生成key文件
1 | openssl genrsa -des3 -out dummy.key 2048 |
生成pem文件
1 | openssl rsa -inform PEM -outform PEM -in dummy.key -pubout -out dummy-nopass.pem |
生成key文件
1 | openssl genrsa -des3 -out dummy.key 2048 |
生成pem文件
1 | openssl rsa -inform PEM -outform PEM -in dummy.key -pubout -out dummy-nopass.pem |
1.CPI (Cost per install)获客成本以及渠道是否有效的衡量指标
2.oCPM(Optimized Cost per Mille的缩写),即优化千次展现出价,本质还是按照cpm付费。采用更精准的点击率和转化率预估机制,将广告展现给最容易产生转化的用户,在获取流量的同时,提高转化率、降低转化成本,跑量提速更快。
3.oCPC(Optimized Cost per Click的缩写),即优化点击付费,本质还是按照cpc付费。采用更科学的转化率预估机制的准确性,可帮助广告主在获取更多优质流 量的同时提高转化完成率。系统会在广告主出价基础上,基于多维度、实时反馈及历史积累的海量数据,并根据预估的转化率以及竞争环境智能化的动态调整出价,进而优化广告排序,帮助广告主竞得最适合的流量,并降低转化成本。
4.oCPA(Optimized Cost per Action的缩写),即优化行为出价,本质还是按照cpa付费。当广告主在广告投放流程中选定特定的优化目标(例如:移动应用的激活,网站的下单),提供愿意为此投放目标而支付的平均价格,并及时、准确回传效果数据,我们将借助转化预估模型,实时预估每一次点击对广告主的转化价值,自动出价,最终按照点击扣费;同时,我们的转化预估模型会根据广告主的广告转化数据不断自动优化。
5.tCPA(Target Cost per Action的缩写),即目标每次转化出价。tCPA 是一种设定目标成本的出价策略,广告主设置一个目标每次转化费用,系统会努力在这个目标成本范围内优化转化。
6.oCPX(Optimized Cost per X),oCPX 是一种针对效果广告的智能出价投放方式,广告主选择明确的优化目标(如下载、激活、注册、付费),并给出期望的转化成本,系统通过机器学习预估每一次投放机会的转化概率,并结合期望成本,自动出价,保障成本效果稳定。
参考:QCon-oCPX多目标多场景联合建模在OPPO的实践
7.ROAS(Return on AD Spending,广告支出回报):ROAS 出价策略基于广告支出回报率进行优化,目标是最大化广告投资回报。ROAS = (可归因至广告的收入 / 广告成本) x 100
8.定向:在哪些流量上打广告
1.启动pyspark

2.读取文件
1 | >>> from pyspark.sql import SparkSession |
3.退出pyspark使用exit()
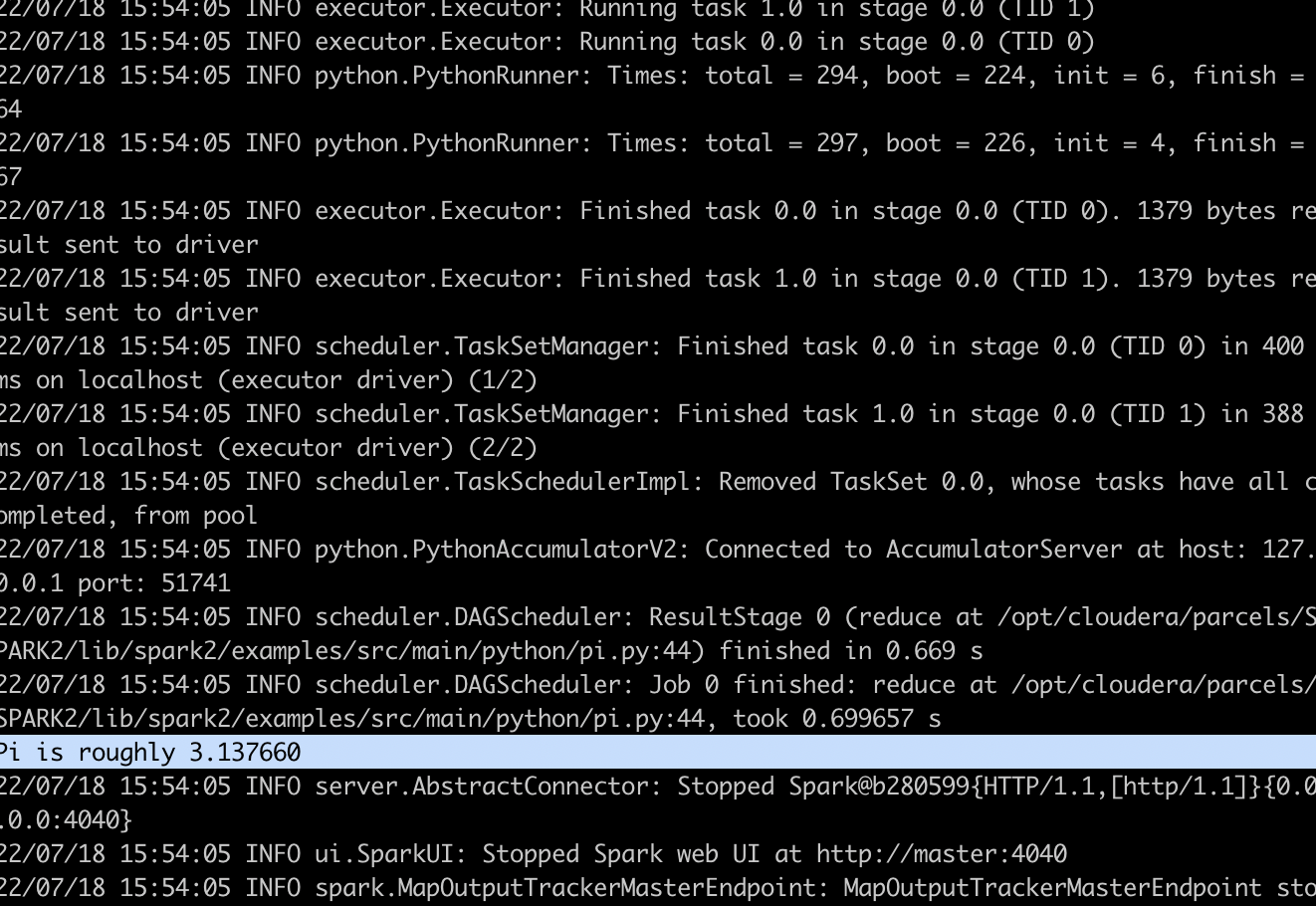
4.使用spark-submit提交pyspark任务pi.py
