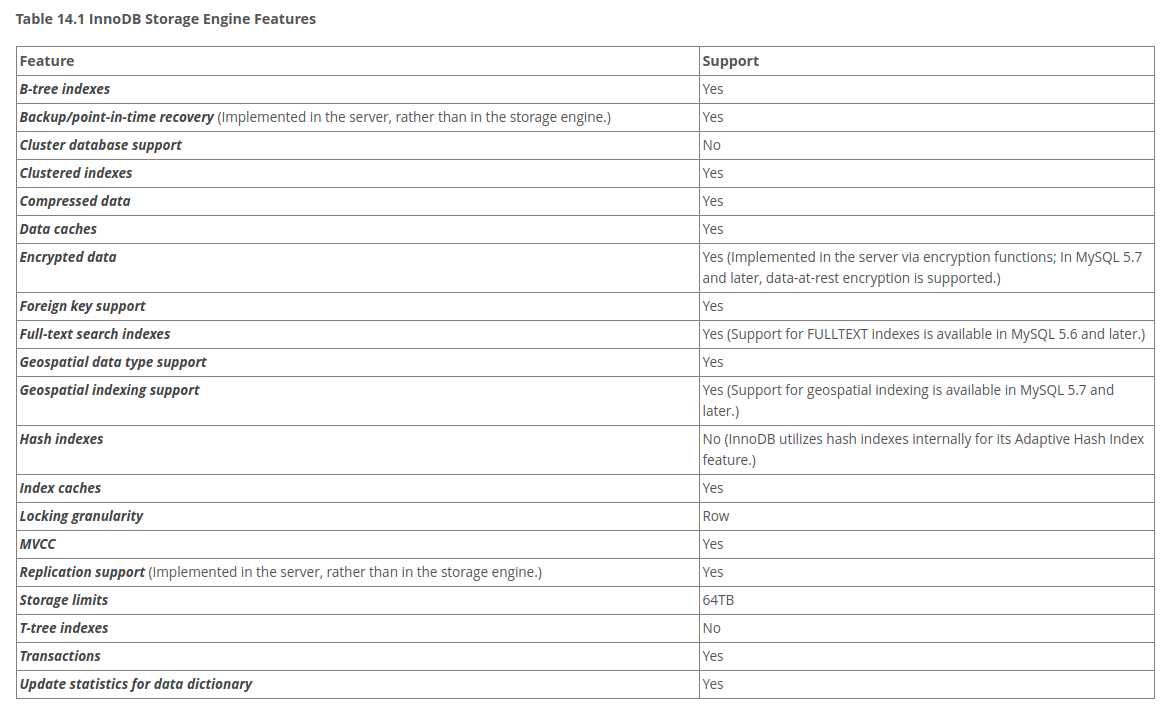
MySQL支持诸多存储引擎,而各种存储引擎对索引的支持也各不相同,因此MySQL数据库支持多种索引类型,如BTree索引,B+Tree索引,哈希索引,全文索引等等
不同存储引擎的索引类型 参考:
1 2 https://dev.mysql.com/doc/refman/5.7/en/create-index.html
InnoDB索引引擎的特性 参考:
1 2 https://dev.mysql.com/doc/refman/5.7/en/innodb-introduction.html
Innodb存储引擎使用的是B+树 为什么MySQL索引要用B+树,而不是B树?
mysql InnoDB引擎支持hash索引吗
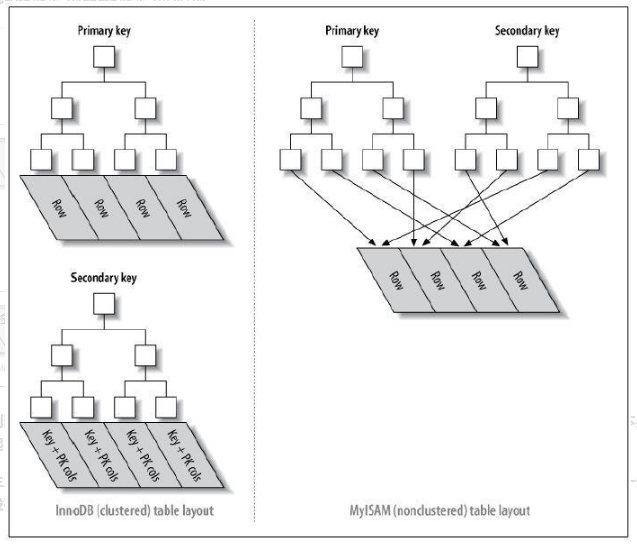
聚簇索引 和非聚簇索引 MySQL中最常见的两种存储引擎分别是MyISAM和InnoDB,分别实现了非聚簇索引和聚簇索引。
聚簇索引的解释是:聚簇索引的顺序就是数据的物理存储顺序
非聚簇索引的解释是:索引顺序与数据物理排列顺序无关
具体参考:深入理解MySQL索引原理和实现——为什么索引可以加速查询?
