MPP(Massively Parallel Processor/大规模并行处理)数据仓库,其属于OLAP(Online analytical processing,联机分析处理)的范畴
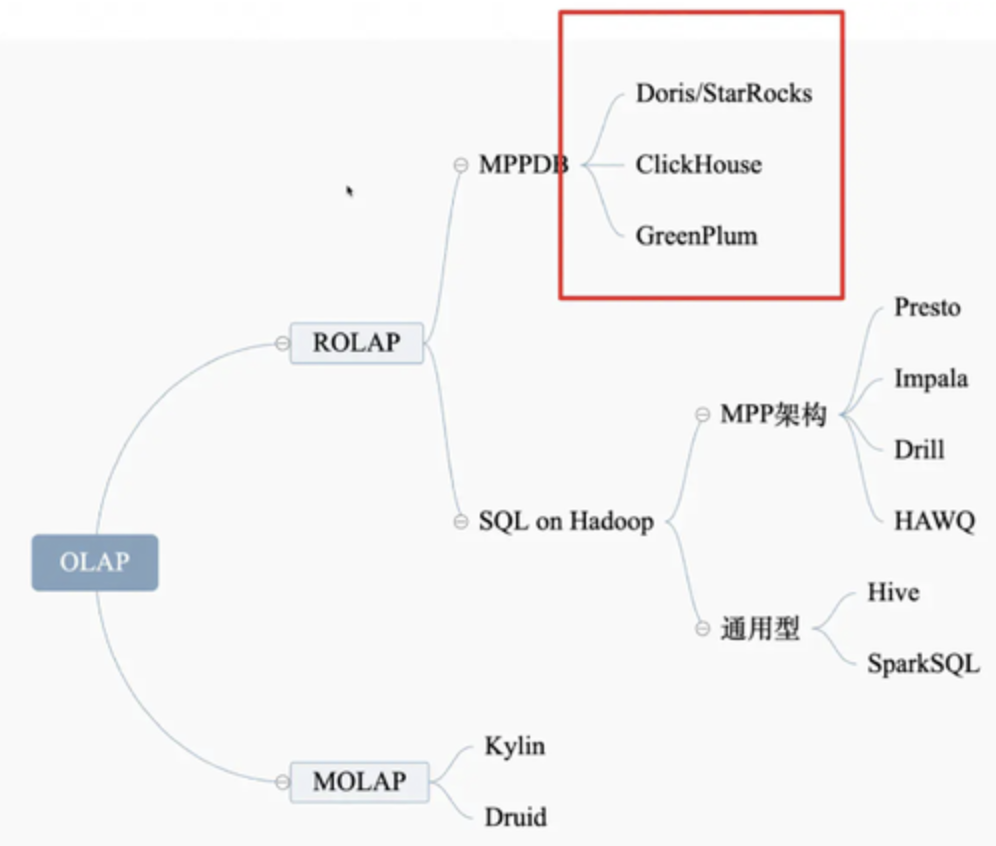
其中,ROLAP指的是(Relational OLAP/关系OLAP);MOLAP指的是(Multi-dimensional OLAP/多维OLAP),参考:主流开源OLAP引擎大比拼
ROLAP 的优点和缺点
ROLAP的典型代表是:Presto,Impala,Doris,GreenPlum,Clickhouse,Elasticsearch,Hive,Spark SQL,Flink SQL
数据写入时,ROLAP并未使用像MOLAP那样的预聚合技术;ROLAP收到Query请求时,会先解析Query,生成执行计划,扫描数据,执行关系型算子,在原始数据上做过滤(Where)、聚合(Sum, Avg, Count)、关联(Join),分组(Group By)、排序(Order By)等,最后将结算结果返回给用户,整个过程都是即时计算,没有预先聚合好的数据可供优化查询速度,拼的都是资源和算力的大小。
ROLAP 不需要进行数据预处理 ( pre-processing ),因此查询灵活,可扩展性好。这类引擎使用 MPP 架构 ( 与Hadoop相似的大型并行处理架构,可以通过扩大并发来增加计算资源 ),可以高效处理大量数据。
但是当数据量较大或 query 较为复杂时,查询性能也无法像 MOLAP 那样稳定。所有计算都是即时触发 ( 没有预处理 ),因此会耗费更多的计算资源,带来潜在的重复计算。
因此,ROLAP 适用于对查询模式不固定、查询灵活性要求高的场景。如数据分析师常用的数据分析类产品,他们往往会对数据做各种预先不能确定的分析,所以需要更高的查询灵活性。
MOLAP 的优点和缺点
MOLAP的典型代表是:Druid,Kylin,MOLAP一般会根据用户定义的数据维度、度量(也可以叫指标)在数据写入时生成预聚合数据;Query查询到来时,实际上查询的是预聚合的数据而不是原始明细数据,在查询模式相对固定的场景中,这种优化提速很明显。
MOLAP 的优点和缺点都来自于其数据预处理 ( pre-processing ) 环节。数据预处理,将原始数据按照指定的计算规则预先做聚合计算,这样避免了查询过程中出现大量的即使计算,提升了查询性能。
但是这样的预聚合处理,需要预先定义维度,会限制后期数据查询的灵活性;如果查询工作涉及新的指标,需要重新增加预处理流程,损失了灵活度,存储成本也很高;同时,这种方式不支持明细数据的查询,仅适用于聚合型查询(如:sum,avg,count)。
因此,MOLAP 适用于查询场景相对固定并且对查询性能要求非常高的场景。如广告主经常使用的广告投放报表分析。虽然这么说,但是随着Doris的发布,其被广告应用于统计以及广告主报表的场景,参考:Doris简史,Apache Doris在美团外卖数仓中的应用实践,日增百亿数据,查询结果秒出, Apache Doris 在 360 商业化的统一 OLAP 应用实践,Apache Doris产品调研报告
