<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. -->
<!-- Put site-specific property overrides in this file. -->
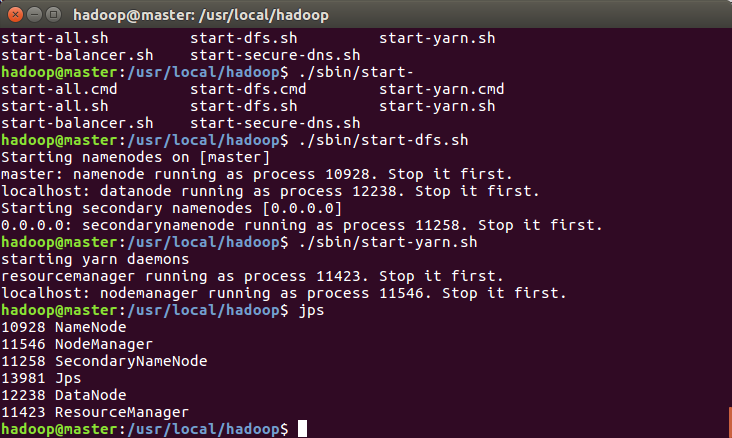
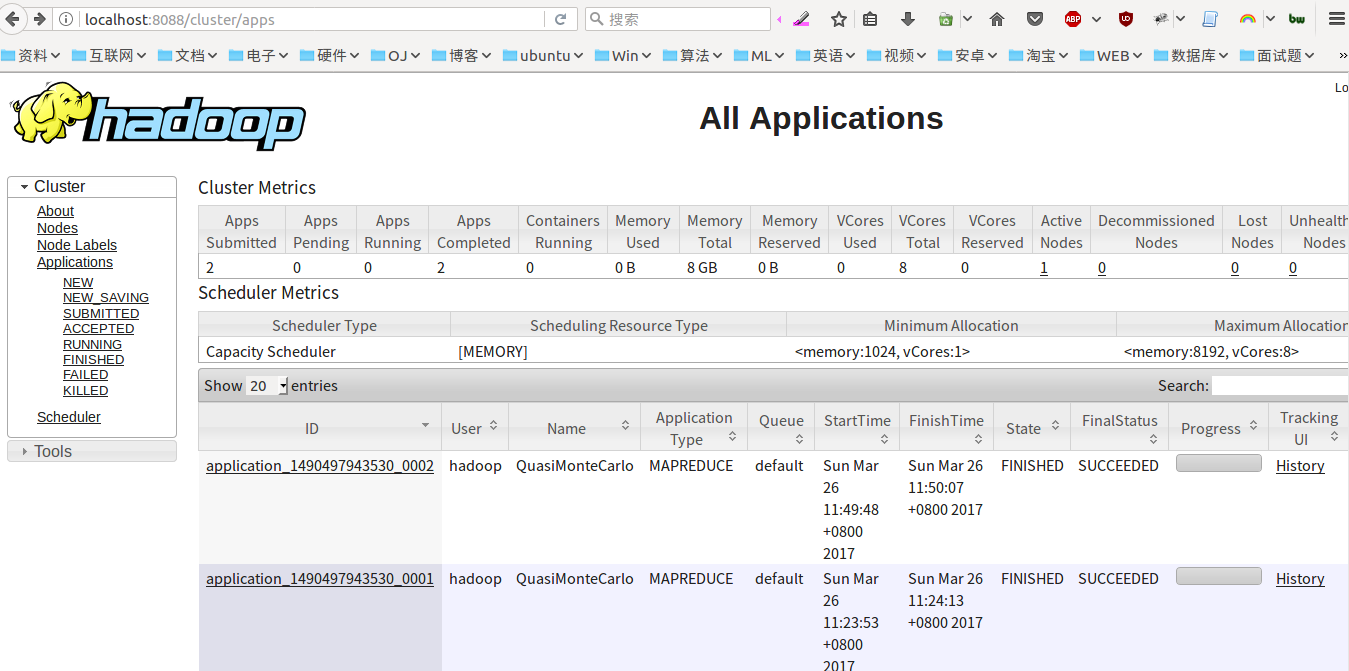
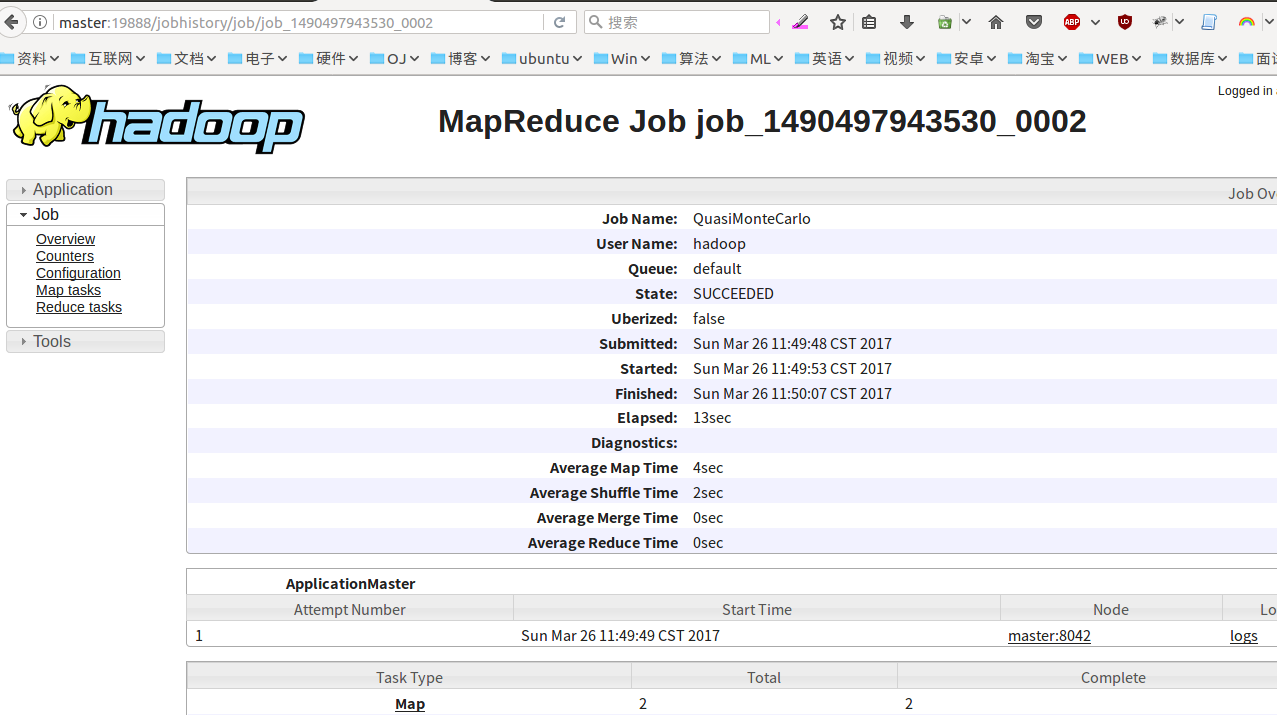
Number of Maps = 2 Samples per Map = 5 Wrote input for Map #0 Wrote input for Map #1 Starting Job 17/03/26 11:49:47 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032 17/03/26 11:49:47 INFO input.FileInputFormat: Total input paths to process : 2 17/03/26 11:49:47 INFO mapreduce.JobSubmitter: number of splits:2 17/03/26 11:49:48 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1490497943530_0002 17/03/26 11:49:48 INFO impl.YarnClientImpl: Submitted application application_1490497943530_0002 17/03/26 11:49:48 INFO mapreduce.Job: The url to track the job: http://master:8088/proxy/application_1490497943530_0002/ 17/03/26 11:49:48 INFO mapreduce.Job: Running job: job_1490497943530_0002 17/03/26 11:49:55 INFO mapreduce.Job: Job job_1490497943530_0002 running in uber mode : false 17/03/26 11:49:55 INFO mapreduce.Job: map 0% reduce 0% 17/03/26 11:50:02 INFO mapreduce.Job: map 100% reduce 0% 17/03/26 11:50:08 INFO mapreduce.Job: map 100% reduce 100% 17/03/26 11:50:08 INFO mapreduce.Job: Job job_1490497943530_0002 completed successfully 17/03/26 11:50:08 INFO mapreduce.Job: Counters: 49 File System Counters FILE: Number of bytes read=50 FILE: Number of bytes written=353898 