上图中的Secondary Key就是二级索引
参考:Mysql聚簇索引和二级索引到底有何不同
Innodb 和MyISAM 区别存储区别
MyISAM在磁盘上会存储3个文件:frm文件存储表定义,myd存储数据文件,myi存储索引文件
Innodb在磁盘上会存储2个文件:frm文件存储表定义,idb存储数据和索引文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 root@master:/var/lib/mysql/wherehows# ls cfg_application.frm flow_execution.frm FTS_00000000000001a5_CONFIG.ibd log_dataset_instance_load_status#P#P201609.ibd stg_flow_job.frm cfg_application.ibd flow_execution_id_map.frm FTS_00000000000001a5_DELETED_CACHE.ibd log_dataset_instance_load_status#P#P201610.ibd stg_flow_job.par cfg_cluster.frm flow_execution_id_map.par FTS_00000000000001a5_DELETED.ibd log_dataset_instance_load_status#P#P201611.ibd stg_flow_job#P#p0.ibd cfg_cluster.ibd flow_execution_id_map#P#p0.MYD FTS_00000000000001b1_BEING_DELETED_CACHE.ibd log_dataset_instance_load_status#P#P201612.ibd stg_flow_job#P#p1.ibd cfg_database.frm flow_execution_id_map#P#p0.MYI FTS_00000000000001b1_BEING_DELETED.ibd log_dataset_instance_load_status#P#P203507.ibd stg_flow_job#P#p2.ibd cfg_database.ibd flow_execution_id_map#P#p1.MYD FTS_00000000000001b1_CONFIG.ibd log_lineage_pattern.frm stg_flow_job#P#p3.ibd cfg_data_center.frm flow_execution_id_map#P#p1.MYI FTS_00000000000001b1_DELETED_CACHE.ibd log_lineage_pattern.ibd stg_flow_job#P#p4.ibd cfg_data_center.ibd flow_execution_id_map#P#p2.MYD FTS_00000000000001b1_DELETED.ibd log_reference_job_id_pattern.frm stg_flow_job#P#p5.ibd cfg_deployment_tier.frm flow_execution_id_map#P#p2.MYI FTS_0000000000000272_BEING_DELETED_CACHE.ibd log_reference_job_id_pattern.ibd stg_flow_job#P#p6.ibd cfg_deployment_tier.ibd flow_execution_id_map#P#p3.MYD FTS_0000000000000272_BEING_DELETED.ibd source_code_commit_info.frm stg_flow_job#P#p7.ibd cfg_job_type.frm flow_execution_id_map#P#p3.MYI FTS_0000000000000272_CONFIG.ibd source_code_commit_info.ibd stg_flow_owner_permission.frm cfg_job_type.ibd flow_execution_id_map#P#p4.MYD FTS_0000000000000272_DELETED_CACHE.ibd #sql-4312_14688.frm stg_flow_owner_permission.par cfg_job_type_reverse_map.frm flow_execution_id_map#P#p4.MYI FTS_0000000000000272_DELETED.ibd stg_cfg_object_name_map.frm stg_flow_owner_permission#P#p0.ibd cfg_job_type_reverse_map.ibd flow_execution_id_map#P#p5.MYD job_attempt_source_code.frm stg_cfg_object_name_map.ibd stg_flow_owner_permission#P#p1.ibd cfg_object_name_map.frm flow_execution_id_map#P#p5.MYI job_attempt_source_code.ibd stg_database_scm_map.frm stg_flow_owner_permission#P#p2.ibd cfg_object_name_map.ibd flow_execution_id_map#P#p6.MYD job_execution_data_lineage.frm stg_database_scm_map.ibd stg_flow_owner_permission#P#p3.ibd cfg_search_score_boost.frm flow_execution_id_map#P#p6.MYI job_execution_data_lineage.par stg_dataset_owner.frm stg_flow_owner_permission#P#p4.ibd cfg_search_score_boost.ibd flow_execution_id_map#P#p7.MYD