加密算法。 | 安全 |
| RSA | 非对称加密算法 | RSA算法是一种非对称加密算法,与对称加密算法不同的是,RSA算法有两个不同的密钥,一个是公钥,一个是私钥。RSA允许选择公钥的大小。512位的密钥被视为不安全的;768位的密钥不用担心受到除了国家安全管理(NSA)外的其他事物的危害。RSA 加密的密文长度等于密钥的长度(以字节为单位)。常见密钥长度包括 1024 位、2048 位、3072 位等。场景:在需要保护数据机密性的场景中,RSA可以用于对敏感数据进行加密。使用公钥加密,私钥解密。适合对小数据量的内容加密(如密钥、凭据等),但不适合大数据量加密(因为效率较低)。 | 安全 |
| DSA | 非对称加密算法 | DSA(Digital Signature Algorithm)是一种用于生成和验证数字签名的算法,主要用于确保数据的完整性和发送者身份的真实性。DSA 专用于生成和验证数字签名,不能用于加密数据。安全性依赖于密钥长度以及散列函数的选择。 | 安全 |
| ECC | 非对称加密算法 | ECC(Elliptic Curve Cryptography)是一种基于椭圆曲线数学的公钥加密算法。它是一种非对称加密技术,因其提供高安全性和较小的密钥长度,已成为现代加密的主流技术之一。ECC 广泛应用于数字签名、密钥交换和加密等领域。相较于 RSA 和 DSA,ECC 在提供相同安全性的情况下,使用更短的密钥,计算量更小。ECC 适合资源有限的设备,如嵌入式系统、物联网设备和移动设备。 | 安全 |
| Blowfish | 对称加密算法 | Blowfish 是一种对称加密算法,由 Bruce Schneier 在 1993 年设计。它被广泛使用于加密数据的保护,特别是应用于资源受限的环境(如嵌入式系统)。Blowfish 是一种分组加密算法,因其高效性和灵活性,成为了当时替代传统算法(如 DES)的重要选择。 | 安全 |
| RC4 | 对称加密算法 | RC4(Rivest Cipher 4)是一种对称流加密算法,由 Ron Rivest 于 1987 年设计。这种算法因其简单、高效的特性,曾被广泛应用于通信加密、文件加密以及各种加密协议中(如 SSL/TLS 和 WEP)。然而,由于其已被证明存在严重的安全漏洞,RC4 在许多场景下已不再推荐使用。 | 不安全 |
MySQL函数官方文档可以参考:https://dev.mysql.com/doc/refman/5.7/en/functions.html
参考:https://dev.mysql.com/doc/refman/5.7/en/built-in-function-reference.html
参考:https://dev.mysql.com/doc/refman/5.7/en/flow-control-functions.html
CASE函数
1 | # 条件判断语句 |
IF()函数
1 | # IF(expr1,expr2,expr3),如果expr1是True,返回expr2,否则返回expr3 |
IFNULL()函数
1 | # IFNULL(expr1,expr2),如果字expr1不为NULL,则返回expr1,如果为NULL,则返回expr2 |
NULLIF()函数
有关数据库的DML操作
-insert into
-delete、truncate
-update
-select
-条件查询
-查询排序
-聚合函数
-分组查询
DROP、TRUNCATE、DELETE
-DELETE删除数据,保留表结构,可以回滚,如果数据量大,很慢,回滚就是因为备份删除的数据
-TRUNCATE删除所有数据,保留表结构,不可以回滚,一次全部删除所有数据,速度相对很快
-DROP删除数据和表结构,删除数据最快(直接从内存抹去这一块数据)
1 | #1.指明字段进行插入,注意字段和值的数量和类型都需要匹配 |
最简单的SELECT语句
1 | #查找 字段、字段。。。从 表 *表示所有的列 |
1.约束是在表上强制执行的数据检验规则,约束主要用于保证数据库的完整性。
2.当表中数据有相互依赖性时,可以保护相关的数据不被删除。
3.大部分数据库支持下面五类完整性约束:
- NOT NULL非空
- UNIQUE Key唯一值
- PRIMARY KEY主键
- FOREIGN KEY外键
- CHECK检查
4.约束作为数据库对象,存放在系统表中,也有自己的名字
5.创建约束的时机:
-在建表的同时创建
-建表后创建(修改表)
6.有单列约束和多列约束
列级约束直接跟在列后面定义,不再需要指定列名,与列定义之间用空格分开
表级约束通常放在所有的列定义之后定义,要显式指定对哪些列建立列级约束,与列定义之间采用英语逗号,隔开
如果是对多列建联合约束,只能使用表级约束语法
SQL——结构化查询语言(Structured Query Language)
SQL语言不区分大小写,建议关键字用大写,但是字符串常量区分大小写
字符集
1 | character_set_client:服务器将系统变量character_set_client作为客户端发送语句时使用的字符集。 |
MySQL5.7的默认字符集character和排序字符集collation
1 | mysql> show variables like '%character%'; |
MySQL8.0的默认字符集
1 | mysql> show variables like '%character%'; |
查看mysql table字段的字符集
MySQL5.7
1 | mysql> create table user |
或者
confleunt提供了一些方法,可以将protobuf schema转换成avro schema,用于支持将kafka protobuf序列化的message落盘成avro格式的文件
1 | <repositories> |
定义一个protobuf schema
1 | syntax = "proto3"; |
编译java代码
1 | protoc -I=./ --java_out=./src/main/java ./src/main/proto/other.proto |
得到schema的java代码
confluent schema registry在处理处理protobuf,avro,json格式的数据的时候,会统一先将其转换成connect schema格式的数据,然后再将其写成parquet,avro等具体的文件格式
1 | import com.acme.Other; |
hive client安装文档
1 | https://cwiki.apache.org/confluence/display/Hive/GettingStarted |
hive 配置官方文档
1 | https://cwiki.apache.org/confluence/display/hive/configuration+properties |
hive 配置中文文档
1 | https://www.docs4dev.com/docs/zh/apache-hive/3.1.1/reference/Configuration_Properties.html |
Hive学习笔记——执行计划
使用DatumWriter和DatumReader对avro进行序列化和反序列化
1 | public static <T> byte[] binarySerializable(T t) { |
使用Twitter 的 Bijection 类库来实现avro对象的序列化和反序列化
参考:Kafka 中使用 Avro 序列化框架(二):使用 Twitter 的 Bijection 类库实现 avro 的序列化与反序列化