1 | spark2-submit --master local[*] /opt/cloudera/parcels/SPARK2/lib/spark2/examples/src/main/python/pi.py |
对比thrift使用TCompactProtocol协议,protobuf使用,以及avro使用AvroKeyOutputFormat格式进行序列化对数据进行序列化后数据量大小
由于thrift的binary数据类型不能再次序列化化成二进制,所以测试的schema中没有binary类型的字段
测试数据的avro schema定义如下
1 | { |
测试数据的thrift schema定义如下
1 | namespace java com.linkedin.haivvreo |
1 | syntax = "proto3"; |
编译protobuf schema
1 | protoc -I=./ --java_out=src/main/java/ ./src/main/proto3/test_serializer.proto |
1.设置用户名和邮箱
1 | git config --global user.name "xxxx" |
2.查看当前git的用户和邮箱
1 | git config user.name |
3.生成秘钥,回车3下,不设置密码
1 | ssh-keygen -t rsa -C "xxx@xxx.edu.cn" -f ~/.ssh/id_rsa_github |
4. ssh目录在etc/ssh下
~/.ssh/config配置文件如下
1 | #自己私人用的 GitHub 帳號,id_rsa 就是我自己原本用的 ssh key |
5.上传.pub公钥到github
6.可以git clone了
如何在本地使用git
http://jingyan.baidu.com/album/295430f1c62c900c7e0050fd.html?picindex=1
feast是google开源的一个特征平台,其提供特征注册管理,以及和特征存储(feature store),离线存储(offline store)和在线存储(online store)交互的SDK,官网文档:
1 | https://docs.feast.dev/ |
目前最新的v0.24版本支持的离线存储:File,Snowflake,BigQuery,Redshift,Spark,PostgreSQL,Trino,AzureSynapse等,参考:
1 | https://docs.feast.dev/reference/offline-stores |
在线存储:SQLite,Snowflake,Redis,Datastore,DynamoDB,PostgreSQL,Cassandra等,参考:
1 | https://docs.feast.dev/reference/online-stores |
**provider **用于定义feast运行的环境,其提供了feature store在不同平台组件上的实现,目前有4种:local, gcp,aws和azure
| provider | 支持的offline store | 支持的online store |
|---|---|---|
| local | BigQuery,file | Redis,Datastore,Sqlite |