job_execution_data_lineage#P#p0.ibd stg_dataset_owner.ibd stg_flow_owner_permission#P#p5.ibd comments.frm flow_execution_id_map#P#p7.MYI job_execution_data_lineage#P#p1.ibd stg_dataset_owner_unmatched.frm stg_flow_owner_permission#P#p6.ibd comments.ibd flow_execution.par job_execution_data_lineage#P#p2.ibd stg_dataset_owner_unmatched.ibd stg_flow_owner_permission#P#p7.ibd dataset_capacity.frm flow_execution#P#p0.ibd job_execution_data_lineage#P#p3.ibd stg_dict_dataset_field_comment.frm stg_flow.par dataset_capacity.ibd flow_execution#P#p1.ibd job_execution_data_lineage#P#p4.ibd stg_dict_dataset_field_comment.par stg_flow#P#p0.ibd dataset_case_sensitivity.frm flow_execution#P#p2.ibd job_execution_data_lineage#P#p5.ibd stg_dict_dataset_field_comment#P#p0.ibd stg_flow#P#p1.ibd dataset_case_sensitivity.ibd flow_execution#P#p3.ibd job_execution_data_lineage#P#p6.ibd stg_dict_dataset_field_comment#P#p1.ibd stg_flow#P#p2.ibd dataset_compliance.frm flow_execution#P#p4.ibd job_execution_data_lineage#P#p7.ibd stg_dict_dataset_field_comment#P#p2.ibd stg_flow#P#p3.ibd dataset_compliance.ibd flow_execution#P#p5.ibd job_execution_ext_reference.frm stg_dict_dataset_field_comment#P#p3.ibd stg_flow#P#p4.ibd dataset_constraint.frm flow_execution#P#p6.ibd job_execution_ext_reference.par stg_dict_dataset_field_comment#P#p4.ibd stg_flow#P#p5.ibd dataset_constraint.ibd flow_execution#P#p7.ibd job_execution_ext_reference#P#p0.ibd stg_dict_dataset_field_comment#P#p5.ibd stg_flow#P#p6.ibd dataset_deployment.frm flow.frm job_execution_ext_reference#P#p1.ibd stg_dict_dataset_field_comment#P#p6.ibd stg_flow#P#p7.ibd dataset_deployment.ibd flow_job.frm job_execution_ext_reference#P#p2.ibd stg_dict_dataset_field_comment#P#p7.ibd stg_flow_schedule.frm dataset_index.frm flow_job.par job_execution_ext_reference#P#p3.ibd stg_dict_dataset.frm stg_flow_schedule.par dataset_index.ibd flow_job#P#p0.ibd job_execution_ext_reference#P#p4.ibd stg_dict_dataset_instance.frm stg_flow_schedule#P#p0.ibd dataset_inventory.frm flow_job#P#p1.ibd job_execution_ext_reference#P#p5.ibd stg_dict_dataset_instance.par stg_flow_schedule#P#p1.ibd dataset_inventory.ibd flow_job#P#p2.ibd job_execution_ext_reference#P#p6.ibd stg_dict_dataset_instance#P#p0.ibd stg_flow_schedule#P#p2.ibd dataset_owner.frm flow_job#P#p3.ibd job_execution_ext_reference#P#p7.ibd stg_dict_dataset_instance#P#p1.ibd stg_flow_schedule#P#p3.ibd dataset_owner.ibd flow_job#P#p4.ibd job_execution.frm stg_dict_dataset_instance#P#p2.ibd stg_flow_schedule#P#p4.ibd dataset_partition.frm flow_job#P#p5.ibd job_execution_id_map.frm stg_dict_dataset_instance#P#p3.ibd stg_flow_schedule#P#p5.ibd dataset_partition.ibd flow_job#P#p6.ibd job_execution_id_map.par stg_dict_dataset_instance#P#p4.ibd stg_flow_schedule#P#p6.ibd dataset_partition_layout_pattern.frm