参考
1 | https://dzone.com/articles/elasticsearch5-how-to-build-a-plugin-and-add-a-lis |
Es的插件主要有如下几种类型,参考
1 | https://github.com/elastic/elasticsearch/tree/master/server/src/main/java/org/elasticsearch/plugins |
参考
1 | https://dzone.com/articles/elasticsearch5-how-to-build-a-plugin-and-add-a-lis |
Es的插件主要有如下几种类型,参考
1 | https://github.com/elastic/elasticsearch/tree/master/server/src/main/java/org/elasticsearch/plugins |
在Airbnb的rowkey设计案例中,使用了hash法避免了写入热点问题,其中

Event_key标识了一条日志的唯一性,用于将来自Kafka的日志数据进行去重;
Shard_id是将Event_key进行hash(可以参考es的路由哈希算法Hashing.murmur3_128)之后,对Shard_num进行取余后的结果,Shard_num感觉应该是当前hbase表region server的总数,由于airbnb在hbase中存储的是实时日志数据,并开启了Hbase的TTL,所以当前hbase表中的数据总量应该是可预测的,即region server数量不会无限增加
Shard_key应该就是当前业务的region_start_keys+shard_id,比如当前业务分配的前缀为00000,同时规划了100个table regions给这个业务,即00-99,那么Shard_key的范围就是0000000-0000099
rowkey就是Shard_key.Event_key,比如0000000.air_events.canaryevent.016230-a3db-434e
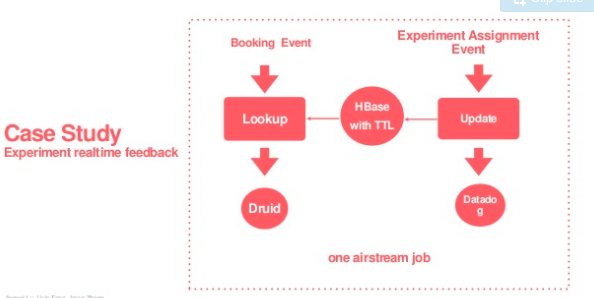
参考:
Reliable and Scalable Data Ingestion at Airbnb
Airbnb软件工程师丁辰 - Airbnb的Streaming ETL
1.rowkey长度原则:rowkey是一个二进制码流,可以是任意字符串,最大长度
在美团点评的文章中,介绍了HiveSQL转化为MapReduce的过程
1 | 1、Antlr定义SQL的语法规则,完成SQL词法,语法解析,将SQL转化为抽象语法树AST Tree |
但是不是所有的SQL都有必要转换为MR来执行,比如
1 | select * from xx.xx limit 1 |
Hive只需要直接读取文件,并传输到控制台即可
前置条件是安装ik分词,请参考
1.在ik分词的config下添加词库文件
1 | ~/software/apache/elasticsearch-6.2.4/config/analysis-ik$ ls | grep mydic.dic |
内容为
1 | 我给祖国献石油 |
2.配置词库路径,编辑IKAnalyzer.cfg.xml配置文件,添加新增的词库
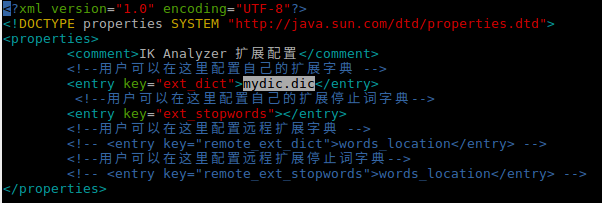
3.重启es
4.测试
data.json
1 | { |
添加之后的ik分词结果
1 | curl -H 'Content-Type: application/json' http://localhost:9200/_analyze?pretty=true -d@data.json |
添加之后的ik分词结果,分词结果的tokens中增加了 “我给祖国献石油”
1 | curl -H 'Content-Type: application/json' http://localhost:9200/_analyze?pretty=true -d@data.json |
Flink支持用户自定义 Functions,方法有2个
Ref
1 | https://ci.apache.org/projects/flink/flink-docs-release-1.12/zh/dev/user_defined_functions.html |
1 | class MyMapFunction implements MapFunction<String, Integer> { |
1 | class MyMapFunction extends RichMapFunction<String, Integer> { |
Flink有3中运行模式,分别是STREAMING,BATCH和AUTOMATIC
Ref
1 | https://ci.apache.org/projects/flink/flink-docs-release-1.12/zh/dev/datastream_execution_mode.html |
1.STREAMING运行模式 是DataStream默认的运行模式
2.BATCH运行模式 也可以在DataStream API上运行
3.AUTOMATIC运行模式 是让系统根据source类型自动选择运行模式
可以通过命令行来配置运行模式
1 | bin/flink run -Dexecution.runtime-mode=BATCH examples/streaming/WordCount.jar |
也可以在代码中配置
1 | StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); |
Flink中的DataSet任务用于实现data sets的转换,data set通常是固定的数据源,比如可读文件,或者本地集合等。
Ref
1 | https://ci.apache.org/projects/flink/flink-docs-release-1.12/zh/dev/batch/ |
Flink有以下几种Environment
1 | ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment(); |
2.流处理Environment,StreamExecutionEnvironment
1 | StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); |
1 | ExecutionEnvironment env = LocalEnvironment.getExecutionEnvironment(); |
1 | ExecutionEnvironment env = CollectionEnvironment.getExecutionEnvironment(); |
Ref
1 | https://www.yuque.com/cuteximi/base/flink-02?language=en-us |
创建Environment的方法
在Flink任务中,需要加载外置配置参数到任务中,在Flink的开发文档中介绍了,Flink提供了一个名为 ParameterTool 的工具来解决这个问题
Flink开发文档:
1 | https://github.com/apache/flink/blob/master/docs/dev/application_parameters.zh.md |
其引入配置的方式有3种:
1.