| gcp | BigQuery,file | Datastore,Sqlite |
| aws | Redshift,file | DynamoDB,Sqlite |
| azure | Mysql,file | Redis,Splite |
参考:
1 | https://docs.feast.dev/getting-started/architecture-and-components/provider |
**data source **用于定义特征的数据来源,每个batch data source都和一个offline store关联,比如SnowflakeSource只能和Snowflake offline store关联
data source的类型包括:file,Snowflake,bigquery,redshift,push,kafka,kinesis,spark,postgreSQL,Trino,AzureSynapse+AzureSQL
| data source | offline store |
|---|---|
| FileSource | file |
| SnowflakeSource | Snowflake |
| BigQuerySource | BigQuery |
| RedshiftSource | Redshift |
| PushSource(可以同时将feature写入online和offline store) | |
| KafkaSource(仍然处于实验性) | |
| KinesisSource(仍然处于实验性) | |
| SparkSource(支持hive和parquet文件) | Spark |
| PostgreSQLSource | PostgreSQL |
| TrinoSource | Trino |
| MsSqlServerSource | AzureSynapse+AzureSQL |
JSP文件的命名最好采用小写的形式,比如hello.jsp,且必须加上第一句以用来指定编码,否则会出现乱码
1 | <%@ page language="java" import="java.util.*" contentType="text/html; charset=UTF-8" %> |

显式注释
1 | <!-- 注释内容 --> |
隐式注释,隐式注释在客户端无法看见
1 | // |
所有嵌入在HTML代码中的Java程序都必须使用Scriptlet标记起来,在JSP中一共有3种Scriptlet代码




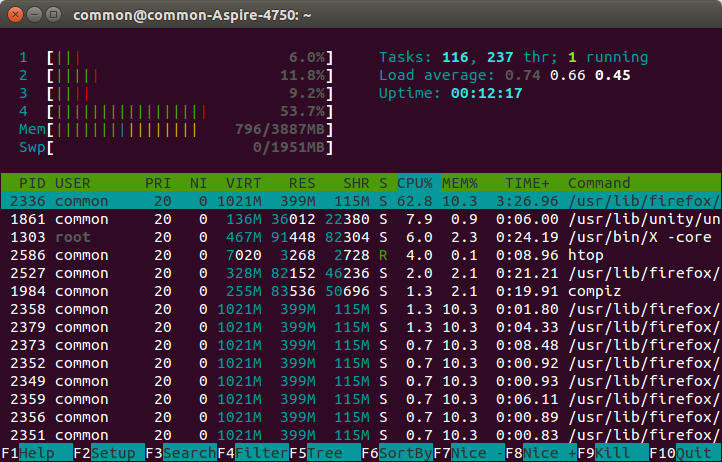
第1行-第4行:显示CPU当前的运行负载,有几核就有几行,我的是4核
Mem:显示内存的使用情况,3887M大概是3.8G,此时的Mem不包含buffers和cached的内存,所以和free -m会不同
Swp:显示交换空间的使用情况,交换空间是当内存不够和其中有一些长期不用的数据时,ubuntu会把这些暂时放到交换空间中
VIRT:virtual memory usage 虚拟内存
1、进程“需要的”虚拟内存大小,包括进程使用的库、代码、数据等
2、假如进程申请100m的内存,但实际只使用了10m,那么它会增长100m,而不是实际的使用量
