1.RDD——弹性分布式数据集(Resilient Distributed Dataset)
RDD是一个分布式的元素集合,在Spark中,对数据的操作就是创建RDD 、转换已有的RDD 和调用RDD操作进行求值 。
Spark 中的 RDD 就是一个不可变的分布式对象集合。每个 RDD 都被分为多个分区,这些分区运行在集群中的不同节点上。
1 2 3 4 5 6 7 8 9 10 11 object WordCount { def main(args: Array[String]) { val inputFile = "file:///home/common/coding/coding/Scala/word-count/test.segmented" val conf = new SparkConf().setAppName("WordCount").setMaster("local") #创建一个SparkConf对象来配置应用<br> #集群URL:告诉Spark连接到哪个集群,local是单机单线程,无需连接到集群,应用名:在集群管理器的用户界面方便找到应用 val sc = new SparkContext(conf) #然后基于这SparkConf创建一个SparkContext对象 val textFile = sc.textFile(inputFile) #读取输入的数据 val wordCount = textFile.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey((a, b) => a + b) #切分成单词,转换成键值对并计数 wordCount.foreach(println) } }
创建一个RDD
1 2 val textFile = sc.textFile(inputFile)
或者
1 2 val lines = sc.parallelize(List("pandas", "i like pandas"))
RDD支持两种类型的操作: **转化操作(transformation)和 行动操作(action)**。
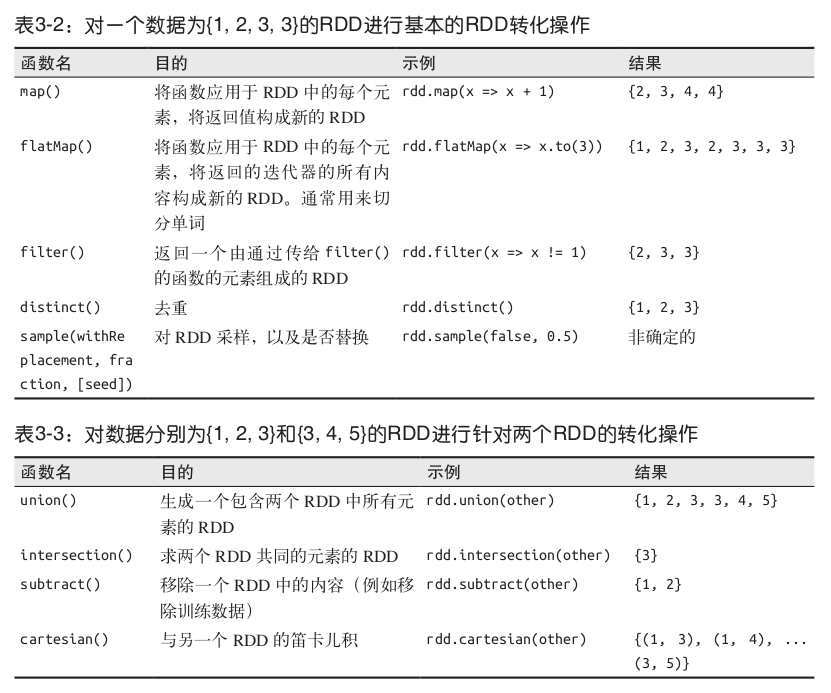
转化操作,是返回一个新的RDD的操作:
filter()函数
1 2 val RDD = textFile.filter(line => line.contains("Hadoop"))
map()函数
1 2 3 4 val input = sc.parallelize(List(1, 2, 3, 4)) val result = input.map(x => x * x) println(result.collect().mkString(","))
输出
map()和flatMap()的区别
1 2 3 4 5 6 7 8 val input1 = sc.parallelize(List("hello world","hi")) val lines = input1.map(line => line.split(" ")) for(line <- lines) println(line) //输出是两个List的地址 val lines_ = input1.flatMap(line => line.split(" ")) for(line_ <- lines_) println(line_) //输出是[hello world hi]
行动操作,是向驱动器程序返回结果或把结果写入外部系统的操作,会触发实际的计算: first()、count()、take()、collect()[获取整个RDD中的数据,只有想在本地处理这些数据的时候,才可以使用,因为一般情况下RDD很大]
take()函数
1 2 textFile.take(5).foreach(println)
reduce函数,接收一个函数作为参数
1 2 3 4 val input = sc.parallelize(List(1, 2, 3, 4)) val sum = input.reduce((x, y) => x + y) println(sum) //输出1-4的累加和,10
aggregate()函数,计算List的和以及List的元素个数,然后计算平均值
1 2 3 4 5 6 7 8 val input = sc.parallelize(List(1, 2, 3, 4)) val result = input.aggregate((0, 0))( (acc, value) => (acc._1 + value, acc._2 + 1), (acc1, acc2) => (acc1._1 + acc2._1, acc1._2 + acc2._2)) val avg = result._1 / result._2.toDouble println(result) println(avg)
输出
对于
