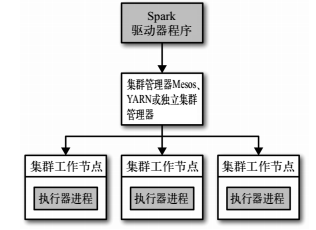
Spark运行的时候,采用的是主从结构,有一个节点负责中央协调, 调度各个分布式工作节点。这个中央协调节点被称为驱动器( Driver) 节点。与之对应的工作节点被称为执行器( executor) 节点。
所有的 Spark 程序都遵循同样的结构:程序从输入数据创建一系列 RDD, 再使用转化操作派生出新的 RDD,最后使用行动操作收集或存储结果 RDD 中的数据。
1.驱动器节点:
Spark 驱动器是执行你的程序中的 main() 方法的进程。它执行用户编写的用来创建 SparkContext、创建 RDD,以及进行 RDD 的转化操作和行动操作的代码。其实,当你启动 Spark shell 时,你就启动了一个 Spark 驱动器程序
驱动器程序在 Spark 应用中有下述两个职责:1.把用户程序转为任务 2.为执行器节点调度任务
2.执行器节点:
Spark 执行器节点是一种工作进程,负责在 Spark 作业中运行任务,任务间相互独立。 Spark 应用启动时, 执行器节点就被同时启动,并且始终伴随着整个 Spark 应用的生命周期而存在。
执行器进程有两大作用: 第一,它们负责运行组成 Spark 应用的任务,并将结果返回给驱动器进程; 第二,它们通过自身的块管理器(Block Manager)为用户程序中要求缓存的 RDD 提供内存式存储。
3.集群管理器:
驱动器节点和执行器节点是如何启动的呢? Spark 依赖于集群管理器来启动执行器节点,而在某些特殊情况下,也依赖集群管理器来启动驱动器节点。
Spark架构

1 | http://spark.apache.org/docs/latest/cluster-overview.html |
转自
1 | https://zhuanlan.zhihu.com/p/91143069 |
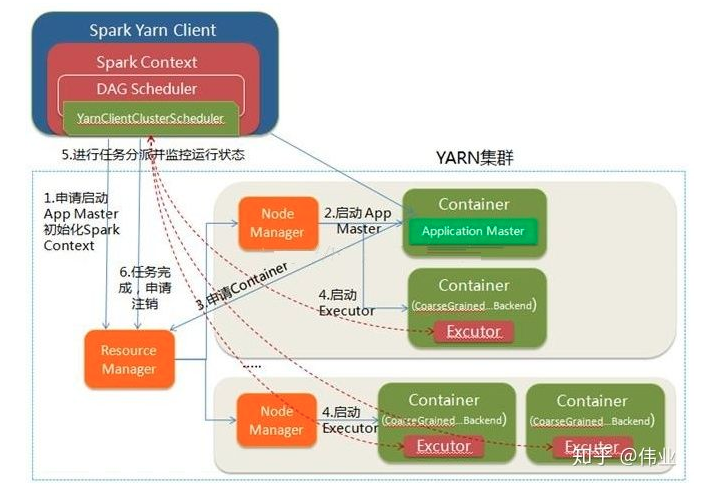
yarn-client 适用于交互、调试,希望立即看到app的输出
yarn-cluster 适用于生产环境

参考:
yarn-cluster和yarn-client提交模式的区别
