在使用低版本的DataGrip的时候,还没有hive的data source,需要自行添加数据源
1.下载hive driver,如果你使用的EMR的大数据集群的话,下载地址
1 | https://docs.aws.amazon.com/emr/latest/ReleaseGuide/HiveJDBCDriver.html |
添加一个自定义的Driver and Data source
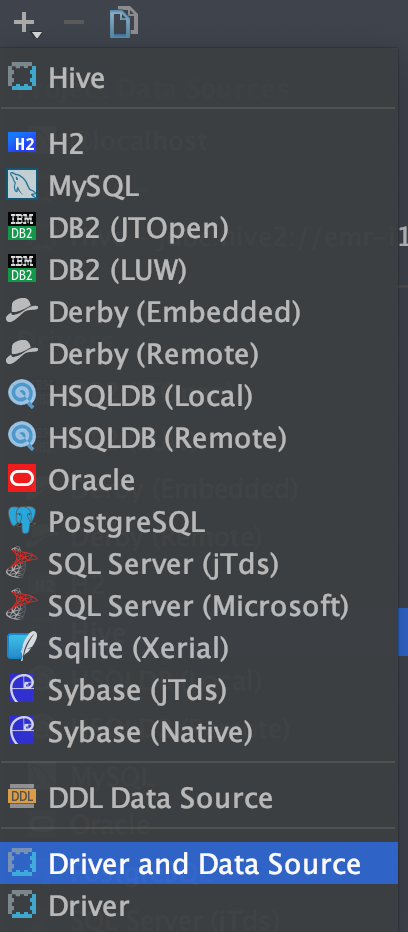
起名为Amazon Hive,并保存
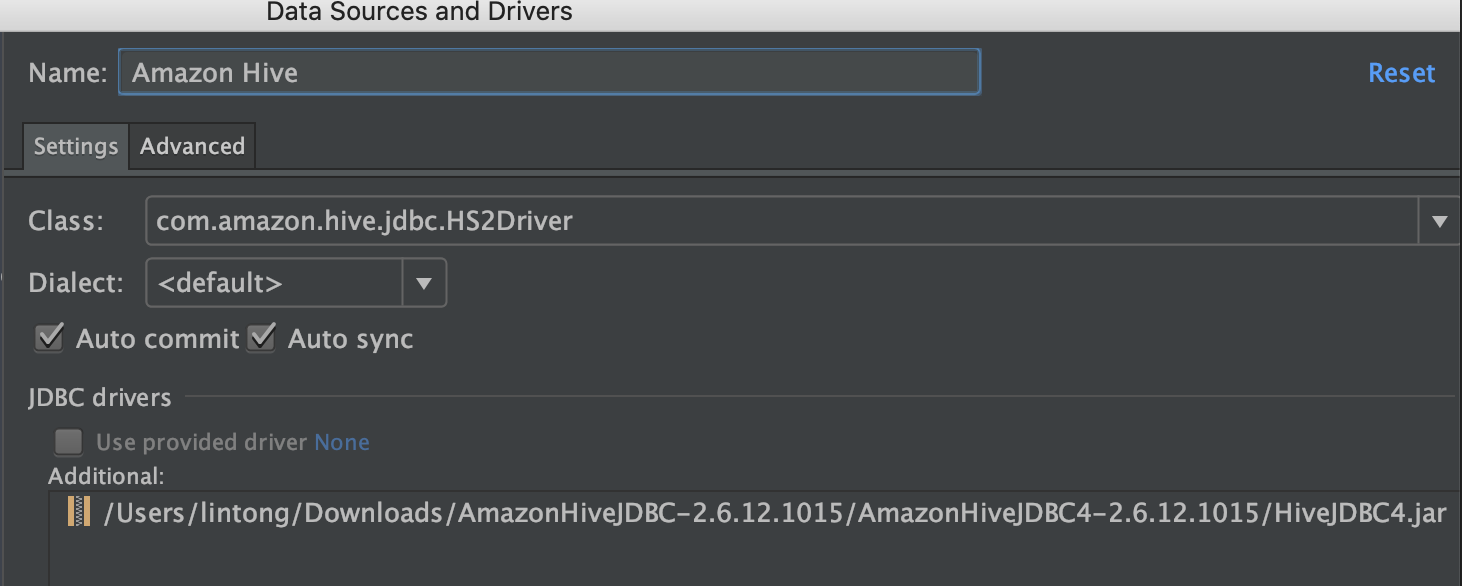
2.再添加一个Amazon Hive
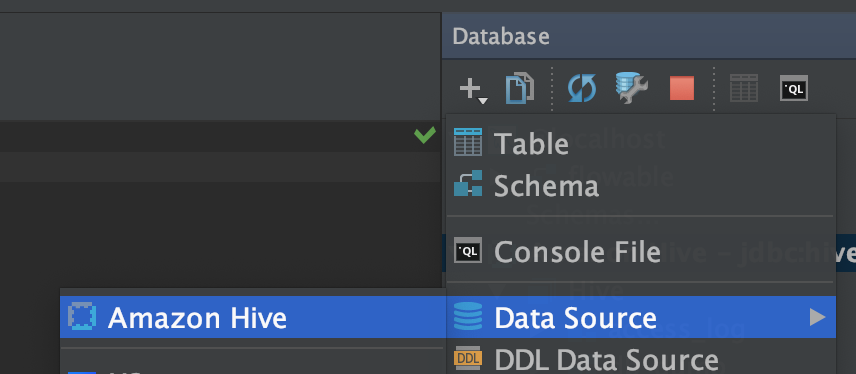
在使用低版本的DataGrip的时候,还没有hive的data source,需要自行添加数据源
1.下载hive driver,如果你使用的EMR的大数据集群的话,下载地址
1 | https://docs.aws.amazon.com/emr/latest/ReleaseGuide/HiveJDBCDriver.html |
添加一个自定义的Driver and Data source
起名为Amazon Hive,并保存
2.再添加一个Amazon Hive
参考kafka官方文档,版本1.0.x
1 | http://kafka.apache.org/10/documentation.html#consumerapi |
依赖,选择 Cloudera Rel 中的 1.0.1-kafka-3.1.0
1 | <dependency> |
Kafka的消费者有2套API,一个是新版的Java API,在 org.apache.kafka.clients 包中
1 | http://kafka.apache.org/10/documentation.html#newconsumerconfigs |
一个是旧版的Scala API,在 kafka.consumer 包中
1 | http://kafka.apache.org/10/documentation.html#oldconsumerconfigs |
其中new consumer api中文含义参考