flow_job#P#p7.ibd job_execution_id_map#P#p0.MYD stg_dict_dataset_instance#P#p5.ibd stg_flow_schedule#P#p7.ibd dataset_partition_layout_pattern.ibd flow_owner_permission.frm job_execution_id_map#P#p0.MYI stg_dict_dataset_instance#P#p6.ibd stg_git_project.frm dataset_privacy_compliance.frm flow_owner_permission.par job_execution_id_map#P#p1.MYD stg_dict_dataset_instance#P#p7.ibd stg_git_project.ibd dataset_privacy_compliance.ibd flow_owner_permission#P#p0.ibd job_execution_id_map#P#p1.MYI stg_dict_dataset.par stg_job_execution_data_lineage.frm dataset_reference.frm flow_owner_permission#P#p1.ibd job_execution_id_map#P#p2.MYD stg_dict_dataset#P#p0.ibd stg_job_execution_data_lineage.ibd dataset_reference.ibd flow_owner_permission#P#p2.ibd job_execution_id_map#P#p2.MYI stg_dict_dataset#P#p1.ibd stg_job_execution_ext_reference.frm dataset_schema_info.frm flow_owner_permission#P#p3.ibd job_execution_id_map#P#p3.MYD stg_dict_dataset#P#p2.ibd stg_job_execution_ext_reference.par dataset_schema_info.ibd flow_owner_permission#P#p4.ibd job_execution_id_map#P#p3.MYI stg_dict_dataset#P#p3.ibd stg_job_execution_ext_reference#P#p0.ibd dataset_security.frm flow_owner_permission#P#p5.ibd job_execution_id_map#P#p4.MYD stg_dict_dataset#P#p4.ibd stg_job_execution_ext_reference#P#p1.ibd dataset_security.ibd flow_owner_permission#P#p6.ibd job_execution_id_map#P#p4.MYI stg_dict_dataset#P#p5.ibd stg_job_execution_ext_reference#P#p2.ibd dataset_tag.frm flow_owner_permission#P#p7.ibd job_execution_id_map#P#p5.MYD stg_dict_dataset#P#p6.ibd stg_job_execution_ext_reference#P#p3.ibd dataset_tag.ibd flow.par job_execution_id_map#P#p5.MYI stg_dict_dataset#P#p7.ibd stg_job_execution_ext_reference#P#p4.ibd db.opt flow#P#p0.ibd job_execution_id_map#P#p6.MYD stg_dict_dataset_sample.frm stg_job_execution_ext_reference#P#p5.ibd dict_business_metric.frm flow#P#p1.ibd job_execution_id_map#P#p6.MYI stg_dict_dataset_sample.ibd stg_job_execution_ext_reference#P#p6.ibd dict_business_metric.ibd flow#P#p2.ibd job_execution_id_map#P#p7.MYD stg_dict_field_detail.frm stg_job_execution_ext_reference#P#p7.ibd dict_dataset_field_comment.frm flow#P#p3.ibd job_execution_id_map#P#p7.MYI stg_dict_field_detail.par stg_job_execution.frm dict_dataset_field_comment.ibd flow#P#p4.ibd job_execution.par stg_dict_field_detail#P#p0.ibd stg_job_execution.par dict_dataset.frm flow#P#p5.ibd job_execution#P#p0.ibd stg_dict_field_detail#P#p1.ibd stg_job_execution#P#p0.ibd dict_dataset.ibd flow#P#p6.ibd job_execution#P#p1.ibd stg_dict_field_detail#P#p2.ibd stg_job_execution#P#p1.ibd dict_dataset_instance.frm flow#P#p7.ibd job_execution#P#p2.ibd stg_dict_field_detail#P#p3.ibd stg_job_execution#P#p2.ibd dict_dataset_instance.par flow_schedule.frm job_execution#P#p3.ibd stg_dict_field_detail#P#p4.ibd