许多应用需要即时处理收到的数据,例如用来实时追踪页面访问统计的应用、训练机器学习模型的应用, 还有自动检测异常的应用。Spark Streaming 是 Spark 为这些应用而设计的模型。它允许用户使用一套和批处理非常接近的 API 来编写流式计算应用,这样就可以大量重用批处理应用的技术甚至代码。
Spark Streaming 使用离散化流( discretized stream)作为抽象表示, 叫作 DStream。 DStream 是随时间推移而收到的数据的序列。在内部,每个时间区间收到的数据都作为 RDD 存在,而 DStream 是由这些 RDD 所组成的序列(因此得名“离散化”)。DStream 可以从各种输入源创建,比如 Flume、 Kafka 或者 HDFS。创建出来的 DStream 支持两种操作,一种是转化操作( transformation) ,会生成一个新的DStream,另一种是输出操作( output operation),可以把数据写入外部系统中。DStream提供了许多与 RDD 所支持的操作相类似的操作支持,还增加了与时间相关的新操作,比如滑动窗口。
build.sbt
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| name := "spark-first"
version := "1.0"
scalaVersion := "2.11.8"
libraryDependencies ++= Seq(
"org.apache.spark" % "spark-core_2.11" % "2.1.0",
"org.apache.hadoop" % "hadoop-common" % "2.7.2",
"mysql" % "mysql-connector-java" % "5.1.31",
"org.apache.spark" %% "spark-sql" % "2.1.0",
"org.apache.spark" %% "spark-streaming" % "2.1.0"
)
|
代码,使用Spark Streaming对端口发过来的数据进行词频统计
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
| import org.apache.hadoop.io.{IntWritable, LongWritable, MapWritable, Text}
import org.apache.spark.SparkContext
import org.apache.spark.SparkConf
import org.apache.spark._
import org.apache.spark.streaming.StreamingContext
import org.apache.spark.streaming.StreamingContext._
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.Duration
import org.apache.spark.streaming.Seconds
/**
* Created by common on 17-4-6.
*/
object SparkRDD {
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("WordCount").setMaster("local")
// Spark streaming
// 从SparkConf创建StreamingContext并指定1秒钟的批处理大小
val ssc = new StreamingContext(conf, Seconds(1))
// 连接到本地机器7777端口上后,使用收到的数据创建DStream
val lines = ssc.socketTextStream("localhost", 7777)
// 对每一行数据执行Split操作
val words = lines.flatMap(_.split(" "))
// 统计word的数量
val pairs = words.map(word => (word, 1))
val wordCounts = pairs.reduceByKey(_ + _)
// 输出结果
wordCounts.print()
ssc.start() // 开始
ssc.awaitTermination() // 计算完毕退出
}
}
|
首先在终端中运行命令,向7777端口发送数据
nc命令参数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| -g<网关>:设置路由器跃程通信网关,最多设置8个;
-G<指向器数目>:设置来源路由指向器,其数值为4的倍数;
-h:在线帮助;
-i<延迟秒数>:设置时间间隔,以便传送信息及扫描通信端口;
-l:使用监听模式,监控传入的资料;
-n:直接使用ip地址,而不通过域名服务器;
-o<输出文件>:指定文件名称,把往来传输的数据以16进制字码倾倒成该文件保存;
-p<通信端口>:设置本地主机使用的通信端口;
-r:指定源端口和目的端口都进行随机的选择;
-s<来源位址>:设置本地主机送出数据包的IP地址;
-u:使用UDP传输协议;
-v:显示指令执行过程;
-w<超时秒数>:设置等待连线的时间;
-z:使用0输入/输出模式,只在扫描通信端口时使用。
|
然后运行Spark Streaming程序
接着在终端中输入
1
2
3
| Hello World 1 #回车
Hello World 2
|
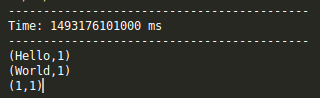
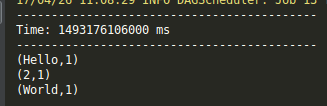
中断程序,在Spark Streaming输出看见
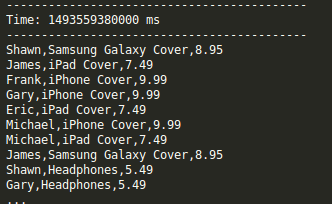
也可以自己创建一个网络连接,并随机生成一些数据病通过这个连接发送出去。
注意下面的测试文件应该放在class目录下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
| import java.io.PrintWriter
import java.net.ServerSocket
import scala.util.Random
/**
* Created by common on 17-4-30.
*/
object StreamingProducer {
def main(args: Array[String]) {
val random = new Random()
// 每秒最大活动数
val MaxEvents = 6
// 读取可能的名称
val namesResource =
this.getClass.getResourceAsStream("/name.csv")
val names = scala.io.Source.fromInputStream(namesResource)
.getLines()
.toList
.head
.split(",")
.toSeq
// 生成一系列可能的产品
val products = Seq(
"iPhone Cover" -> 9.99,
"Headphones" -> 5.49,
"Samsung Galaxy Cover" -> 8.95,
"iPad Cover" -> 7.49
)
/** 生成随机产品活动 */
def generateProductEvents(n: Int) = {
(1 to n).map { i =>
val (product, price) = products(random.nextInt(products.size))
val user = random.shuffle(names).head
(user, product, price)
}
}
// 创建网络生成器
val listener = new ServerSocket(9999)
println("Listening on port: 9999")
while (true) {
val socket = listener.accept()
new Thread() {
override def run = {
println("Got client connected from: " +
socket.getInetAddress)
val out = new PrintWriter(socket.getOutputStream(), true)
while (true) {
Thread.sleep(1000)
val num = random.nextInt(MaxEvents)
// 用户和产品活动的随机组合
val productEvents = generateProductEvents(num)
// 向端口发送数据
productEvents.foreach { event =>
out.write(event.productIterator.mkString(","))
out.write("\n")
}
// 清空缓存
out.flush()
println(s"Created $num events...")
}
socket.close()
}
}.start()
}
}
}
|
流处理程序代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* Created by common on 17-4-30.
*/
object SimpleStreamingApp {
def main(args: Array[String]) {
// 每隔10秒触发一次计算,使用了print算子
val ssc = new StreamingContext("local[2]",
"First Streaming App", Seconds(10))
val stream = ssc.socketTextStream("localhost", 9999)
// 简单地打印每一批的前几个元素
// 批量运行
stream.print()
ssc.start()
ssc.awaitTermination()
}
}
|