1.下载python3.8
1 | cd ~/Download |
解压
1 | tar -zxvf Python-3.8.11.tgz |
2.创建目录
1 | cd /usr/local |
3.编译安装
1 | ./configure prefix=/usr/local/python/python3.8 --enable-optimizations |
4.配置环境变量
1 | # python |
1.下载python3.8
1 | cd ~/Download |
解压
1 | tar -zxvf Python-3.8.11.tgz |
2.创建目录
1 | cd /usr/local |
3.编译安装
1 | ./configure prefix=/usr/local/python/python3.8 --enable-optimizations |
4.配置环境变量
1 | # python |
1 | import java.util.Arrays; |

冒泡 N^2/2比较 N^2/4交换
选择 N^2/2比较 比冒泡少的交换
插入 N^2/4比较 N^2/4复制
复制是交换的3倍



1 | class PriorityQueue{ |

1 | class Stack{ |

1 | class Stack_Char{ |

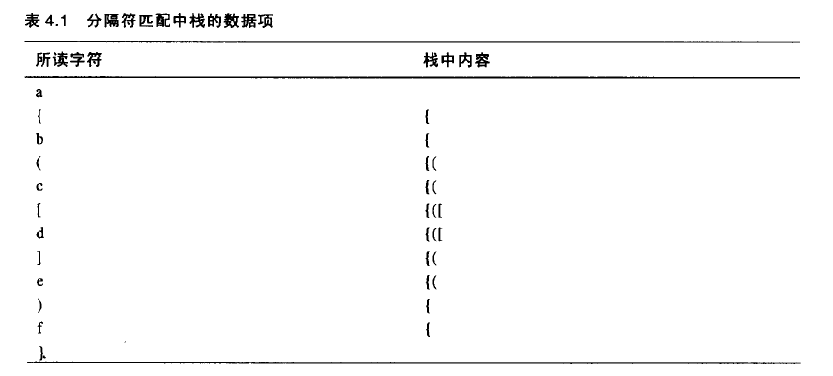
1 | import java.io.BufferedReader; |

1 | class Queue{ |


1 | package com.interview.sort; |
输出
1 | [58, 57, 56, 60, 59, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0] |



1 | import java.util.Arrays; |


1 | import java.lang.reflect.Array; |


Servlet API中提供了一个Filter接口,Filter接口在javax.servlet.Filter包下面。开发web应用时,如果编写的Java类实现了这个接口,则把这个java类称之为过滤器Filter。
通过Filter技术,开发人员可以实现用户在访问某个目标资源之前,对访问的请求和响应进行拦截,如下所示:

WEB开发人员通过Filter技术,对web服务器管理的所有web资源:例如Jsp, Servlet, 静态图片文件或静态 html 文件等进行拦截,从而实现一些特殊的功能。
例如实现URL级别的权限访问控制、乱码问题、过滤敏感词汇、压缩响应信息等一些高级功能。
filter在开发中的常见应用:
1.filter可以目标资源执行之前,进行权限检查,检查用户有无权限,如有权限则放行,如没有,则拒绝访问
2.filter可以放行之前,对request和response进行预处理,从而实现一些全局性的设置。
3.filter在放行之后,可以捕获到目标资源的输出,从而对输出作出类似于压缩这样的设置



在filter中可以对request请求进行拦截,并对response进行修改

2.查看进程中cpu占用最高的线程
1 | top -Hp ${pid} -d 1 -n 1 |

该进程的pid是279,其十六进制表示为0x117
3.打印进程的堆栈信息到文件
1 | jstack -l ${pid} > jstack.log |
