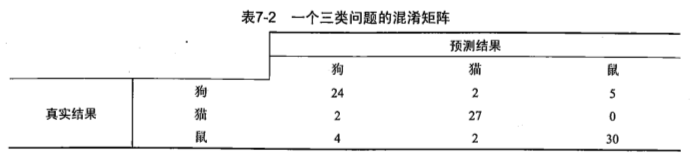
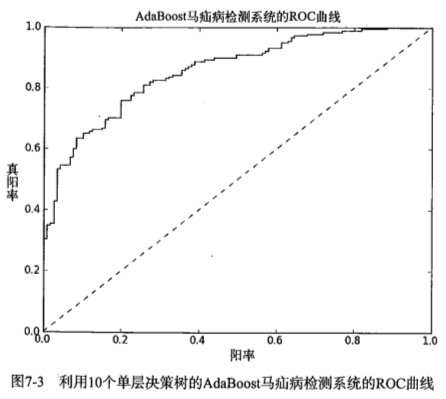
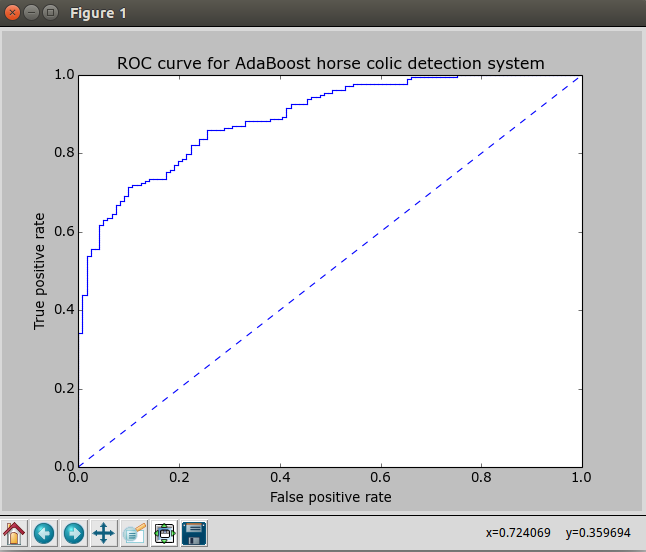
def plotROC(predStrengths, classLabels): #ROC曲线的绘制及AUC计算函数 import matplotlib.pyplot as plt cur = (1.0,1.0) #cursor ySum = 0.0 #variable to calculate AUC numPosClas = sum(array(classLabels)==1.0) yStep = 1/float(numPosClas); xStep = 1/float(len(classLabels)-numPosClas) sortedIndicies = predStrengths.argsort()#get sorted index, it's reverse fig = plt.figure() fig.clf() ax = plt.subplot(111) #loop through all the values, drawing a line segment at each point for index in sortedIndicies.tolist()[0]: if classLabels[index] == 1.0: delX = 0; delY = yStep; else: delX = xStep; delY = 0; ySum += cur[1] #draw line from cur to (cur[0]-delX,cur[1]-delY) ax.plot([cur[0],cur[0]-delX],[cur[1],cur[1]-delY], c='b') cur = (cur[0]-delX,cur[1]-delY) ax.plot([0,1],[0,1],'b--') plt.xlabel('False positive rate'); plt.ylabel('True positive rate') plt.title('ROC curve for AdaBoost horse colic detection system') ax.axis([0,1,0,1]) plt.show() print "the Area Under the Curve is: ",ySum*xStep