1 2 val sum1 = input.aggregate((0, 0))((x, y) => (x._1 + y, x._2 + 1), (x, y) => (x._1 + y._1, x._2 + y._2))
输出(10,4)
理解
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 过程大概这样: 首先,初始值是(0,0),这个值在后面2步会用到。 然后,(acc,number) => (acc._1 + number, acc._2 + 1),number即是函数定义中的T,这里即是List中的元素。所以acc._1 + number, acc._2 + 1的过程如下。 1. 0+1, 0+1 2. 1+2, 1+1 3. 3+3, 2+1 4. 6+4, 3+1 5. 10+5, 4+1 6. 15+6, 5+1 7. 21+7, 6+1 8. 28+8, 7+1 9. 36+9, 8+1 结果即是(45,9)。这里演示的是单线程计算过程,实际Spark执行中是分布式计算,可能会把List分成多个分区,假如3个,p1(1,2,3,4),p2(5,6,7,8),p3(9),经过计算各分区的的结果(10,4),(26,4),(9,1),这样,执行(par1,par2) => (par1._1 + par2._1, par1._2 + par2._2)就是(10+26+9,4+4+1)即(45,9).再求平均值就简单了。
top()函数,可以返回RDD的前几个元素
fold()函数,和reduce()函数的功能差不多,但是需要提供初始值
1 2 3 4 5 6 7 val numbers = List(1, 2, 3, 4) println( numbers.fold(1) { (a, b) => a + b } )
输出11
转化操作和行动操作的区别:
1.转换操作 只会惰性计算这些 RDD
2.行动操作 会对 RDD 计算出一个结果,并把结果返回到驱动器程序中,或把结果存储到外部存储系统(如 HDFS)中
默认情况下,Spark 的 RDD 会在你每次对它们进行行动操作时重新计算。如果想在多个行动操作中重用同一个 RDD,可以使用 RDD.persist() 让 Spark 把这个 RDD 缓存下来
2.向Spark传递函数
在 Scala 中,我们可以把定义的内联函数、方法的引用或静态方法传递给 Spark。
我们可以把需要的字段放到一个局部变量中,来避免传递包含该字段的整个对象
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 class SearchFunctions(val query: String) { def isMatch(s: String): Boolean = { s.contains(query) } def getMatchesFunctionReference(rdd: RDD[String]): RDD[String] = { // 问题: "isMatch"表示"this.isMatch",因此我们要传递整个"this" rdd.map(isMatch) } def getMatchesFieldReference(rdd: RDD[String]): RDD[String] = { // 问题: "query"表示"this.query",因此我们要传递整个"this" rdd.map(x => x.split(query)) } def getMatchesNoReference(rdd: RDD[String]): RDD[String] = { // 安全:只把我们需要的字段拿出来放入局部变量中 val query_ = this.query rdd.map(x => x.split(query_)) } }
3.持久化(缓存)
Spark RDD 是惰性求值 的,而有时我们希望能多次使用同一个 RDD 的时候需要对RDD进行持久化
两次调用行动操作 ,每次Spark都会重新计算RDD和它的所有依赖
1 2 3 4 val result = input.map(x => x*x) println(result.count()) println(result.collect().mkString(","))
使用**persist()**来进行持久化
1 2 3 4 5 val result = input.map(x => x * x) result.persist(StorageLevel.DISK_ONLY) println(result.count()) println(result.collect().mkString(","))
如果要缓存的数据太多,内存中放不下,Spark 会自动利用最近最少使用(LRU)的缓存策略把最老的分区从内存中移除。
RDD 还有一个方法叫作 unpersist() ,调用该方法可以手动把持久化的 RDD 从缓存中移除。