1 | https://tonglin0325.github.io/xml/kafka/1.0.1-kafka-3.1.0/new-consumer-api.xml |
在Thrift,Protobuf和avro序列化框架中,不约而同使用了zigzag编码来对数字进行编码,从而达到减少数据传输量的目的。
zigzag算法的核心主要是去除二进制数字中的前导0,因为在绝大多数情况下,我们使用到的整数,往往是比较小的。

在avro编码中,对于字符串Martin,长度为6,而6的二进制为0000 0110,其中首位置的0为符号位,在zigzag编码中,正数的符号位会移动到末尾,其它位往前移动一位,所以会变成0000 1100,即0c,再后面的字节是字符串UTF-8编码后的结果
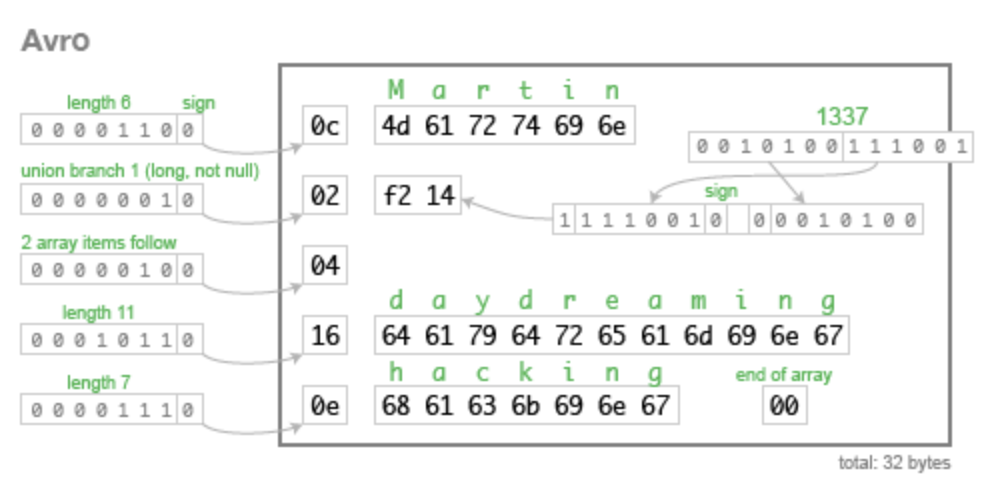
在protobuf编码中,对于字符串的Martin,刚开始的字节表示其id和数据类型,下一个字节表示其长度,后面的字节是字符串UTF-8编码后的结果
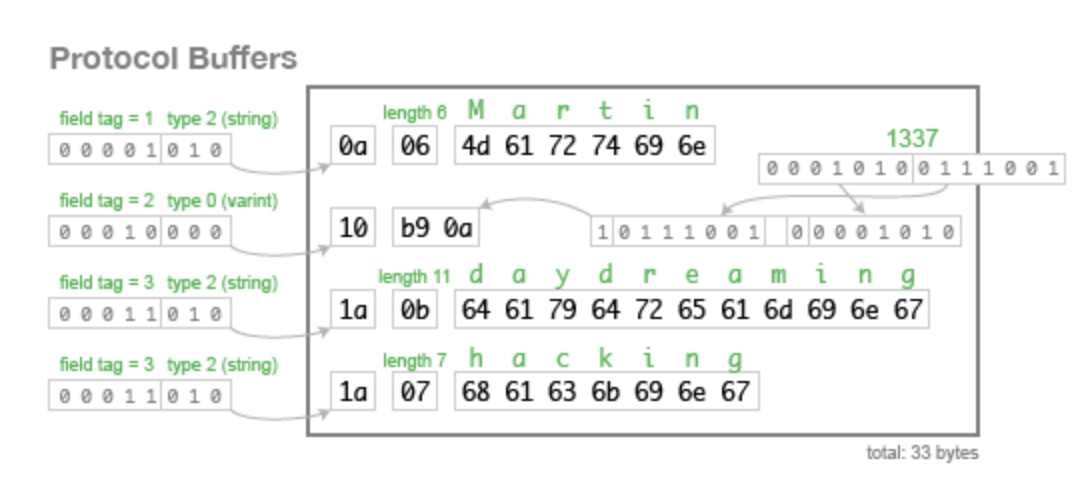
参考:《数据密集型应用系统设计》的 Schema evolution in Avro, Protocol Buffers and Thrift
该文章对比了常用的一些存储底层所使用的数据结构。
MySQL,MongoDB的索引使用的就是B+树
B+树在多读少写(相对而言)的情境下比较有优势。
B+树的主要优点:
B+树的缺点:
RocksDB,HBase,Cassandra,Kudu底层使用的是LSM树
LSM树的优点:
LSM树的缺点:
参考:LSM树由来、设计思想以及应用到HBase的索引 和 数据密集型应用系统设计第3章
Redis底层使用的是SkipTable
B+树是多叉树结构,每个结点都是一个16k的数据页,能存放较多索引信息,所以扇出很高。三层左右就可以存储2kw左右的数据(知道结论就行,想知道原因可以看之前的文章)。也就是说查询一次数据,如果这些数据页都在磁盘里,那么最多需要查询三次磁盘IO。
跳表是链表结构,一条数据一个结点,如果最底层要存放2kw数据,且每次查询都要能达到二分查找的效果,2kw大概在2的24次方左右,所以,跳表大概高度在24层左右。最坏情况下,这24层数据会分散在不同的数据页里,也即是查一次数据会经历24次磁盘IO。
因此存放同样量级的数据,B+树的高度比跳表的要少,如果放在mysql数据库上来说,就是磁盘IO次数更少,因此B+树查询更快。
参考
1 | https://dzone.com/articles/elasticsearch5-how-to-build-a-plugin-and-add-a-lis |
Es的插件主要有如下几种类型,参考
1 | https://github.com/elastic/elasticsearch/tree/master/server/src/main/java/org/elasticsearch/plugins |
API Extension Plugins API拓展插件:API extension plugins add new functionality to Elasticsearch by adding new APIs or features, usually to do with search or mapping.
Analysis Plugins 解析器插件:Analysis plugins extend Elasticsearch by adding new analyzers, tokenizers, token filters, or character filters to Elasticsearch.
Alerting Plugins 告警插件:Alerting plugins allow Elasticsearch to monitor indices and to trigger alerts when thresholds are breached.
Discovery Plugins 发现插件:Discovery plugins extend Elasticsearch by adding new discovery mechanisms that can be used instead of Zen Discovery.
Ingest Plugins 摄取插件:The ingest plugins extend Elasticsearch by providing additional ingest node capabilities.