RES:resident memory usage 常驻内存
1、进程当前使用的内存大小,但不包括swap out
2、包含其他进程的共享
3、如果申请100m的内存,实际使用10m,它只增长10m,与VIRT相反
4、关于库占用内存的情况,它只统计加载的库文件所占内存大小
SHR:shared memory 共享内存
1、除了自身进程的共享内存,也包括其他进程的共享内存
2、虽然进程只使用了几个共享库的函数,但它包含了整个共享库的大小
3、计算某个进程所占的物理内存大小公式:RES – SHR
4、swap out后,它将会降下来
DATA
1、数据占用的内存。如果top没有显示,按f键可以显示出来。
2、真正的该程序要求的数据空间,是真正在运行中要使用的。
top 运行中可以通过 top 的内部命令对进程的显示方式进行控制。内部命令如下:
s – 改变画面更新频率
l – 关闭或开启第一部分第一行 top 信息的表示
t – 关闭或开启第一部分第二行 Tasks 和第三行 Cpus 信息的表示
m – 关闭或开启第一部分第四行 Mem 和 第五行 Swap 信息的表示
N – 以 PID 的大小的顺序排列表示进程列表
P – 以 CPU 占用率大小的顺序排列进程列表
M – 以内存占用率大小的顺序排列进程列表
h – 显示帮助
n – 设置在进程列表所显示进程的数量
q – 退出 top
s – 改变画面更新周期
序号 列名 含义
a PID 进程id
b PPID 父进程id
c RUSER Real user name
d UID 进程所有者的用户id
e USER 进程所有者的用户名
f GROUP 进程所有者的组名
g TTY 启动进程的终端名。不是从终端启动的进程则显示为 ?
h PR 优先级
i NI nice值。负值表示高优先级,正值表示低优先级
j P 最后使用的CPU,仅在多CPU环境下有意义
k %CPU 上次更新到现在的CPU时间占用百分比
l TIME 进程使用的CPU时间总计,单位秒
m TIME+ 进程使用的CPU时间总计,单位1/100秒
n %MEM 进程使用的物理内存百分比
o VIRT 进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RES
p SWAP 进程使用的虚拟内存中,被换出的大小,单位kb。
q RES 进程使用的、未被换出的物理内存大小,单位kb。RES=CODE+DATA
r CODE 可执行代码占用的物理内存大小,单位kb
s DATA 可执行代码以外的部分(数据段+栈)占用的物理内存大小,单位kb
t SHR 共享内存大小,单位kb
u nFLT 页面错误次数
v nDRT 最后一次写入到现在,被修改过的页面数。
w S 进程状态。(D=不可中断的睡眠状态,R=运行,S=睡眠,T=跟踪/停止,Z=僵尸进程)
x COMMAND 命令名/命令行
y WCHAN 若该进程在睡眠,则显示睡眠中的系统函数名
z Flags 任务标志,参考 sched.h
默认情况下仅显示比较重要的 PID、USER、PR、NI、VIRT、RES、SHR、S、%CPU、%MEM、TIME+、COMMAND 列。可以通过下面的快捷键来更改显示内容。



1 | class Node_Heap{ |