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=524 HDFS: Number of bytes written=215 HDFS: Number of read operations=11 HDFS: Number of large read operations=0 HDFS: Number of write operations=3 Job Counters Launched map tasks=2 Launched reduce tasks=1 Data-local map tasks=2 Total time spent by all maps in occupied slots (ms)=9536 Total time spent by all reduces in occupied slots (ms)=3259 Total time spent by all map tasks (ms)=9536 Total time spent by all reduce tasks (ms)=3259 Total vcore-milliseconds taken by all map tasks=9536 Total vcore-milliseconds taken by all reduce tasks=3259 Total megabyte-milliseconds taken by all map tasks=9764864 Total megabyte-milliseconds taken by all reduce tasks=3337216 Map-Reduce Framework Map input records=2 Map output records=4 Map output bytes=36 Map output materialized bytes=56 Input split bytes=288 Combine input records=0 Combine output records=0 Reduce input groups=2 Reduce shuffle bytes=56 Reduce input records=4 Reduce output records=0 Spilled Records=8 Shuffled Maps =2 Failed Shuffles=0 Merged Map outputs=2 GC time elapsed (ms)=319 CPU time spent (ms)=2570 Physical memory (bytes) snapshot=719585280 Virtual memory (bytes) snapshot=5746872320 Total committed heap usage (bytes)=513802240 Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 File Input Format Counters Bytes Read=236 File Output Format Counters Bytes Written=97 Job Finished in 21.472 seconds Estimated value of Pi is 3.60000000000000000000