在Airbnb的rowkey设计案例中,使用了hash法避免了写入热点问题,其中

Event_key标识了一条日志的唯一性,用于将来自Kafka的日志数据进行去重;
Shard_id是将Event_key进行hash(可以参考es的路由哈希算法Hashing.murmur3_128)之后,对Shard_num进行取余后的结果,Shard_num感觉应该是当前hbase表region server的总数,由于airbnb在hbase中存储的是实时日志数据,并开启了Hbase的TTL,所以当前hbase表中的数据总量应该是可预测的,即region server数量不会无限增加
Shard_key应该就是当前业务的region_start_keys+shard_id,比如当前业务分配的前缀为00000,同时规划了100个table regions给这个业务,即00-99,那么Shard_key的范围就是0000000-0000099
rowkey就是Shard_key.Event_key,比如0000000.air_events.canaryevent.016230-a3db-434e
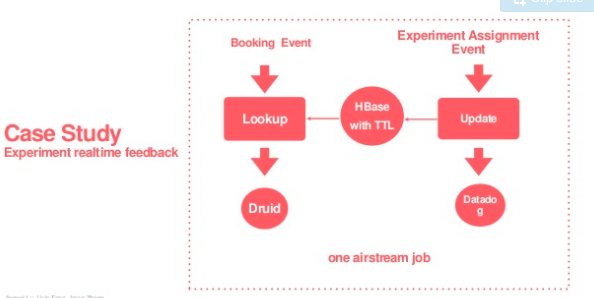
参考:
Reliable and Scalable Data Ingestion at Airbnb
Airbnb软件工程师丁辰 - Airbnb的Streaming ETL
1.rowkey长度原则:rowkey是一个二进制码流,可以是任意字符串,最大长度 64kb ,实际应用中一般为10-100bytes,以 byte[] 形式保存,一般设计成定长。
建议越短越好,不要超过16个字节,原因如下:
2.rowkey散列原则:如果rowkey按照时间戳的方式递增,不要将时间放在二进制码的前面,建议将rowkey的高位作为散列字段,由程序随机生成,低位放时间字段,这样将提高数据均衡分布在每个RegionServer,以实现负载均衡的几率。
如果没有散列字段,首字段直接是时间信息,所有的数据都会集中在一个RegionServer上,这样在数据检索的时候负载会集中在个别的RegionServer上,造成热点问题,会降低查询效率。
在美团点评的文章中,介绍了HiveSQL转化为MapReduce的过程
1 | 1、Antlr定义SQL的语法规则,完成SQL词法,语法解析,将SQL转化为抽象语法树AST Tree |
但是不是所有的SQL都有必要转换为MR来执行,比如
1 | select * from xx.xx limit 1 |
Hive只需要直接读取文件,并传输到控制台即可
在hive-default.xml配置文件中,有2个参数,hive.fetch.task.conversion和hive.fetch.task.conversion.threshold
hive.fetch.task.conversion属性修改为more以后,在全局查找、字段查找、limit查找等都不走mapreduce
hive.fetch.task.conversion.threshold属性表示在输入大小为多少以内的时候fetch task生效,默认1073741824 byte = 1G
1 | <property> |
参考:
前置条件是安装ik分词,请参考
1.在ik分词的config下添加词库文件
1 | ~/software/apache/elasticsearch-6.2.4/config/analysis-ik$ ls | grep mydic.dic |
内容为
1 | 我给祖国献石油 |
2.配置词库路径,编辑IKAnalyzer.cfg.xml配置文件,添加新增的词库
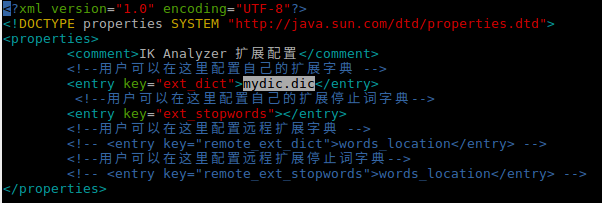
3.重启es
4.测试
Flink支持用户自定义 Functions,方法有2个
Ref
1 | https://ci.apache.org/projects/flink/flink-docs-release-1.12/zh/dev/user_defined_functions.html |
1 | class MyMapFunction implements MapFunction<String, Integer> { |
1 | class MyMapFunction extends RichMapFunction<String, Integer> { |
累加器和计数器
这个应该和Hadoop和Spark的counter类似,参考
1 | https://ci.apache.org/projects/flink/flink-docs-release-1.12/zh/dev/user_defined_functions.html#%E7%B4%AF%E5%8A%A0%E5%99%A8%E5%92%8C%E8%AE%A1%E6%95%B0%E5%99%A8 |
Flink有3中运行模式,分别是STREAMING,BATCH和AUTOMATIC
Ref
1 | https://ci.apache.org/projects/flink/flink-docs-release-1.12/zh/dev/datastream_execution_mode.html |
1.STREAMING运行模式 是DataStream默认的运行模式
2.BATCH运行模式 也可以在DataStream API上运行
3.AUTOMATIC运行模式 是让系统根据source类型自动选择运行模式
可以通过命令行来配置运行模式
1 | bin/flink run -Dexecution.runtime-mode=BATCH examples/streaming/WordCount.jar |
也可以在代码中配置
1 | StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); |
在STREAMING运行模式中,Flink使用StateBackend来控制状态存储和checkpoint的工作,RocksDBStateBackend支持增量Checkpoint,其他2个不支持
在BATCH****运行模式中,statebackend是被忽略的,batch模式不支持checkpoint