stg_job_execution#P#p3.ibd dict_dataset_instance#P#p0.ibd flow_schedule.par job_execution#P#p4.ibd stg_dict_field_detail#P#p5.ibd stg_job_execution#P#p4.ibd dict_dataset_instance#P#p1.ibd flow_schedule#P#p0.ibd job_execution#P#p5.ibd stg_dict_field_detail#P#p6.ibd stg_job_execution#P#p5.ibd dict_dataset_instance#P#p2.ibd flow_schedule#P#p1.ibd job_execution#P#p6.ibd stg_dict_field_detail#P#p7.ibd stg_job_execution#P#p6.ibd dict_dataset_instance#P#p3.ibd flow_schedule#P#p2.ibd job_execution#P#p7.ibd stg_flow_dag_edge.frm stg_job_execution#P#p7.ibd dict_dataset_instance#P#p4.ibd flow_schedule#P#p3.ibd job_execution_script.frm stg_flow_dag_edge.par stg_kafka_gobblin_compaction.frm dict_dataset_instance#P#p5.ibd flow_schedule#P#p4.ibd job_execution_script.ibd stg_flow_dag_edge#P#p0.ibd stg_kafka_gobblin_compaction.ibd dict_dataset_instance#P#p6.ibd flow_schedule#P#p5.ibd job_source_id_map.frm stg_flow_dag_edge#P#p1.ibd stg_kafka_gobblin_distcp.frm dict_dataset_instance#P#p7.ibd flow_schedule#P#p6.ibd job_source_id_map.par stg_flow_dag_edge#P#p2.ibd stg_kafka_gobblin_distcp.ibd dict_dataset_sample.frm flow_schedule#P#p7.ibd job_source_id_map#P#p0.MYD stg_flow_dag_edge#P#p3.ibd stg_kafka_gobblin_lumos.frm dict_dataset_sample.ibd flow_source_id_map.frm job_source_id_map#P#p0.MYI stg_flow_dag_edge#P#p4.ibd stg_kafka_gobblin_lumos.ibd dict_dataset_schema_history.frm flow_source_id_map.par job_source_id_map#P#p1.MYD stg_flow_dag_edge#P#p5.ibd stg_kafka_metastore_audit.frm dict_dataset_schema_history.ibd flow_source_id_map#P#p0.MYD job_source_id_map#P#p1.MYI stg_flow_dag_edge#P#p6.ibd stg_kafka_metastore_audit.ibd dict_field_detail.frm flow_source_id_map#P#p0.MYI job_source_id_map#P#p2.MYD stg_flow_dag_edge#P#p7.ibd stg_product_repo.frm dict_field_detail.ibd flow_source_id_map#P#p1.MYD job_source_id_map#P#p2.MYI stg_flow_dag.frm stg_product_repo.ibd dir_external_group_user_map.frm flow_source_id_map#P#p1.MYI job_source_id_map#P#p3.MYD stg_flow_dag.par stg_repo_owner.frm dir_external_group_user_map.ibd flow_source_id_map#P#p2.MYD job_source_id_map#P#p3.MYI stg_flow_dag#P#p0.ibd stg_repo_owner.ibd dir_external_user_info.frm flow_source_id_map#P#p2.MYI job_source_id_map#P#p4.MYD stg_flow_dag#P#p1.ibd stg_source_code_commit_info.frm dir_external_user_info.ibd flow_source_id_map#P#p3.MYD job_source_id_map#P#p4.MYI stg_flow_dag#P#p2.ibd stg_source_code_commit_info.ibd favorites.frm flow_source_id_map#P#p3.MYI job_source_id_map#P#p5.MYD stg_flow_dag#P#p3.ibd track_object_access_log.frm favorites.ibd flow_source_id_map#P#p4.MYD job_source_id_map#P#p5.MYI stg_flow_dag#P#p4.ibd track_object_access_log.ibd field_comments.frm flow_source_id_map#P#p4.MYI job_source_id_map#P#p6.MYD stg_flow_dag#P#p5.ibd user_login_history.frm field_comments.ibd flow_source_id_map#P#p5.MYD