24 Mar 2020 01:55:05,055 WARN [PollableSourceRunner-KafkaSource-source1] (org.apache.kafka.clients.consumer.internals.Fetcher.handleFetchResponse:600) - Unknown error fetching data for topic-partition xxxx-17
2020-03-24 15:57:60,265 ERROR kafka.server.ReplicaManager: [ReplicaManager broker=xxx] Error processing fetch operatio n on partition xxx-17, offset 4095495430 org.apache.kafka.common.KafkaException: java.io.EOFException: Failed to read `log header` from file channel `sun.nio.ch .FileChannelImpl@73e125b5`. Expected to read 18 bytes, but reached end of file after reading 0 bytes. Started read from position 2147454346. at org.apache.kafka.common.record.RecordBatchIterator.makeNext(RecordBatchIterator.java:40) at org.apache.kafka.common.record.RecordBatchIterator.makeNext(RecordBatchIterator.java:24) at org.apache.kafka.common.utils.AbstractIterator.maybeComputeNext(AbstractIterator.java:79) at org.apache.kafka.common.utils.AbstractIterator.hasNext(AbstractIterator.java:45) at org.apache.kafka.common.record.FileRecords.searchForOffsetWithSize(FileRecords.java:287) at kafka.log.LogSegment.translateOffset(LogSegment.scala:174) at kafka.log.LogSegment.read(LogSegment.scala:226) at kafka.log.Log$$anonfun$read$2.apply(Log.scala:1002) at kafka.log.Log$$anonfun$read$2.apply(Log.scala:958) at kafka.log.Log.maybeHandleIOException(Log.scala:1669) at kafka.log.Log.read(Log.scala:958) at kafka.server.ReplicaManager.kafka$server$ReplicaManager$$read$1(ReplicaManager.scala:900) at kafka.server.ReplicaManager$$anonfun$readFromLocalLog$1.apply(ReplicaManager.scala:962) at kafka.server.ReplicaManager$$anonfun$readFromLocalLog$1.apply(ReplicaManager.scala:961) at scala.collection.mutable.ResizableArray$class.foreach(ResizableArray.scala:59) at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:48) at kafka.server.ReplicaManager.readFromLocalLog(ReplicaManager.scala:961) at kafka.server.ReplicaManager.readFromLog$1(ReplicaManager.scala:790) at kafka.server.ReplicaManager.fetchMessages(ReplicaManager.scala:803) at kafka.server.KafkaApis.handleFetchRequest(KafkaApis.scala:601) at kafka.server.KafkaApis.handle(KafkaApis.scala:99) at kafka.server.KafkaRequestHandler.run(KafkaRequestHandler.scala:65) at java.lang.Thread.run(Thread.java:748)
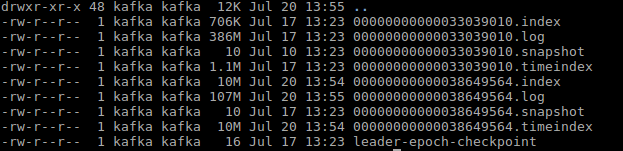
/opt/cloudera/parcels/KAFKA/bin/kafka-run-class kafka.tools.DumpLogSegments --files ./00000000000000000187.timeindex 20/07/19 18:47:31 INFO utils.Log4jControllerRegistration$: Registered kafka:type=kafka.Log4jController MBean Dumping ./00000000000000000187.timeindex timestamp: 0 offset: 187 Found timestamp mismatch in :/var/local/kafka/data/test_topic-0/./00000000000000000187.timeindex Index timestamp: 0, log timestamp: 1595149737820 Index timestamp: 0, log timestamp: 1595149737820 Found out of order timestamp in :/var/local/kafka/data/test_topic-0/./00000000000000000187.timeindex Index timestamp: 0, Previously indexed timestamp: 0