# ========= Describe the channel ============= # Use a channel which buffers events in memory agent.channels.c1.type = memory agent.channels.c1.capacity = 100000 agent.channels.c1.transactionCapacity = 1000
# ========= Describe the channel ============= # Use a channel which buffers events in memory agent.channels.c1.type = memory agent.channels.c1.capacity = 100000 agent.channels.c1.transactionCapacity = 1000
# ========= Describe the channel ============= # Use a channel which buffers events in memory agent.channels.c1.type = memory agent.channels.c1.capacity = 100000 agent.channels.c1.transactionCapacity = 1000
# ========= Describe the sink ============= agent.sinks.s1.type = org.apache.flume.sink.kafka.KafkaSink agent.sinks.s1.topic = test agent.sinks.s1.brokerList = localhost:9092 # 避免死循环 agent.sinks.s1.allowTopicOverride = false
# ========= Bind the source and sink to the channel ============= agent.sources.r1.channels = c1 agent.sinks.s1.channel = c1 #agent.sinks.s2.channel = c1
# ========= Name the components on this agent ========= agent.sources = r1 agent.channels = c1 agent.sinks = s1 s2
# ========= Describe the source ============= agent.sources.r1.type=http agent.sources.r1.bind=localhost agent.sources.r1.port=50000 agent.sources.r1.channels=c1
# ========= Describe the channel ============= # Use a channel which buffers events in memory agent.channels.c1.type = memory agent.channels.c1.capacity = 100000 agent.channels.c1.transactionCapacity = 1000
# ========= Bind the source and sink to the channel ============= agent.sources.r1.channels = c1 agent.sinks.s1.channel = c1 #agent.sinks.s2.channel = c1
# Licensed to the Apache Software Foundation (ASF) under one # or more contributor license agreements. See the NOTICE file # distributed with this work for additional information # regarding copyright ownership. The ASF licenses this file # to you under the Apache License, Version 2.0 (the # "License"); you may not use this file except in compliance # with the License. You may obtain a copy of the License at # # http://www.apache.org/licenses/LICENSE-2.0 # # Unless required by applicable law or agreed to in writing, # software distributed under the License is distributed on an # "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY # KIND, either express or implied. See the License for the # specific language governing permissions and limitations # under the License.
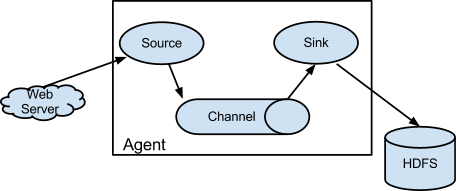
# The configuration file needs to define the sources, # the channels and the sinks. # Sources, channels and sinks are defined per agent, # in this case called 'agent'
# ========= Name the components on this agent ========= agent.sources = r1 agent.channels = c1 agent.sinks = s1 agent.sources.r1.interceptors = i1
org.apache.flume.ChannelException: Take list for MemoryTransaction, capacity 1000 full, consider committing more frequently, increasing capacity, or increasing thread count
可以将内存channel改成file channel或者改成kafka channel
当换成kafka channel的时候,数据量大的时候,依然会问题
1 2 3 4 5
16:07:48.615 ERROR org.apache.kafka.clients.consumer.internals.ConsumerCoordinator:550 - Error ILLEGAL_GENERATION occurred while committing offsets for group flume 16:07:48.617 ERROR org.apache.flume.source.kafka.KafkaSource:317 - KafkaSource EXCEPTION, {} org.apache.kafka.clients.consumer.CommitFailedException: Commit cannot be completed due to group rebalance at org.apache.kafka.clients.consumer.internals.ConsumerCoordinator$OffsetCommitResponseHandler.handle(ConsumerCoordinator.java:552)
或者
1 2
ERROR org.apache.kafka.clients.consumer.internals.ConsumerCoordinator:550 - Error UNKNOWN_MEMBER_ID occurred while committing offsets for group flume