job_source_id_map#P#p6.MYI stg_flow_dag#P#p6.ibd user_login_history.ibd filename_pattern.frm flow_source_id_map#P#p5.MYI job_source_id_map#P#p7.MYD stg_flow_dag#P#p7.ibd user_settings.frm filename_pattern.ibd flow_source_id_map#P#p6.MYD job_source_id_map#P#p7.MYI stg_flow_execution.frm user_settings.ibd flow_dag.frm flow_source_id_map#P#p6.MYI log_dataset_instance_load_status.frm stg_flow_execution.par users.frm flow_dag.par flow_source_id_map#P#p7.MYD log_dataset_instance_load_status.par stg_flow_execution#P#p0.ibd users.ibd flow_dag#P#p0.ibd flow_source_id_map#P#p7.MYI log_dataset_instance_load_status#P#P201601.ibd stg_flow_execution#P#p1.ibd watch.frm flow_dag#P#p1.ibd FTS_0000000000000184_BEING_DELETED_CACHE.ibd log_dataset_instance_load_status#P#P201602.ibd stg_flow_execution#P#p2.ibd watch.ibd flow_dag#P#p2.ibd FTS_0000000000000184_BEING_DELETED.ibd log_dataset_instance_load_status#P#P201603.ibd stg_flow_execution#P#p3.ibd wh_etl_job_history.frm flow_dag#P#p3.ibd FTS_0000000000000184_CONFIG.ibd log_dataset_instance_load_status#P#P201604.ibd stg_flow_execution#P#p4.ibd wh_etl_job_history.ibd flow_dag#P#p4.ibd FTS_0000000000000184_DELETED_CACHE.ibd log_dataset_instance_load_status#P#P201605.ibd stg_flow_execution#P#p5.ibd wh_etl_job_schedule.frm flow_dag#P#p5.ibd FTS_0000000000000184_DELETED.ibd log_dataset_instance_load_status#P#P201606.ibd stg_flow_execution#P#p6.ibd wh_etl_job_schedule.ibd flow_dag#P#p6.ibd FTS_00000000000001a5_BEING_DELETED_CACHE.ibd log_dataset_instance_load_status#P#P201607.ibd stg_flow_execution#P#p7.ibd flow_dag#P#p7.ibd FTS_00000000000001a5_BEING_DELETED.ibd log_dataset_instance_load_status#P#P201608.ibd stg_flow.frm
锁区别
MyISAM存储引擎使用的是表锁,Innodb存储引擎默认使用的是行锁,同时也支持表级锁
参考:【一分钟系列】一分钟快速了解MyISAM和Innodb的主要区别
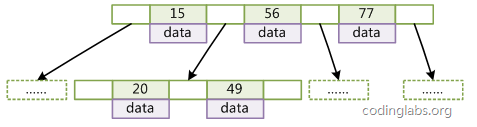
B树
BTree是平衡搜索多叉树,设树的度为2d(d>1),高度为h,那么BTree要满足以一下条件:
每个叶子结点的高度一样,等于h;
每个非叶子结点由n-1个key和n个指针point组成,其中d<=n<=2d,key和point相互间隔,结点两端一定是key;
叶子结点指针都为null;
非叶子结点的key都是[key,data]二元组,其中key表示作为索引的键,data为键值所在行的数据;
在BTree的结构下,就可以使用二分查找的查找方式,查找复杂度为h*log(n),一般来说树的高度是很小的,一般为3左右,因此BTree是一个非常高效的查找结构。
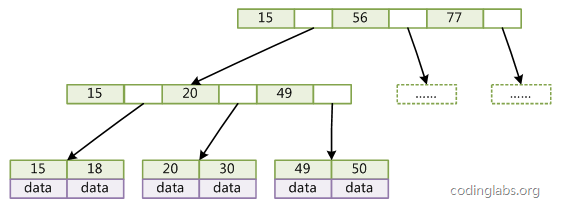
B+树
B+Tree是BTree的一个变种,设d为树的度数,h为树的高度,B+Tree和BTree的不同主要在于:
B+Tree中的非叶子结点不存储数据,只存储键值;
B+Tree的叶子结点没有指针,所有键值都会出现在叶子结点上,且key存储的键值对应data数据的物理地址;
B+Tree的每个非叶子节点由n个键值key和n个指针point组成;
B+Tree对比BTree的优点 1、磁盘读写代价更低
一般来说B+Tree比BTree更适合实现外存的索引结构,因为存储引擎的设计专家巧妙的利用了外存(磁盘)的存储结构,即磁盘的最小存储单位是扇区(sector),而操作系统的块(block)通常是整数倍的sector,操作系统以页(page)为单位管理内存,一页(page)通常默认为4K,数据库的页通常设置为操作系统页的整数倍,因此索引结构的节点被设计为一个页的大小,然后利用外存的“预读取”原则,每次读取的时候,把整个节点的数据读取到内存中,然后在内存中查找,已知内存的读取速度是外存读取I/O速度的几百倍,那么提升查找速度的关键就在于尽可能少的磁盘I/O,那么可以知道,每个节点中的key个数越多,那么树的高度越小,需要I/O的次数越少,因此一般来说B+Tree比BTree更快,因为B+Tree的非叶节点中不存储data,就可以存储更多的key。
2、查询速度更稳定
由于B+Tree非叶子节点不存储数据(data),因此所有的数据都要查询至叶子节点,而叶子节点的高度都是相同的,因此所有数据的查询速度都是一样的。