Flume是一个分布式、可靠、和高可用的海量日志聚合的系统,支持在系统中定制各类数据发送方,用于收集数据;
同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
Flume是一个专门设计用来从大量的源,推送数据到Hadoop生态系统中各种各样存储系统中去的,例如HDFS和HBase。
Guide: http://flume.apache.org/FlumeUserGuide.html
体系架构
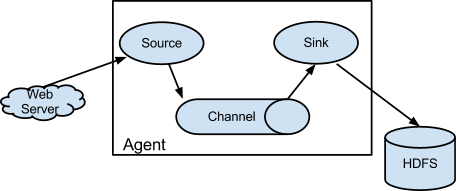
Flume的数据流由事件(Event)贯穿始终。事件是Flume的基本数据单位,它携带日志数据(字节数组形式)并且携带有头信息,这些Event由Agent外部的Source生成,当Source捕获事件后会进行特定的格式化,然后Source会把事件推入(单个或多个)Channel中。你可以把Channel看作是一个缓冲区,它将保存事件直到Sink处理完该事件。Sink负责持久化日志或者把事件推向另一个Source。
Flume以Flume Agent为最小的独立运行单位。一个Agent就是一个JVM。单agent由Source、Sink和Channel三大组件构成。一个Flume Agent可以连接一个或者多个其他的Flume Agent;一个Flume Agent也可以从一个或者多个Flume Agent接收数据。
注意:在Flume管道中如果有意想不到的错误、超时并进行了重试,Flume会产生重复的数据最终被被写入,后续需要处理这些冗余的数据。
具体可以参考文章:Flume教程(一) Flume入门教程
组件
Source:source是从一些其他产生数据的应用中接收数据的活跃组件。Source可以监听一个或者多个网络端口,用于接收数据或者可以从本地文件系统读取数据。每个Source必须至少连接一个Channel。基于一些标准,一个Source可以写入几个Channel,复制事件到所有或者某些Channel。
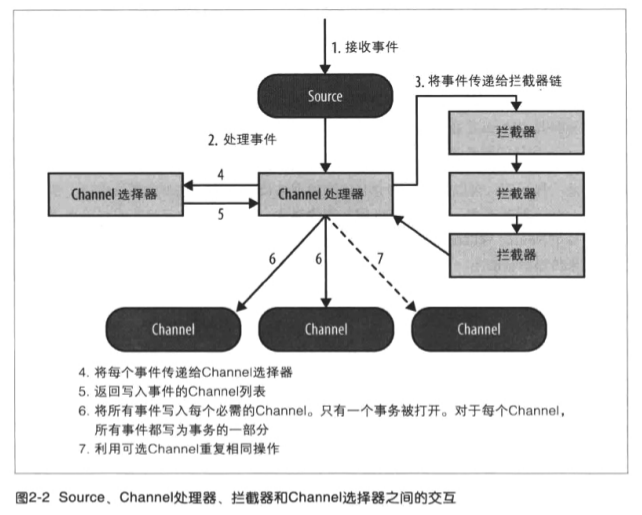
Source可以通过处理器 - 拦截器 - 选择器路由写入多个Channel。
Channel:channel的行为像队列,Source写入到channel,Sink从Channel中读取。多个Source可以安全地写入到相同的Channel,并且多个Sink可以从相同的Channel进行读取。
可是一个Sink只能从一个Channel读取。如果多个Sink从相同的Channel读取,它可以保证只有一个Sink将会从Channel读取一个指定特定的事件。
Flume自带两类Channel:Memory Channel和File Channel。Memory Channel的数据会在JVM或者机器重启后丢失;File Channel不会。
**Sink: **sink连续轮询各自的Channel来读取和删除事件。
拦截器:每次Source将数据写入Channel,它是通过委派该任务到其Channel处理器来完成,然后Channel处理器将这些事件传到一个或者多个Source配置的拦截器中。
拦截器是一段代码,基于某些标准,如正则表达式,拦截器可以用来删除事件,为事件添加新报头或者移除现有的报头等。每个Source可以配置成使用多个拦截器,按照配置中定义的顺序被调用,将拦截器的结果传递给链的下一个单元。一旦拦截器处理完事件,拦截器链返回的事件列表传递到Channel列表,即通过Channel选择器为每个事件选择的Channel。
全文 >>




